
Negli ultimi anni, l'apprendimento automatico è emerso come un potente strumento nel campo della scienza, rivoluzionando il modo in cui i ricercatori esplorano e analizzano dati complessi. Grazie alla sua capacità di apprendere automaticamente modelli, fare previsioni e scoprire intuizioni nascoste, l'apprendimento automatico ha aperto nuove strade all'indagine scientifica. Questo articolo ha l'obiettivo di evidenziare il ruolo cruciale dell'apprendimento automatico nella scienza, esplorando la sua ampia gamma di applicazioni, i progressi compiuti in questo campo e il potenziale che racchiude per ulteriori scoperte. Comprendendo il funzionamento dell'apprendimento automatico, gli scienziati stanno spingendo i confini della conoscenza, svelando fenomeni intricati e aprendo la strada a innovazioni rivoluzionarie.
Che cos'è l'apprendimento automatico?
L'apprendimento automatico è una branca del Intelligenza artificiale (AI) che si concentra sullo sviluppo di algoritmi e modelli che consentono ai computer di imparare dai dati e di fare previsioni o prendere decisioni senza essere esplicitamente programmati. Si tratta dello studio di tecniche statistiche e computazionali che consentono ai computer di analizzare e interpretare automaticamente schemi, relazioni e dipendenze all'interno dei dati, portando all'estrazione di preziose intuizioni e conoscenze.
Articolo correlato: L'intelligenza artificiale nella scienza
Apprendimento automatico nella scienza
Il Machine Learning è emerso come un potente strumento in diverse discipline scientifiche, rivoluzionando il modo in cui i ricercatori analizzano e interpretano insiemi di dati complessi. Nella scienza, le tecniche di Machine Learning sono impiegate per affrontare diverse sfide, come la previsione delle strutture proteiche, la classificazione degli oggetti astronomici, la modellazione dei modelli climatici e l'identificazione di modelli nei dati genetici. Gli scienziati possono addestrare gli algoritmi di Machine Learning per scoprire modelli nascosti, fare previsioni accurate e ottenere una comprensione più profonda di fenomeni complessi, utilizzando grandi volumi di dati. Il Machine Learning nella scienza non solo migliora l'efficienza e l'accuratezza dell'analisi dei dati, ma apre anche nuove strade per la scoperta, consentendo ai ricercatori di affrontare domande scientifiche complesse e accelerare i progressi nei rispettivi campi.
Tipi di apprendimento automatico
Alcuni tipi di Machine Learning coprono un'ampia gamma di approcci e tecniche, ciascuno adatto a diversi domini problematici e caratteristiche dei dati. Ricercatori e professionisti possono scegliere l'approccio più appropriato per i loro compiti specifici e sfruttare la potenza del Machine Learning per estrarre intuizioni e prendere decisioni informate. Ecco alcuni tipi di Machine Learning:
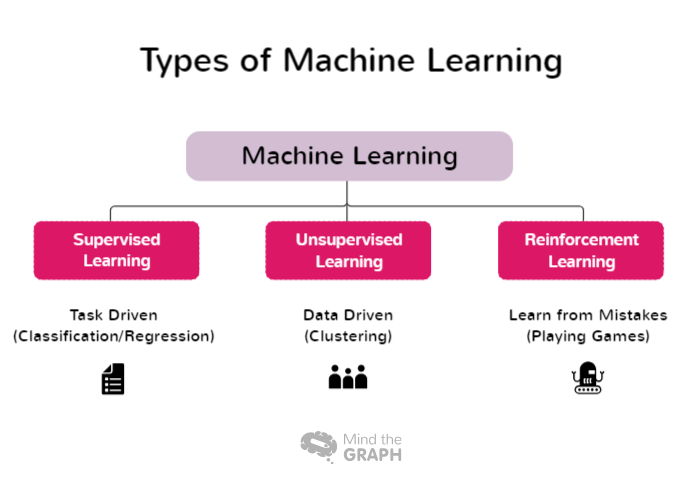
Apprendimento supervisionato
L'apprendimento supervisionato è un approccio fondamentale nell'apprendimento automatico in cui il modello viene addestrato utilizzando insiemi di dati etichettati. In questo contesto, i dati etichettati si riferiscono ai dati di input che sono abbinati alle corrispondenti etichette di output o di destinazione. L'obiettivo dell'apprendimento supervisionato è quello di consentire al modello di apprendere schemi e relazioni tra le caratteristiche di input e le etichette corrispondenti, consentendogli di fare previsioni o classificazioni accurate su nuovi dati non visti.
Durante il processo di addestramento, il modello regola iterativamente i suoi parametri in base ai dati etichettati forniti, cercando di minimizzare la differenza tra le sue uscite previste e le etichette vere. In questo modo il modello è in grado di generalizzare e di fare previsioni accurate su dati non visti. L'apprendimento supervisionato è ampiamente utilizzato in varie applicazioni, tra cui il riconoscimento di immagini, il riconoscimento vocale, l'elaborazione del linguaggio naturale e l'analisi predittiva.
