
Die Regressionsanalyse ist ein Ansatz zur Ermittlung und Analyse des Zusammenhangs zwischen einer oder mehreren unabhängigen Variablen und einer abhängigen Variablen. Diese Methode wird in einer Vielzahl von Disziplinen eingesetzt, unter anderem im Gesundheitswesen, in den Sozialwissenschaften, im Ingenieurwesen, in der Wirtschaft und im Geschäftsleben. Mit der Regressionsanalyse können Sie die grundlegenden Beziehungen in Daten untersuchen und Vorhersagemodelle entwickeln, die Ihnen helfen, fundierte Entscheidungen zu treffen.
In diesem Artikel erhalten Sie einen umfassenden Überblick über die Regressionsanalyse, einschließlich ihrer Funktionsweise und eines leicht verständlichen Beispiels, und es wird erläutert, wie sie sich von der Korrelationsanalyse unterscheidet.
Was ist eine Regressionsanalyse?
Die Regressionsanalyse ist eine statistische Methode zur Identifizierung und Quantifizierung des Zusammenhangs zwischen einer abhängigen Variablen und einer oder mehreren unabhängigen Variablen. Kurz gesagt, sie hilft Ihnen zu verstehen, wie Änderungen einer oder mehrerer unabhängiger Variablen mit Änderungen der abhängigen Variable zusammenhängen.
Um ein gründliches Verständnis der Regressionsanalyse zu erlangen, müssen Sie zunächst die folgenden Begriffe verstehen:
- Abhängige Variable: Dies ist die Variable, die Sie analysieren oder vorhersagen möchten. Es ist die Ergebnisvariable, die Sie zu verstehen und zu erklären versuchen.
- Unabhängige Variablen: Dies sind die Variablen, von denen Sie glauben, dass sie einen Einfluss auf die abhängige Variable haben. Sie werden oft als Prädiktorvariablen bezeichnet, da sie zur Vorhersage oder Erklärung von Veränderungen in der abhängigen Variable verwendet werden.
Die Regressionsanalyse kann unter verschiedenen Umständen eingesetzt werden, z. B. zur Vorhersage künftiger Werte der abhängigen Variable, zum Verständnis der Auswirkungen unabhängiger Variablen auf die abhängige Variable und zur Ermittlung von Ausreißern oder ungewöhnlichen Vorkommnissen bei der Datenerfassung.
Die Regressionsanalyse lässt sich in mehrere Arten einteilen, darunter die einfache lineare Regression, die logistische Regression, die polynomiale Regression und die multiple Regression. Das geeignete Regressionsmodell wird durch die Art der Daten und den Untersuchungsgegenstand bestimmt.
Wie funktioniert die Regressionsanalyse?
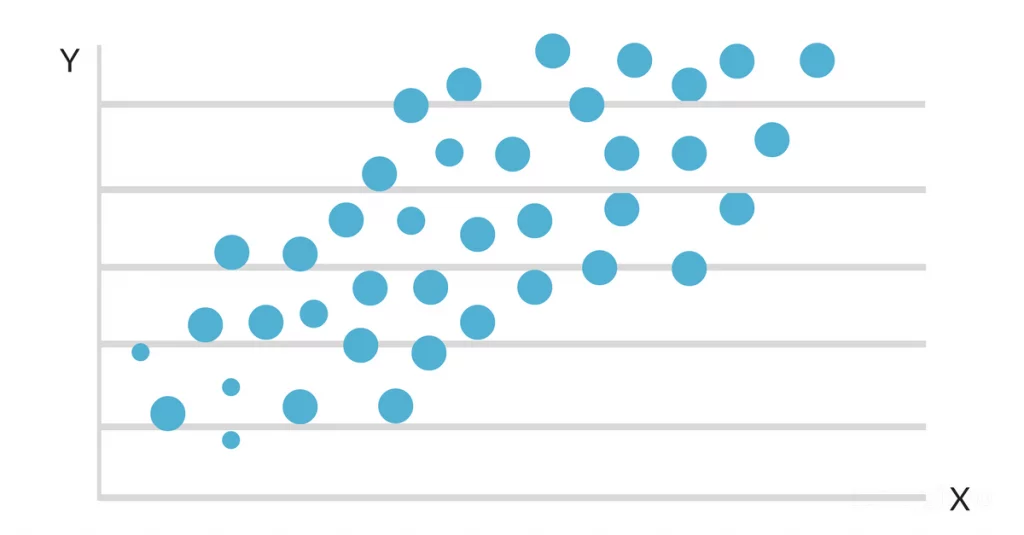
