
In de afgelopen jaren heeft machine learning zich ontpopt als een krachtig hulpmiddel in de wetenschap en een revolutie teweeggebracht in de manier waarop onderzoekers complexe gegevens onderzoeken en analyseren. Dankzij het vermogen om automatisch patronen te leren, voorspellingen te doen en verborgen inzichten bloot te leggen, heeft machinaal leren nieuwe wegen geopend voor wetenschappelijk onderzoek. Het doel van dit artikel is om de cruciale rol van machinaal leren in de wetenschap te benadrukken door het brede scala aan toepassingen, de vooruitgang op dit gebied en het potentieel voor verdere ontdekkingen te verkennen. Door de werking van machinaal leren te begrijpen, verleggen wetenschappers de grenzen van kennis, ontrafelen ze ingewikkelde fenomenen en maken ze de weg vrij voor baanbrekende innovaties.
Wat is machinaal leren?
Machine Learning is een tak van Kunstmatige Intelligentie (AI) die zich richt op het ontwikkelen van algoritmen en modellen waarmee computers kunnen leren van gegevens en voorspellingen of beslissingen kunnen maken zonder expliciet geprogrammeerd te zijn. Het gaat om de studie van statistische en computationele technieken waarmee computers automatisch patronen, relaties en afhankelijkheden in gegevens kunnen analyseren en interpreteren, wat leidt tot het verkrijgen van waardevolle inzichten en kennis.
Gerelateerd artikel: Kunstmatige intelligentie in de wetenschap
Machine leren in de wetenschap
Machine Learning heeft zich ontpopt als een krachtig hulpmiddel in verschillende wetenschappelijke disciplines en heeft een revolutie teweeggebracht in de manier waarop onderzoekers complexe datasets analyseren en interpreteren. In de wetenschap worden Machine Learning technieken gebruikt om verschillende uitdagingen aan te gaan, zoals het voorspellen van eiwitstructuren, het classificeren van astronomische objecten, het modelleren van klimaatpatronen en het identificeren van patronen in genetische gegevens. Wetenschappers kunnen Machine Learning-algoritmen trainen om verborgen patronen bloot te leggen, nauwkeurige voorspellingen te doen en een beter begrip te krijgen van complexe verschijnselen door grote hoeveelheden gegevens te gebruiken. Machine Learning in de wetenschap verbetert niet alleen de efficiëntie en nauwkeurigheid van gegevensanalyse, maar opent ook nieuwe wegen voor ontdekkingen, waardoor onderzoekers complexe wetenschappelijke vragen kunnen aanpakken en de vooruitgang in hun vakgebied kunnen versnellen.
Soorten machinaal leren
Sommige typen van Machine Learning omvatten een breed scala aan benaderingen en technieken, elk geschikt voor verschillende probleemdomeinen en gegevenskenmerken. Onderzoekers en praktijkmensen kunnen de meest geschikte aanpak voor hun specifieke taken kiezen en de kracht van Machine Learning benutten om inzichten te verkrijgen en gefundeerde beslissingen te nemen. Hier zijn enkele van de soorten Machine Learning:
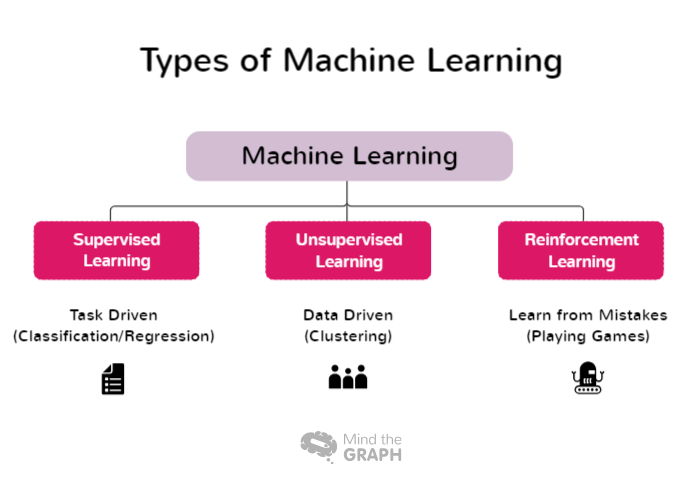
Gesuperviseerd leren
Bewaakt leren is een fundamentele benadering van machinaal leren waarbij het model wordt getraind met behulp van gelabelde datasets. In deze context verwijzen gelabelde gegevens naar invoergegevens die worden gekoppeld aan overeenkomstige uitvoer- of doellabels. Het doel van gesuperviseerd leren is om het model in staat te stellen patronen en relaties te leren tussen de inputkenmerken en hun overeenkomstige labels, zodat het nauwkeurige voorspellingen of classificaties kan doen op nieuwe, ongeziene gegevens.
