
V posledních letech se strojové učení stalo mocným nástrojem v oblasti vědy a způsobilo revoluci ve způsobu, jakým výzkumníci zkoumají a analyzují složitá data. Díky schopnosti automaticky se učit vzorce, vytvářet předpovědi a odhalovat skryté poznatky otevřelo strojové učení nové cesty pro vědecké zkoumání. Tento článek si klade za cíl vyzdvihnout klíčovou roli strojového učení ve vědě tím, že zkoumá jeho širokou škálu aplikací, pokroky dosažené v této oblasti a potenciál, který v sobě skrývá pro další objevy. Díky pochopení fungování strojového učení vědci posouvají hranice poznání, odhalují složité jevy a připravují půdu pro převratné inovace.
Co je strojové učení?
Strojové učení je obor Umělá inteligence (AI), která se zaměřuje na vývoj algoritmů a modelů umožňujících počítačům učit se z dat a provádět předpovědi nebo rozhodnutí, aniž by byly výslovně naprogramovány. Zahrnuje studium statistických a výpočetních technik, které umožňují počítačům automaticky analyzovat a interpretovat vzory, vztahy a závislosti v datech, což vede k získání cenných poznatků a znalostí.
Související článek: Umělá inteligence ve vědě
Strojové učení ve vědě
Strojové učení se stalo mocným nástrojem v různých vědních oborech a způsobilo revoluci ve způsobu, jakým výzkumníci analyzují a interpretují složité soubory dat. Ve vědě se techniky strojového učení používají k řešení různých problémů, jako je předpovídání struktury proteinů, klasifikace astronomických objektů, modelování klimatických vzorců a identifikace vzorců v genetických datech. Vědci mohou pomocí velkých objemů dat trénovat algoritmy strojového učení, aby odhalili skryté vzorce, prováděli přesné předpovědi a získali hlubší porozumění složitým jevům. Strojové učení ve vědě nejen zvyšuje efektivitu a přesnost analýzy dat, ale také otevírá nové cesty k objevování, což umožňuje výzkumníkům řešit složité vědecké otázky a urychlit pokrok v příslušných oborech.
Typy strojového učení
Některé typy strojového učení zahrnují širokou škálu přístupů a technik, z nichž každá je vhodná pro různé problémové oblasti a charakteristiky dat. Výzkumníci a odborníci z praxe si mohou vybrat nejvhodnější přístup pro své konkrétní úkoly a využít sílu strojového učení k získání poznatků a přijímání informovaných rozhodnutí. Zde jsou některé typy strojového učení:
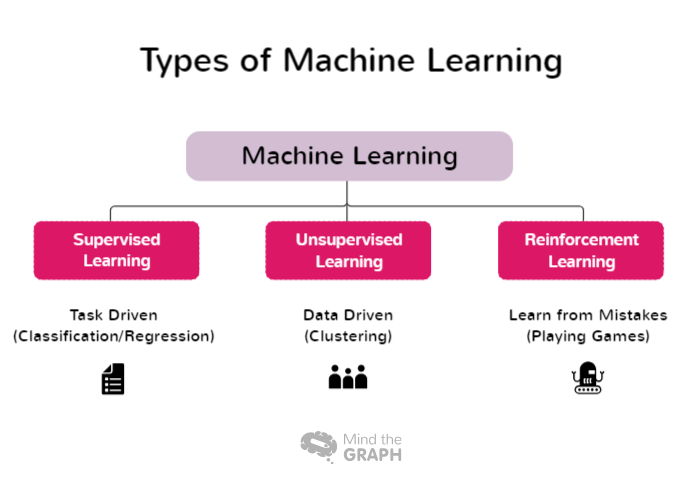
Učení pod dohledem
Supervised learning je základní přístup ve strojovém učení, kdy se model trénuje pomocí označených datových sad. V tomto kontextu se označenými daty rozumí vstupní data, která jsou spárována s odpovídajícími výstupními nebo cílovými značkami. Cílem učení pod dohledem je umožnit modelu naučit se vzorce a vztahy mezi vstupními prvky a jim odpovídajícími štítky, což mu umožní provádět přesné předpovědi nebo klasifikace na nových, dosud neviděných datech.
