
Analiza regresji to metoda identyfikacji i analizy związku między jedną lub większą liczbą zmiennych niezależnych a zmienną zależną. Metoda ta jest szeroko stosowana w różnych dyscyplinach, w tym w opiece zdrowotnej, naukach społecznych, inżynierii, ekonomii i biznesie. Analizę regresji można wykorzystać do zbadania podstawowych zależności w danych i opracowania modeli predykcyjnych, które pomogą w podejmowaniu świadomych decyzji.
Ten artykuł zawiera kompleksowy przegląd analizy regresji, w tym sposób jej działania, łatwy do zrozumienia przykład i wyjaśnia, czym różni się ona od analizy korelacji.
Czym jest analiza regresji?
Analiza regresji to metoda statystyczna służąca do identyfikacji i ilościowego określenia związku między zmienną zależną a jedną lub większą liczbą zmiennych niezależnych. W skrócie, pomaga ona zrozumieć, w jaki sposób zmiany jednej lub więcej zmiennych niezależnych są powiązane ze zmianami zmiennej zależnej.
Aby dokładnie zrozumieć analizę regresji, należy najpierw zrozumieć następujące pojęcia:
- Zmienna zależna: Jest to zmienna, którą chcesz przeanalizować lub przewidzieć. Jest to zmienna wynikowa, którą próbujesz zrozumieć i wyjaśnić.
- Zmienne niezależne: Są to zmienne, które Twoim zdaniem mają wpływ na zmienną zależną. Są one często określane jako zmienne predykcyjne, ponieważ służą do przewidywania lub wyjaśniania zmian w zmiennej zależnej.
Analiza regresji może być wykorzystywana w różnych okolicznościach, w tym do przewidywania przyszłych wartości zmiennej zależnej, zrozumienia wpływu zmiennych niezależnych na zmienną zależną oraz znajdowania wartości odstających lub nietypowych zdarzeń w gromadzeniu danych.
Analizę regresji można podzielić na kilka typów, w tym pojedynczą regresję liniową, regresję logistyczną, regresję wielomianową i regresję wielokrotną. Odpowiedni model regresji zależy od charakteru danych i rozważanego przedmiotu badania.
Jak działa analiza regresji?
Celem analizy regresji jest zidentyfikowanie najlepiej dopasowanej linii lub krzywej, która odzwierciedla związek między zmiennymi niezależnymi a zmienną zależną. Ta najlepiej dopasowana linia lub krzywa jest generowana przy użyciu metod statystycznych, które zmniejszają rozbieżności między oczekiwanymi i rzeczywistymi wartościami w zbiorze danych.
Oto wzory dla dwóch najpopularniejszych typów analizy regresji:
Pojedyncza regresja liniowa
W prostej regresji liniowej używasz linii najlepszego dopasowania, aby pokazać związek między dwiema zmiennymi: zmienną niezależną (x) i zmienną zależną (y).
Linia najlepszego dopasowania może być reprezentowana przez równanie: y = a + bx.
W tym przypadku a to punkt przecięcia, a b to nachylenie linii. Aby obliczyć nachylenie, należy użyć wzoru: b = (nΣ(xy) - ΣxΣy) / (nΣ(x2) - (Σx)2), gdzie n to liczba obserwacji, Σxy to suma iloczynów x i y, Σx i Σy to odpowiednio sumy x i y, a Σ(x2) jest sumą kwadratów x.
Aby obliczyć punkt przecięcia, należy użyć wzoru: a = (Σy - bΣx) / n.
Regresja wielokrotna
Wielokrotna regresja liniowa:
Wzór na równanie modelu wielokrotnej regresji liniowej jest następujący:
y = b0 + b1x1 + b2x2 + ... + bnxn
gdzie y jest zmienną zależną, x1, x2, ..., xn są zmiennymi niezależnymi, a b0, b1, b2, ..., bn są współczynnikami zmiennych niezależnych.
Wzór na oszacowanie współczynników przy użyciu zwykłych najmniejszych kwadratów jest następujący:
β = (X'X)(-1)X'y
gdzie β jest wektorem kolumnowym współczynników, X jest macierzą projektową zmiennych niezależnych, X' jest transpozycją X, a y jest wektorem obserwacji zmiennej zależnej.