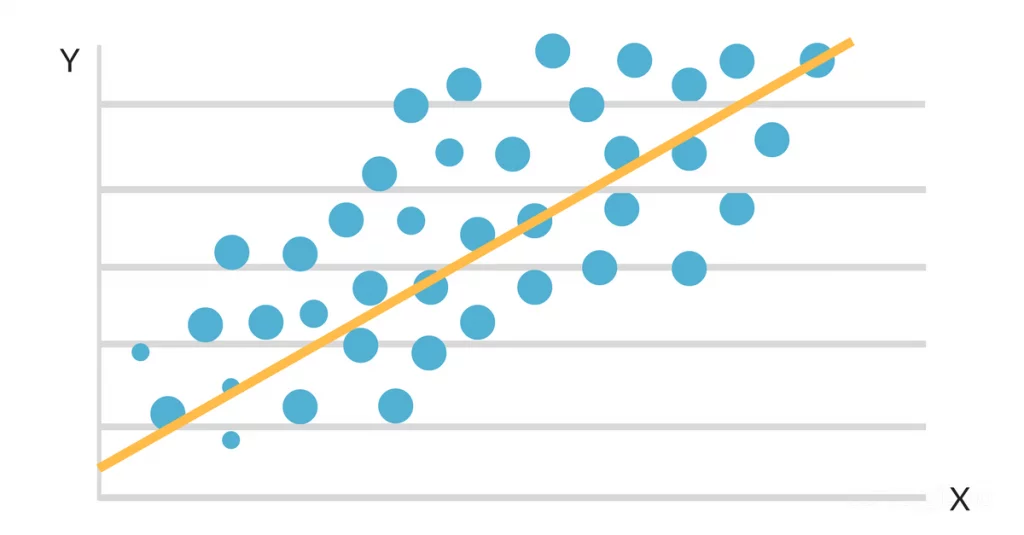
Der Zweck der Regressionsanalyse besteht darin, die am besten passende Linie oder Kurve zu ermitteln, die den Zusammenhang zwischen den unabhängigen Variablen und der abhängigen Variable widerspiegelt. Diese Best-Fit-Linie oder -Kurve wird mit statistischen Methoden erstellt, die die Unterschiede zwischen den erwarteten und den tatsächlichen Werten in der Datenerhebung verringern.
Im Folgenden finden Sie die Formeln für die beiden gängigsten Arten der Regressionsanalyse:
Einfache lineare Regression
Bei der einfachen linearen Regression wird die Beziehung zwischen zwei Variablen, der unabhängigen Variable (x) und der abhängigen Variable (y), anhand einer Anpassungsgeraden dargestellt.
Die beste Anpassungsgerade kann durch die Gleichung y = a + bx dargestellt werden.
Dabei ist a der Achsenabschnitt und b die Steigung der Linie. Um die Steigung zu berechnen, verwenden Sie die Formel: b = (nΣ(xy) - ΣxΣy) / (nΣ(x2) - (Σx)2), wobei n die Anzahl der Beobachtungen, Σxy die Summe des Produkts von x und y, Σx und Σy die Summen von x bzw. y und Σ(x2) ist die Summe der Quadrate von x.
Zur Berechnung des Achsenabschnitts wird folgende Formel verwendet: a = (Σy - bΣx) / n.
Mehrfache Regression
Multiple lineare Regression:
Die Formel für die Gleichung des multiplen linearen Regressionsmodells lautet:
y = b0 + b1x1 + b2x2 + ... + bnxn
wobei y die abhängige Variable ist, x1, x2, ..., xn sind die unabhängigen Variablen, und b0, b1, b2, ..., bn sind die Koeffizienten der unabhängigen Variablen.
Die Formel für die Schätzung der Koeffizienten mittels gewöhnlicher kleinster Quadrate lautet:
β = (X'X)(-1)X'y
wobei β ein Spaltenvektor der Koeffizienten, X die Designmatrix der unabhängigen Variablen, X' die Transponierte von X und y der Vektor der Beobachtungen der abhängigen Variable ist.
Beispiel einer Regressionsanalyse
Angenommen, Sie möchten den Zusammenhang zwischen dem Notendurchschnitt (GPA) einer Person und der Anzahl der Stunden, die sie pro Woche lernt, untersuchen. Sie sammeln Informationen von einer Reihe von Studenten, einschließlich der Anzahl ihrer Lernstunden und ihres Notendurchschnitts.
Verwenden Sie dann die Regressionsanalyse, um festzustellen, ob es einen linearen Zusammenhang zwischen den beiden Variablen gibt, und wenn ja, können Sie ein Modell erstellen, das den Notendurchschnitt eines Schülers auf der Grundlage der Anzahl der wöchentlichen Lernstunden vorhersagt.