Během procesu učení model iterativně upravuje své parametry na základě poskytnutých označených dat a snaží se minimalizovat rozdíl mezi svými předpovězenými výstupy a skutečnými označeními. To umožňuje modelu zobecňovat a provádět přesné předpovědi na neoznačených datech. Supervised learning se široce používá v různých aplikacích, včetně rozpoznávání obrazu, rozpoznávání řeči, zpracování přirozeného jazyka a prediktivní analýzy.
Učení bez dohledu
Učení bez dohledu je odvětví strojového učení, které se zaměřuje na analýzu a shlukování neoznačených souborů dat bez použití předem definovaných cílových značek. V neřízeném učení jsou algoritmy navrženy tak, aby automaticky odhalovaly vzory, podobnosti a rozdíly v datech. Odhalením těchto skrytých struktur umožňuje neřízené učení výzkumníkům a organizacím získat cenné poznatky a přijímat rozhodnutí založená na datech.
Tento přístup je užitečný zejména při průzkumné analýze dat, kdy je cílem pochopit základní strukturu dat a identifikovat potenciální vzorce nebo vztahy. Unsupervised learning nachází uplatnění také v různých oblastech, jako je segmentace zákazníků, detekce anomálií, doporučovací systémy a rozpoznávání obrazu.
Učení posilováním
Učení s posilováním (Reinforcement learning, RL) je odvětví strojového učení, které se zaměřuje na to, jak se inteligentní agenti mohou naučit přijímat optimální rozhodnutí v prostředí s cílem maximalizovat kumulativní odměnu. Na rozdíl od učení pod dohledem, které se spoléhá na označené dvojice vstupů a výstupů, nebo učení bez dohledu, které se snaží odhalit skryté vzorce, učení s posilováním funguje tak, že se učí z interakcí s prostředím. Záměrem je najít rovnováhu mezi průzkumem, kdy agent objevuje nové strategie, a využíváním, kdy agent využívá své současné znalosti k přijímání informovaných rozhodnutí.
Při učení posilováním se prostředí obvykle popisuje jako Markovův rozhodovací proces (MDP), který umožňuje použití technik dynamického programování. Na rozdíl od klasických metod dynamického programování nevyžadují algoritmy RL přesný matematický model MDP a jsou určeny pro řešení rozsáhlých problémů, kde jsou přesné metody nepraktické. Použitím technik posilování učení se agenti mohou v průběhu času přizpůsobovat a zlepšovat své rozhodovací schopnosti, což z něj činí výkonný přístup pro úlohy, jako je autonomní navigace, robotika, hraní her a správa zdrojů.
Algoritmy a techniky strojového učení
Algoritmy a techniky strojového učení nabízejí rozmanité možnosti a používají se v různých oblastech k řešení složitých problémů. Každý algoritmus má své silné a slabé stránky a pochopení jejich vlastností může výzkumníkům a odborníkům z praxe pomoci vybrat nejvhodnější přístup pro jejich konkrétní úkoly. Využitím těchto algoritmů mohou vědci získat cenné poznatky z dat a činit informovaná rozhodnutí v příslušných oblastech.
Náhodné lesy
Náhodné lesy jsou oblíbeným algoritmem strojového učení, který spadá do kategorie skupinového učení. Kombinuje více rozhodovacích stromů, které slouží k předpovědím nebo klasifikaci dat. Každý rozhodovací strom v náhodném lese je vycvičen na jiné podmnožině dat a konečná předpověď je určena agregací předpovědí všech jednotlivých stromů. Náhodné lesy jsou známé svou schopností zpracovávat složité soubory dat, poskytovat přesné předpovědi a zpracovávat chybějící hodnoty. Jsou široce používány v různých oblastech, včetně financí, zdravotnictví a rozpoznávání obrazu.
