
Regressieanalyse is een benadering voor het identificeren en analyseren van het verband tussen een of meer onafhankelijke variabelen en een afhankelijke variabele. Deze methode wordt veel gebruikt in verschillende disciplines, waaronder gezondheidszorg, sociale wetenschappen, techniek, economie en het bedrijfsleven. Je kunt regressieanalyse gebruiken om de fundamentele relaties in gegevens te onderzoeken en voorspellende modellen te ontwikkelen die je helpen om weloverwogen beslissingen te nemen.
Dit artikel geeft je een uitgebreid overzicht van regressieanalyse, inclusief hoe het werkt, een eenvoudig te begrijpen voorbeeld en het legt uit hoe het verschilt van correlatieanalyse.
Wat is regressieanalyse?
Regressieanalyse is een statistische methode voor het identificeren en kwantificeren van het verband tussen een afhankelijke variabele en een of meer onafhankelijke variabelen. In een notendop helpt het je te begrijpen hoe veranderingen in een of meer onafhankelijke variabelen samenhangen met veranderingen in de afhankelijke variabele.
Om regressieanalyse goed te begrijpen, moet je eerst de volgende termen begrijpen:
- Afhankelijke variabele: Dit is de variabele die je wilt analyseren of voorspellen. Het is de uitkomstvariabele die je probeert te begrijpen en te verklaren.
- Onafhankelijke variabelen: Dit zijn de variabelen waarvan je denkt dat ze een effect hebben op de afhankelijke variabele. Ze worden vaak de voorspellende variabelen genoemd, omdat ze worden gebruikt om veranderingen in de afhankelijke variabele te voorspellen of te verklaren.
Regressieanalyse kan worden gebruikt voor een reeks omstandigheden, waaronder het voorspellen van toekomstige waarden van de afhankelijke variabele, het begrijpen van het effect van onafhankelijke variabelen op de afhankelijke variabele en het vinden van uitschieters of ongebruikelijke gebeurtenissen in gegevensverzameling.
Regressieanalyse kan worden ingedeeld in verschillende typen, waaronder enkelvoudige lineaire regressie, logistische regressie, polynomiale regressie en meervoudige regressie. Het geschikte regressiemodel wordt bepaald door de aard van de gegevens en het onderwerp van het onderzoek.
Hoe werkt regressieanalyse?
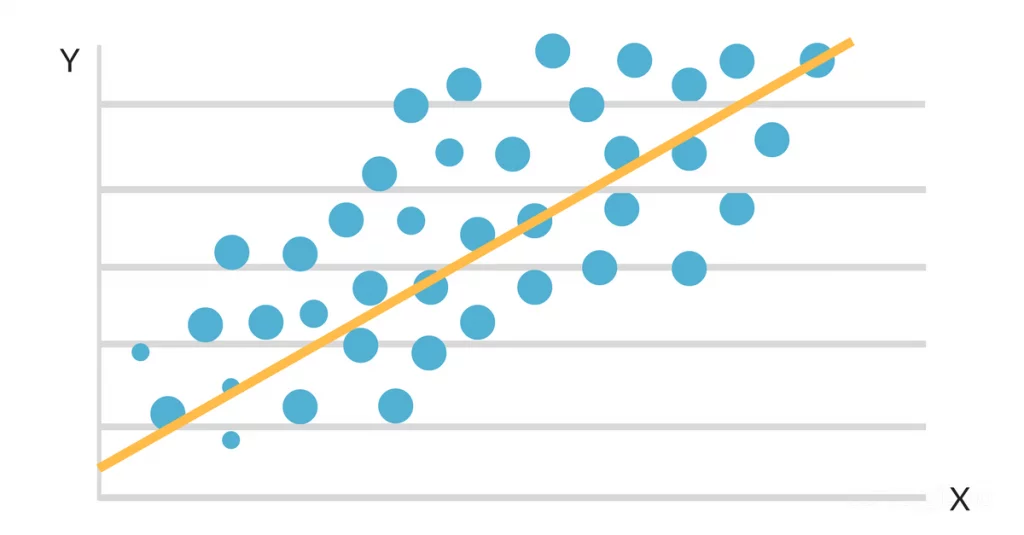
Het doel van regressieanalyse is het identificeren van de best passende lijn of curve die het verband weergeeft tussen de onafhankelijke variabelen en de afhankelijke variabele. Deze best passende lijn of curve wordt gegenereerd met behulp van statistische methoden die de verschillen tussen de verwachte en werkelijke waarden in de gegevensverzameling verkleinen.