Wenn die Daten auf einer Streuungskarte aufgetragen werden, zeigt sich, dass es einen günstigen linearen Zusammenhang zwischen Lernstunden und GPA gibt. Die Steigung und der Achsenabschnitt der besten Anpassungslinie werden dann mithilfe eines einfachen linearen Regressionsmodells geschätzt. Die endgültige Lösung könnte wie folgt aussehen:
GPA = 2,0 + 0,3 (Studienstunden pro Woche)
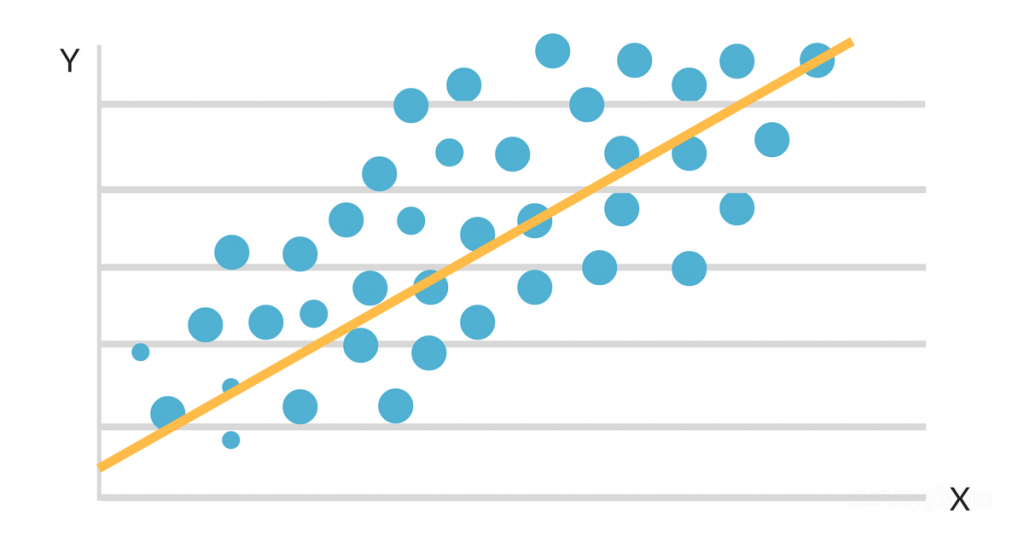
Diese Gleichung besagt, dass sich der Notendurchschnitt eines Schülers für jede zusätzliche Stunde Lernen pro Woche um 0,3 Punkte erhöht, wobei alles andere gleich bleibt. Dieser Algorithmus kann verwendet werden, um den Notendurchschnitt eines Schülers vorherzusagen, je nachdem, wie viele Stunden er pro Woche lernt, und um festzustellen, welche Schüler aufgrund ihrer Lerngewohnheiten Gefahr laufen, schlechte Leistungen zu erbringen.
Anhand der Daten aus dem Beispiel lassen sich die Werte für b und a sind wie folgt:
n = 10 (die Anzahl der Beobachtungen)
Σx = 30 (die Summe der Lernstunden)
Σy = 25 (die Summe der GPAs)
Σxy = 149 (die Summe des Produkts aus Studienstunden und Notendurchschnitt)
Σ(x)2 = 102 (die Summe der Quadrate der Studienstunden)
Berechnen Sie anhand dieser Werte b als:
b = (nΣ(xy) - ΣxΣy) / (nΣ(x2) - (Σx)2)
= (10 * 149 – 30 * 25) / (10 * 102 – 302)
= 0.3
Und berechnen a als:
a = (Σy - bΣx) / n
= (25 – 0.3 * 30) / 10
= 2.0
Die Gleichung der besten Anpassungsgeraden lautet daher:
GPA = 2,0 + 0,3 (Studienstunden pro Woche)
Was ist der Unterschied zwischen Korrelation und Regression?
Sowohl die Korrelation als auch die Regression sind statistische Methoden zur Untersuchung des Zusammenhangs zwischen zwei Variablen. Sie dienen unterschiedlichen Zwecken und liefern unterschiedliche Arten von Informationen.
Die Korrelation ist ein Maß für die Stärke und den Verlauf eines Zusammenhangs zwischen zwei Variablen. Sie reicht von -1 bis +1, wobei -1 für eine perfekte negative Korrelation, 0 für keine Korrelation und +1 für eine perfekte positive Korrelation steht. Die Korrelation gibt an, wie stark zwei Variablen miteinander verbunden sind, sie sagt jedoch nichts über die Ursache oder Vorhersagbarkeit aus.
Die Regression hingegen ist eine Methode zur Modellierung des Zusammenhangs zwischen zwei Variablen, in der Regel, um eine Variable auf der Grundlage der anderen vorherzusagen oder zu erklären. Die Regressionsanalyse kann Schätzungen über die Größe und Richtung der Beziehung sowie statistische Signifikanztests, Konfidenzbereiche und Prognosen für zukünftige Ergebnisse liefern.
Ihre Kreationen, fertig in wenigen Minuten
Mind the Graph ist eine Online-Plattform, die Ihnen eine umfangreiche Bibliothek mit wissenschaftlichen Illustrationen und Infografiken bietet, die Sie ganz einfach an Ihre individuellen Bedürfnisse anpassen können. Erstellen Sie in wenigen Minuten professionell aussehende Diagramme, Poster und grafische Zusammenfassungen mithilfe einer Drag-and-Drop-Oberfläche und einer breiten Palette von Tools und Funktionen.



{kind=link}
{kind=link}

Abonnieren Sie unseren Newsletter
Exklusive, qualitativ hochwertige Inhalte über effektive visuelle
Kommunikation in der Wissenschaft.