Przykład analizy regresji
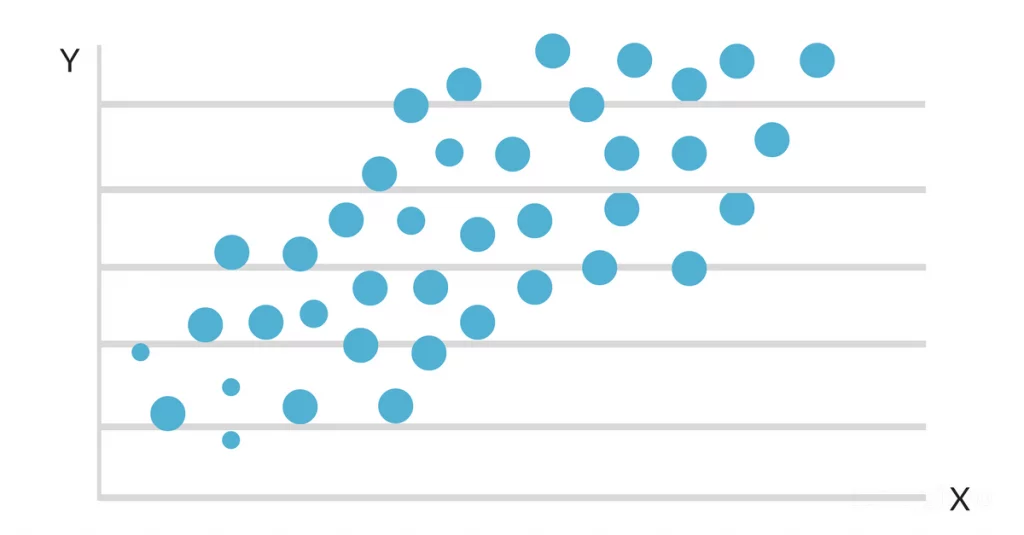
Załóżmy, że chcesz zbadać związek między średnią ocen (GPA) danej osoby a liczbą godzin nauki w tygodniu. Zbierasz informacje od grupy studentów, w tym ich liczbę godzin nauki i średnią ocen.
Następnie użyj analizy regresji, aby sprawdzić, czy istnieje liniowy związek między obiema zmiennymi, a jeśli tak, możesz zbudować model, który przewiduje GPA studenta na podstawie liczby godzin nauki w tygodniu.

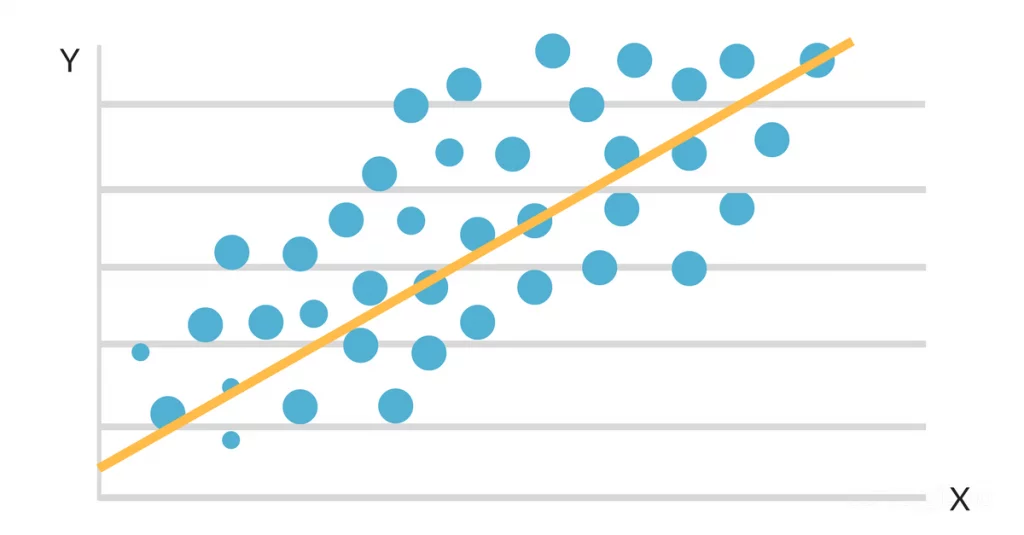
Gdy dane są wykreślane na mapie rozrzutu, okazuje się, że istnieje korzystny liniowy związek między godzinami nauki a GPA. Nachylenie i punkt przecięcia linii najlepszego dopasowania są następnie szacowane przy użyciu prostego modelu regresji liniowej. Ostateczne rozwiązanie może wyglądać następująco:
GPA = 2,0 + 0,3 (liczba godzin nauki tygodniowo)
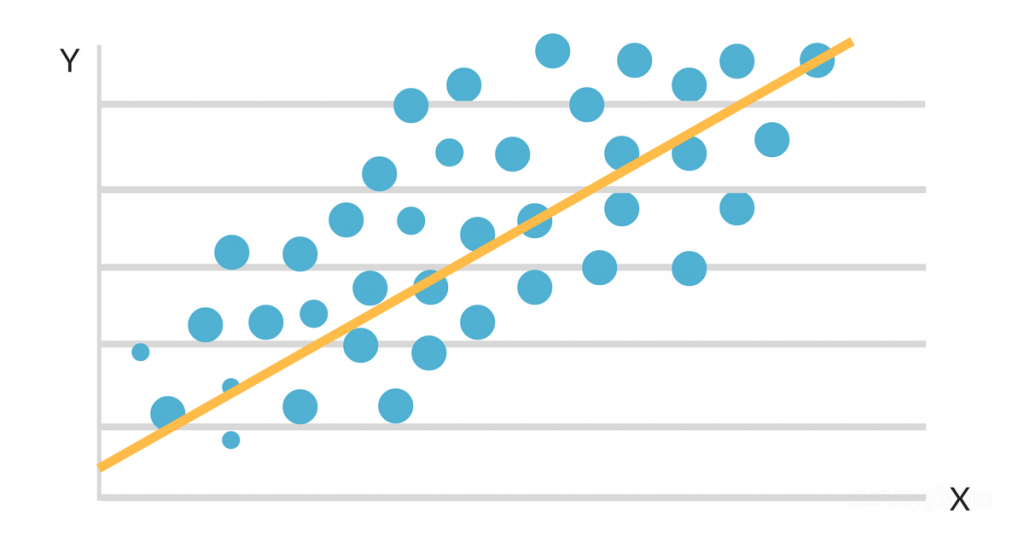
Równanie to mówi, że za każdą dodatkową godzinę nauki w tygodniu, GPA studenta wzrośnie o 0,3 punktu, przy czym wszystko inne jest równoważne. Algorytm ten można wykorzystać do prognozowania GPA studenta na podstawie liczby godzin nauki w tygodniu, a także do określenia, którzy studenci są zagrożeni słabszymi wynikami na podstawie ich rutyny nauki.
Korzystając z danych z przykładu, wartości dla b oraz a są następujące:
n = 10 (liczba obserwacji)
Σx = 30 (suma godzin nauki)
Σy = 25 (suma GPA)
Σxy = 149 (suma iloczynu godzin nauki i GPA)
Σ(x)2 = 102 (suma kwadratów godzin nauki)
Korzystając z tych wartości, oblicz b jako:
b = (nΣ(xy) - ΣxΣy) / (nΣ(x2) - (Σx)2)
= (10 * 149 – 30 * 25) / (10 * 102 – 302)
= 0.3