Tijdens het trainingsproces past het model iteratief zijn parameters aan op basis van de verstrekte gelabelde gegevens, waarbij wordt gestreefd naar een zo klein mogelijk verschil tussen de voorspelde uitvoer en de werkelijke labels. Hierdoor kan het model generaliseren en nauwkeurige voorspellingen doen over ongeziene gegevens. Supervised learning wordt veel gebruikt in verschillende toepassingen, waaronder beeldherkenning, spraakherkenning, verwerking van natuurlijke taal en voorspellende analyse.
Leren zonder toezicht
Niet-gesuperviseerd leren is een tak van machinaal leren die zich richt op het analyseren en clusteren van ongelabelde datasets zonder gebruik te maken van vooraf gedefinieerde doellabels. Bij ongesuperviseerd leren zijn algoritmen ontworpen om automatisch patronen, overeenkomsten en verschillen in de gegevens te detecteren. Door deze verborgen structuren bloot te leggen, stelt unsupervised learning onderzoekers en organisaties in staat om waardevolle inzichten te verwerven en datagestuurde beslissingen te nemen.
Deze aanpak is vooral nuttig bij verkennende gegevensanalyse, waarbij het doel is om de onderliggende structuur van de gegevens te begrijpen en potentiële patronen of relaties te identificeren. Unsupervised learning vindt ook toepassingen in verschillende domeinen zoals klantsegmentatie, anomaliedetectie, aanbevelingssystemen en beeldherkenning.
Versterking leren
Versterkingsleren (RL) is een tak van machinaal leren die zich richt op hoe intelligente agenten kunnen leren om optimale beslissingen te nemen in een omgeving om cumulatieve beloningen te maximaliseren. In tegenstelling tot gesuperviseerd leren, dat vertrouwt op gelabelde input/output paren of unsupervised leren dat verborgen patronen probeert te ontdekken, werkt versterkingsleren door te leren van interacties met de omgeving. De bedoeling is om een evenwicht te vinden tussen exploratie, waarbij de agent nieuwe strategieën ontdekt, en exploitatie, waarbij de agent zijn huidige kennis gebruikt om weloverwogen beslissingen te nemen.
Bij het leren van versterking wordt de omgeving meestal beschreven als een Markov beslissingsproces (MDP), waardoor dynamische programmeertechnieken gebruikt kunnen worden. In tegenstelling tot klassieke dynamische programmeermethoden vereisen RL-algoritmen geen exact wiskundig model van de MDP en zijn ze ontworpen om grootschalige problemen aan te pakken waar exacte methoden onpraktisch zijn. Door versterkingsleertechnieken toe te passen, kunnen agenten hun besluitvormingsvaardigheden in de loop van de tijd aanpassen en verbeteren, waardoor het een krachtige aanpak is voor taken zoals autonome navigatie, robotica, spelletjes en middelenbeheer.
Algoritmen en technieken voor machinaal leren
Algoritmen en technieken voor machinaal leren bieden verschillende mogelijkheden en worden in verschillende domeinen toegepast om complexe problemen op te lossen. Elk algoritme heeft zijn eigen sterke en zwakke punten en inzicht in hun kenmerken kan onderzoekers en praktijkmensen helpen om de meest geschikte aanpak voor hun specifieke taken te kiezen. Door gebruik te maken van deze algoritmen kunnen wetenschappers waardevolle inzichten uit gegevens halen en weloverwogen beslissingen nemen op hun vakgebied.
Random Forests
Random Forests is een populair algoritme in machinaal leren dat valt onder de categorie van ensemble leren. Het combineert meerdere beslisbomen om voorspellingen te doen of gegevens te classificeren. Elke beslisboom in het random forest wordt getraind op een andere subset van de gegevens en de uiteindelijke voorspelling wordt bepaald door de voorspellingen van alle individuele bomen samen te voegen. Random Forests staan bekend om hun vermogen om complexe datasets te verwerken, accurate voorspellingen te doen en om te gaan met ontbrekende waarden. Ze worden veel gebruikt in verschillende domeinen, waaronder financiën, gezondheidszorg en beeldherkenning.