Algoritmus hlubokého učení
Hluboké učení je podmnožinou strojového učení, která se zaměřuje na trénování umělých neuronových sítí s více vrstvami za účelem učení reprezentace dat. Algoritmy hlubokého učení, jako např. Konvoluční neuronové sítě (CNN) a Rekurentní neuronové sítě (RNN) dosáhly pozoruhodných úspěchů v úlohách, jako je rozpoznávání obrazu a řeči, zpracování přirozeného jazyka a doporučovací systémy. Algoritmy hlubokého učení se mohou automaticky učit hierarchické funkce ze surových dat, což jim umožňuje zachytit složité vzorce a provádět velmi přesné předpovědi. Algoritmy hlubokého učení však vyžadují velké množství označených dat a značné výpočetní zdroje pro trénování. Chcete-li se o hlubokém učení dozvědět více, navštivte Webové stránky IBM.
Gaussovy procesy
Gaussovy procesy jsou výkonnou technikou používanou ve strojovém učení k modelování a vytváření předpovědí na základě rozdělení pravděpodobnosti. Jsou užitečné zejména při práci s malými, zašuměnými soubory dat. Gaussovy procesy poskytují flexibilní a neparametrický přístup, který dokáže modelovat složité vztahy mezi proměnnými bez silných předpokladů o základním rozdělení dat. Běžně se používají v regresních úlohách, kde je cílem odhadnout spojitý výstup na základě vstupních funkcí. Gaussovské procesy nacházejí uplatnění v oblastech, jako je geostatistika, finance a optimalizace.
Aplikace strojového učení ve vědě
Použití strojového učení ve vědě otevírá nové možnosti výzkumu a umožňuje vědcům řešit složité problémy, odhalovat vzorce a vytvářet předpovědi na základě velkých a různorodých souborů dat. Využitím síly strojového učení mohou vědci získat hlubší poznatky, urychlit vědecké objevy a prohloubit znalosti v různých vědeckých oblastech.
Lékařské zobrazování
Strojové učení významně přispělo k lékařskému zobrazování a způsobilo revoluci v diagnostických a prognostických schopnostech. Algoritmy strojového učení mohou analyzovat lékařské snímky, jako jsou rentgenové snímky, magnetická rezonance a počítačová tomografie, a pomáhat tak při odhalování a diagnostice různých onemocnění a stavů. Mohou pomáhat při identifikaci anomálií, segmentaci orgánů nebo tkání a předpovídání výsledků léčby pacientů. Využitím strojového učení v lékařském zobrazování mohou zdravotníci zvýšit přesnost a efektivitu svých diagnóz, což vede k lepší péči o pacienty a plánování léčby.
Aktivní učení
Aktivní učení je technika strojového učení, která umožňuje algoritmu interaktivně se dotazovat člověka nebo orákula na označená data. Ve vědeckém výzkumu může být aktivní učení cenné, pokud se pracuje s omezenými soubory označených dat nebo pokud je proces anotace časově náročný nebo nákladný. Inteligentním výběrem nejinformativnějších případů pro označení mohou algoritmy aktivního učení dosáhnout vysoké přesnosti s menším počtem označených příkladů, což snižuje zátěž ruční anotace a urychluje vědecké objevy.
Vědecké aplikace
Strojové učení nachází široké uplatnění v různých vědních oborech. V genomice mohou algoritmy strojového učení analyzovat sekvence DNA a RNA, aby identifikovaly genetické variace, předpovídaly struktury proteinů a pochopily funkce genů. Ve vědě o materiálech se strojové učení používá k navrhování nových materiálů s požadovanými vlastnostmi, k urychlení objevování materiálů a k optimalizaci výrobních procesů. Techniky strojového učení se používají také ve vědě o životním prostředí k předpovídání a monitorování úrovně znečištění, předpovědi počasí a analýze klimatických dat. Kromě toho hraje klíčovou roli ve fyzice, chemii, astronomii a mnoha dalších vědních oborech, protože umožňuje modelování, simulace a analýzy založené na datech.