I obliczyć a jako:
a = (Σy - bΣx) / n
= (25 – 0.3 * 30) / 10
= 2.0
Dlatego równanie linii najlepszego dopasowania wynosi:
GPA = 2,0 + 0,3 (liczba godzin nauki tygodniowo)
Jaka jest różnica między korelacją a regresją?
Zarówno korelacja, jak i regresja są metodami statystycznymi służącymi do badania związku między dwiema zmiennymi. Służą one różnym celom i dostarczają różnych rodzajów informacji.
Korelacja jest miarą siły i przebiegu związku między dwiema zmiennymi. Przyjmuje ona wartości od -1 do +1, gdzie -1 oznacza idealną korelację ujemną, 0 oznacza brak korelacji, a +1 oznacza idealną korelację dodatnią. Korelacja wskazuje stopień, w jakim dwie zmienne są ze sobą powiązane, ale nie wskazuje przyczyny ani przewidywalności.
Z drugiej strony, regresja jest metodą modelowania związku między dwiema zmiennymi, zazwyczaj w celu prognozowania lub wyjaśniania jednej zmiennej na podstawie drugiej. Analiza regresji może zapewnić oszacowanie wielkości i kierunku związku, a także testy istotności statystycznej, przedziały ufności i prognozy przyszłych wyników.
Twoje kreacje gotowe w ciągu kilku minut
Mind the Graph to platforma internetowa oferująca obszerną bibliotekę ilustracji naukowych i infografik, które można łatwo modyfikować, aby spełnić swoje unikalne potrzeby. Pozwala ona tworzyć profesjonalnie wyglądające wykresy, plakaty i streszczenia graficzne w ciągu kilku minut za pomocą interfejsu "przeciągnij i upuść" oraz szerokiej gamy narzędzi i funkcji.



{kind=link}
{kind=link}

Zapisz się do naszego newslettera
Ekskluzywne, wysokiej jakości treści na temat skutecznych efektów wizualnych
komunikacja w nauce.