Hier zijn de formules voor de twee meest voorkomende soorten regressieanalyse:
Enkelvoudige lineaire regressie
In eenvoudige lineaire regressie gebruik je een best passende lijn om de relatie tussen twee variabelen weer te geven: de onafhankelijke variabele (x) en de afhankelijke variabele (y).
De best passende lijn kan worden voorgesteld door de vergelijking: y = a + bx.
Hierbij is a het intercept en b de helling van de lijn. Om de helling te berekenen, gebruik je de formule: b = (nΣ(xy) - ΣxΣy) / (nΣ(x2) - (Σx)2), waarbij n het aantal waarnemingen is, Σxy de som van het product van x en y, Σx en Σy de som van respectievelijk x en y, en Σ(x2) is de som van de kwadraten van x.
Om het intercept te berekenen, gebruik je de formule: a = (Σy - bΣx) / n.
Meervoudige regressie
Meervoudige lineaire regressie:
De formule voor de vergelijking van het meervoudige lineaire regressiemodel is:
y = b0 + b1x1 + b2x2 + ... + bnxn
waarbij y de afhankelijke variabele is, x1, x2, ..., xn de onafhankelijke variabelen zijn en b0, b1, b2, ..., bn de coëfficiënten van de onafhankelijke variabelen zijn.
De formule voor het schatten van de coëfficiënten met behulp van gewone kleinste kwadraten is:
β = (X'X)(-1)X'y
waarbij β een kolomvector van coëfficiënten is, X de ontwerpmatrix van onafhankelijke variabelen is, X' de transpositie van X is en y de vector van waarnemingen van de afhankelijke variabele is.
Voorbeeld regressieanalyse
Stel dat je het verband wilt onderzoeken tussen iemands cijfergemiddelde (GPA) en het aantal uren dat hij of zij per week studeert. Je verzamelt informatie van een aantal studenten, waaronder hun aantal studie-uren en hun cijfergemiddelde.
Gebruik vervolgens de regressieanalyse om te zien of er een lineair verband is tussen beide variabelen en zo ja, dan kun je een model bouwen dat het GPA van een student voorspelt op basis van het aantal uren dat ze per week studeren.

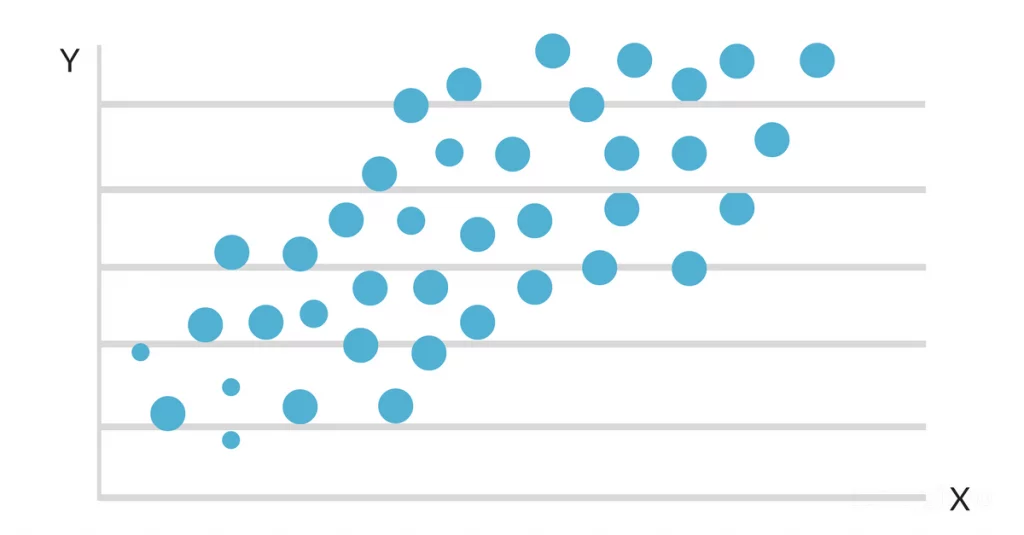
Wanneer de gegevens worden uitgezet op een scatter map, blijkt dat er een gunstig lineair verband is tussen studie-uren en GPA. De helling en het intercept van de best passende lijn worden dan geschat met behulp van een eenvoudig lineair regressiemodel. De uiteindelijke oplossing zou er als volgt uit kunnen zien:
GPA = 2,0 + 0,3 (bestudeerde uren per week)
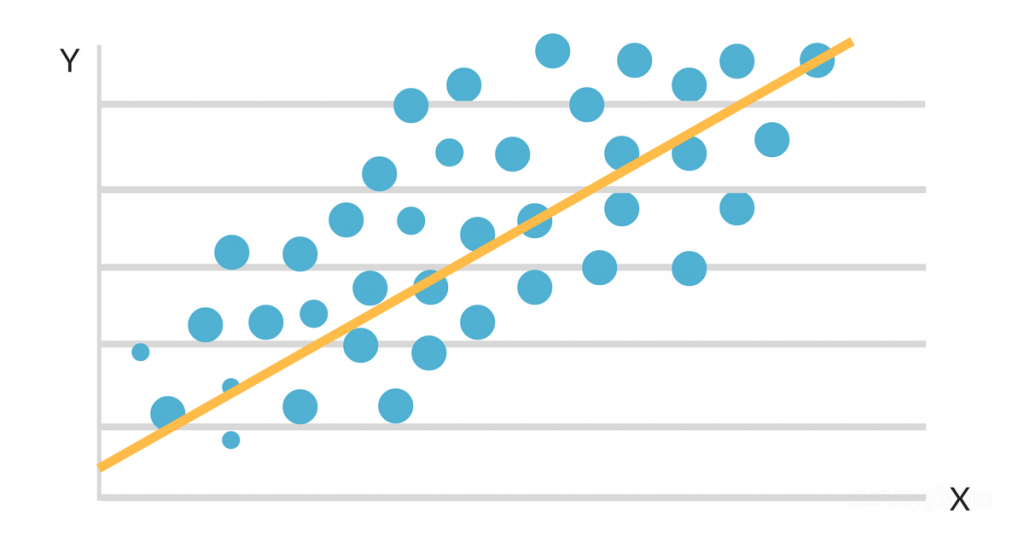