Výhody strojového učení ve vědě
Přínosy strojového učení ve vědě jsou četné a mají velký dopad. Zde je několik klíčových výhod:
Vylepšené prediktivní modelování: Algoritmy strojového učení mohou analyzovat rozsáhlé a složité soubory dat a identifikovat vzory, trendy a vztahy, které nemusí být snadno rozpoznatelné pomocí tradičních statistických metod. To umožňuje vědcům vyvíjet přesné prediktivní modely pro různé vědecké jevy a výsledky, což vede k přesnějším předpovědím a lepšímu rozhodování.
Zvýšení efektivity a automatizace: Techniky strojového učení automatizují opakující se a časově náročné úkoly a umožňují vědcům zaměřit své úsilí na složitější a kreativnější aspekty výzkumu. Algoritmy strojového učení dokáží zpracovávat obrovské množství dat, provádět rychlou analýzu a efektivně generovat poznatky a závěry. To vede ke zvýšení produktivity a zrychluje tempo vědeckých objevů.
Zlepšená analýza a interpretace dat: Algoritmy strojového učení vynikají v analýze dat a umožňují vědcům získávat cenné poznatky z velkých a různorodých souborů dat. Dokážou identifikovat skryté vzorce, korelace a anomálie, které nemusí být lidským výzkumníkům okamžitě zřejmé. Techniky strojového učení také pomáhají při interpretaci dat tím, že poskytují vysvětlení, vizualizace a shrnutí, což usnadňuje hlubší pochopení složitých vědeckých jevů.
Zjednodušená podpora rozhodování: Modely strojového učení mohou vědcům sloužit jako nástroje pro podporu rozhodování. Analýzou historických dat a informací v reálném čase mohou algoritmy strojového učení pomáhat v rozhodovacích procesech, jako je výběr nejslibnějších výzkumných cest, optimalizace experimentálních parametrů nebo identifikace potenciálních rizik či problémů ve vědeckých projektech. To pomáhá vědcům činit informovaná rozhodnutí a zvyšuje šance na dosažení úspěšných výsledků.
Zrychlené vědecké objevy: Strojové učení urychluje vědecké objevy tím, že umožňuje výzkumníkům efektivněji zkoumat obrovské množství dat, vytvářet hypotézy a ověřovat teorie. Využitím algoritmů strojového učení mohou vědci vytvářet nové souvislosti, odhalovat nové poznatky a identifikovat směry výzkumu, které by jinak mohly být přehlédnuty. To vede k průlomovým objevům v různých vědeckých oborech a podporuje inovace.
Vizuální komunikace o vědě pomocí nejlepšího a bezplatného nástroje pro tvorbu infografiky
Mind the Graph je cenným zdrojem, který vědcům pomáhá efektivně vizuálně komunikovat jejich výzkum. Díky síle nejlepšího a bezplatného nástroje pro tvorbu infografik umožňuje tato platforma vědcům vytvářet poutavé a informativní infografiky, které vizuálně zobrazují složité vědecké koncepty a data. Ať už se jedná o prezentaci výsledků výzkumu, vysvětlení vědeckých procesů nebo vizualizaci datových trendů, platforma Mind the Graph poskytuje vědcům prostředky, jak vizuálně jasně a přesvědčivě komunikovat svou vědu. Zaregistrujte se zdarma a začněte vytvářet design hned teď.





Přihlaste se k odběru našeho newsletteru
Exkluzivní vysoce kvalitní obsah o efektivním vizuálním
komunikace ve vědě.