Diep lerend algoritme
Deep Learning is een subset van machine learning die zich richt op het trainen van kunstmatige neurale netwerken met meerdere lagen om representaties van gegevens te leren. Diep-lerende algoritmen, zoals Convolutionele neurale netwerken (CNN's) en Terugkerende Neurale Netwerken (RNN's), hebben opmerkelijk succes geboekt in taken zoals beeld- en spraakherkenning, natuurlijke taalverwerking en aanbevelingssystemen. Diep-lerende algoritmen kunnen automatisch hiërarchische kenmerken leren uit ruwe gegevens, waardoor ze ingewikkelde patronen kunnen vastleggen en zeer nauwkeurige voorspellingen kunnen doen. Diep-lerende algoritmen vereisen echter grote hoeveelheden gelabelde gegevens en aanzienlijke computermiddelen voor training. Ga voor meer informatie over deep learning naar Website IBM.
Gaussische processen
Gaussiaanse Processen zijn een krachtige techniek die wordt gebruikt bij machinaal leren voor het modelleren en doen van voorspellingen op basis van kansverdelingen. Ze zijn vooral nuttig bij het werken met kleine, lawaaierige datasets. Gaussiaanse processen bieden een flexibele en niet-parametrische benadering die complexe relaties tussen variabelen kan modelleren zonder sterke aannames te doen over de onderliggende gegevensverdeling. Ze worden vaak gebruikt in regressieproblemen, waarbij het doel is om een continue output te schatten op basis van inputkenmerken. Gaussische processen hebben toepassingen in gebieden zoals geostatistiek, financiën en optimalisatie.
Toepassing van machinaal leren in de wetenschap
De toepassing van machinaal leren in de wetenschap opent nieuwe wegen voor onderzoek en stelt wetenschappers in staat om complexe problemen aan te pakken, patronen te ontdekken en voorspellingen te doen op basis van grote en diverse datasets. Door de kracht van machinaal leren te benutten, kunnen wetenschappers diepere inzichten verwerven, wetenschappelijke ontdekkingen versnellen en kennis in verschillende wetenschappelijke domeinen bevorderen.
Medische beeldvorming
Machine learning heeft een belangrijke bijdrage geleverd aan de medische beeldvorming en een revolutie teweeggebracht in de diagnostische en prognostische mogelijkheden. Machine learning-algoritmen kunnen medische beelden zoals röntgenfoto's, MRI's en CT-scans analyseren om te helpen bij de detectie en diagnose van verschillende ziekten en aandoeningen. Ze kunnen helpen bij het identificeren van afwijkingen, het segmenteren van organen of weefsels en het voorspellen van patiëntresultaten. Door gebruik te maken van machine learning in medische beeldvorming kunnen professionals in de gezondheidszorg de nauwkeurigheid en efficiëntie van hun diagnoses verbeteren, wat leidt tot betere patiëntenzorg en planning van behandelingen.
Actief leren
Actief leren is een techniek voor machinaal leren waarbij het algoritme interactief een mens of een orakel om gelabelde gegevens kan vragen. In wetenschappelijk onderzoek kan actief leren waardevol zijn bij het werken met beperkte gelabelde datasets of wanneer het annotatieproces tijdrovend of duur is. Door op intelligente wijze de meest informatieve instanties voor labeling te selecteren, kunnen algoritmen voor actief leren een hoge nauwkeurigheid bereiken met minder gelabelde voorbeelden, waardoor de last van handmatige annotatie wordt verminderd en wetenschappelijke ontdekkingen worden versneld.
Wetenschappelijke toepassingen
Machine learning vindt wijdverspreide toepassingen in verschillende wetenschappelijke disciplines. In de genomica kunnen algoritmen voor machinaal leren DNA- en RNA-sequenties analyseren om genetische variaties te identificeren, eiwitstructuren te voorspellen en genfuncties te begrijpen. In de materiaalkunde wordt machine learning gebruikt om nieuwe materialen met de gewenste eigenschappen te ontwerpen, de ontdekking van materialen te versnellen en productieprocessen te optimaliseren. Machine-learningtechnieken worden ook gebruikt in de milieuwetenschap voor het voorspellen en monitoren van vervuilingsniveaus, weersvoorspellingen en het analyseren van klimaatgegevens. Bovendien speelt het een cruciale rol in de natuurkunde, scheikunde, astronomie en vele andere wetenschappelijke gebieden door gegevensgestuurde modellering, simulatie en analyse mogelijk te maken.