Deze vergelijking stelt dat voor elk extra uur studie per week, de GPA van een student met 0,3 punt stijgt, waarbij al het andere gelijk blijft. Dit algoritme kan worden gebruikt om de GPA van een student te voorspellen op basis van het aantal uren dat hij of zij per week studeert, maar ook om te bepalen welke studenten het risico lopen om ondermaats te presteren op basis van hun studieroutines.
Gebruikmakend van de gegevens uit het voorbeeld, zijn de waarden voor b en a zijn als volgt:
n = 10 (het aantal waarnemingen)
Σx = 30 (de som van de studie-uren)
Σy = 25 (de som van de GPA's)
Σxy = 149 (de som van het product van studie-uren en GPA's)
Σ(x)2 = 102 (de som van de kwadraten van studie-uren)
Bereken met deze waarden b als:
b = (nΣ(xy) - ΣxΣy) / (nΣ(x2) - (Σx)2)
= (10 * 149 – 30 * 25) / (10 * 102 – 302)
= 0.3
En bereken a als:
a = (Σy - bΣx) / n
= (25 – 0.3 * 30) / 10
= 2.0
Daarom is de vergelijking van de best passende lijn:
GPA = 2,0 + 0,3 (bestudeerde uren per week)
Wat is het verschil tussen correlatie en regressie?
Zowel correlatie als regressie zijn statistische methoden om het verband tussen twee variabelen te onderzoeken. Ze dienen verschillende doelen en leveren verschillende soorten informatie op.
Correlatie is een maat voor de sterkte en het verloop van een verband tussen twee variabelen. De correlatie loopt van -1 tot +1, waarbij -1 staat voor een perfecte negatieve correlatie, 0 voor geen correlatie en +1 voor een perfecte positieve correlatie. Correlatie geeft de mate aan waarin twee variabelen met elkaar verbonden zijn, maar het geeft geen oorzaak of voorspelbaarheid aan.
Regressie daarentegen is een methode om het verband tussen twee variabelen te modelleren, meestal om een variabele te voorspellen of te verklaren op basis van de andere. Regressieanalyse kan schattingen opleveren van de grootte en richting van de relatie, evenals statistische significantietests, betrouwbaarheidsbereiken en voorspellingen van toekomstige resultaten.
Jouw creaties, klaar binnen enkele minuten
Mind the Graph is een online platform dat je een uitgebreide bibliotheek met wetenschappelijke illustraties en infografische ontwerpen biedt die je eenvoudig kunt aanpassen aan jouw unieke behoeften. Maak professioneel ogende grafieken, posters en grafische samenvattingen in enkele minuten met behulp van een drag-and-drop interface en een breed scala aan tools en functies.



{kind=link}
{kind=link}

Abonneer u op onze nieuwsbrief
Exclusieve inhoud van hoge kwaliteit over effectieve visuele
communicatie in de wetenschap.