Voordelen van machinaal leren in de wetenschap
De voordelen van machine learning in de wetenschap zijn talrijk en impactvol. Hier zijn enkele belangrijke voordelen:
Verbeterde voorspellende modellen: Algoritmen voor machinaal leren kunnen grote en complexe datasets analyseren om patronen, trends en relaties te identificeren die niet gemakkelijk te herkennen zijn met traditionele statistische methoden. Hierdoor kunnen wetenschappers nauwkeurige voorspellende modellen ontwikkelen voor verschillende wetenschappelijke verschijnselen en uitkomsten, wat leidt tot nauwkeurigere voorspellingen en betere besluitvorming.
Verhoogde efficiëntie en automatisering: Machine-learningtechnieken automatiseren repetitieve en tijdrovende taken, waardoor wetenschappers zich kunnen richten op complexere en creatievere aspecten van onderzoek. Machine learning-algoritmen kunnen enorme hoeveelheden gegevens verwerken, snelle analyses uitvoeren en efficiënt inzichten en conclusies genereren. Dit leidt tot een hogere productiviteit en versnelt het tempo van wetenschappelijke ontdekkingen.
Verbeterde gegevensanalyse en -interpretatie: Machine learning-algoritmen blinken uit in gegevensanalyse, waardoor wetenschappers waardevolle inzichten kunnen halen uit grote en heterogene datasets. Ze kunnen verborgen patronen, correlaties en anomalieën identificeren die niet direct duidelijk zijn voor menselijke onderzoekers. Machine-learningtechnieken helpen ook bij de interpretatie van gegevens door verklaringen, visualisaties en samenvattingen te bieden, waardoor een dieper begrip van complexe wetenschappelijke fenomenen mogelijk wordt.
Gefaciliteerde beslissingsondersteuning: Modellen voor machinaal leren kunnen dienen als hulpmiddelen voor wetenschappers om beslissingen te nemen. Door historische gegevens en real-time informatie te analyseren, kunnen algoritmen voor machinaal leren helpen bij besluitvormingsprocessen, zoals het selecteren van de meest veelbelovende onderzoekswegen, het optimaliseren van experimentele parameters of het identificeren van potentiële risico's of uitdagingen in wetenschappelijke projecten. Dit helpt wetenschappers weloverwogen beslissingen te nemen en verhoogt de kans op succesvolle resultaten.
Versnelde wetenschappelijke ontdekkingen: Machine learning versnelt wetenschappelijke ontdekkingen door onderzoekers in staat te stellen enorme hoeveelheden gegevens te onderzoeken, hypotheses te genereren en theorieën efficiënter te valideren. Door gebruik te maken van algoritmen voor machinaal leren kunnen wetenschappers nieuwe verbanden leggen, nieuwe inzichten ontdekken en onderzoeksrichtingen identificeren die anders misschien over het hoofd zouden zijn gezien. Dit leidt tot doorbraken op verschillende wetenschappelijke gebieden en bevordert innovatie.
Communiceer wetenschap visueel met de kracht van de beste en gratis infographicmaker
Mind the Graph platform is een waardevolle bron die wetenschappers helpt bij het effectief visueel communiceren van hun onderzoek. Met de kracht van de beste en gratis infographic maker, stelt dit platform wetenschappers in staat om boeiende en informatieve infographics te maken die complexe wetenschappelijke concepten en data visueel weergeven. Of het nu gaat om het presenteren van onderzoeksresultaten, het uitleggen van wetenschappelijke processen of het visualiseren van datatrends, het Mind the Graph platform biedt wetenschappers de middelen om hun wetenschap visueel duidelijk en overtuigend te communiceren. Meld je gratis aan en begin nu met het maken van een ontwerp.





Abonneer u op onze nieuwsbrief
Exclusieve inhoud van hoge kwaliteit over effectieve visuele
communicatie in de wetenschap.