Apprendimento non supervisionato
L'apprendimento non supervisionato è una branca dell'apprendimento automatico che si concentra sull'analisi e sul raggruppamento di insiemi di dati non etichettati senza l'uso di etichette predefinite. Nell'apprendimento non supervisionato, gli algoritmi sono progettati per rilevare automaticamente modelli, somiglianze e differenze all'interno dei dati. Scoprendo queste strutture nascoste, l'apprendimento non supervisionato consente ai ricercatori e alle organizzazioni di ottenere informazioni preziose e di prendere decisioni basate sui dati.
Questo approccio è particolarmente utile nell'analisi esplorativa dei dati, dove l'obiettivo è comprendere la struttura sottostante dei dati e identificare potenziali modelli o relazioni. L'apprendimento non supervisionato trova applicazione anche in diversi ambiti, come la segmentazione dei clienti, il rilevamento di anomalie, i sistemi di raccomandazione e il riconoscimento delle immagini.
Apprendimento per rinforzo
L'apprendimento per rinforzo (RL) è una branca dell'apprendimento automatico che si concentra su come gli agenti intelligenti possano imparare a prendere decisioni ottimali in un ambiente per massimizzare le ricompense cumulative. A differenza dell'apprendimento supervisionato, che si basa su coppie ingresso/uscita etichettate, o dell'apprendimento non supervisionato, che cerca di scoprire modelli nascosti, l'apprendimento per rinforzo opera imparando dalle interazioni con l'ambiente. L'intento è quello di trovare un equilibrio tra l'esplorazione, in cui l'agente scopre nuove strategie, e lo sfruttamento, in cui l'agente sfrutta le sue conoscenze attuali per prendere decisioni informate.
Nell'apprendimento per rinforzo, l'ambiente viene tipicamente descritto come un Processo decisionale di Markov (MDP), che consente l'uso di tecniche di programmazione dinamica. A differenza dei metodi classici di programmazione dinamica, gli algoritmi di RL non richiedono un modello matematico esatto dell'MDP e sono progettati per gestire problemi su larga scala in cui i metodi esatti non sono praticabili. Applicando le tecniche di apprendimento per rinforzo, gli agenti possono adattarsi e migliorare le loro capacità decisionali nel tempo, rendendolo un approccio potente per compiti come la navigazione autonoma, la robotica, il gioco e la gestione delle risorse.
Algoritmi e tecniche di apprendimento automatico
Gli algoritmi e le tecniche di apprendimento automatico offrono diverse capacità e vengono applicati in vari ambiti per risolvere problemi complessi. Ogni algoritmo ha i suoi punti di forza e di debolezza e la comprensione delle sue caratteristiche può aiutare i ricercatori e i professionisti a scegliere l'approccio più adatto per i loro compiti specifici. Sfruttando questi algoritmi, gli scienziati possono ottenere informazioni preziose dai dati e prendere decisioni informate nei loro rispettivi campi.
Foreste casuali
Le Foreste casuali sono un algoritmo popolare nell'apprendimento automatico che rientra nella categoria dell'apprendimento collettivo. Combina più alberi decisionali per fare previsioni o classificare i dati. Ogni albero decisionale della foresta casuale viene addestrato su un diverso sottoinsieme di dati e la previsione finale viene determinata aggregando le previsioni di tutti i singoli alberi. Le foreste casuali sono note per la loro capacità di gestire insiemi di dati complessi, fornire previsioni accurate e gestire i valori mancanti. Sono ampiamente utilizzate in vari campi, tra cui la finanza, la sanità e il riconoscimento delle immagini.
Algoritmo di apprendimento profondo
Il deep learning è un sottoinsieme dell'apprendimento automatico che si concentra sull'addestramento di reti neurali artificiali con più strati per apprendere rappresentazioni di dati. Gli algoritmi di apprendimento profondo, come Reti neurali convoluzionali (CNN) e Reti neurali ricorrenti (RNN), hanno ottenuto un notevole successo in attività quali il riconoscimento delle immagini e del parlato, l'elaborazione del linguaggio naturale e i sistemi di raccomandazione. Gli algoritmi di apprendimento profondo sono in grado di apprendere automaticamente caratteristiche gerarchiche dai dati grezzi, consentendo loro di catturare modelli intricati e di fare previsioni altamente accurate. Tuttavia, gli algoritmi di deep learning richiedono grandi quantità di dati etichettati e notevoli risorse computazionali per l'addestramento. Per saperne di più sull'apprendimento profondo, accedi al sito Sito web IBM.
Processi gaussiani
I processi gaussiani sono una tecnica potente utilizzata nell'apprendimento automatico per modellare e fare previsioni basate su distribuzioni di probabilità. Sono particolarmente utili quando si ha a che fare con insiemi di dati piccoli e rumorosi. I processi gaussiani forniscono un approccio flessibile e non parametrico, in grado di modellare relazioni complesse tra le variabili senza formulare forti ipotesi sulla distribuzione dei dati sottostanti. Sono comunemente utilizzati nei problemi di regressione, dove l'obiettivo è stimare un output continuo sulla base di caratteristiche di input. I processi gaussiani trovano applicazione in campi quali la geostatistica, la finanza e l'ottimizzazione.
Applicazione dell'apprendimento automatico nella scienza
L'applicazione dell'apprendimento automatico nella scienza apre nuove strade per la ricerca, consentendo agli scienziati di affrontare problemi complessi, scoprire modelli e fare previsioni basate su insiemi di dati grandi e diversi. Sfruttando la potenza dell'apprendimento automatico, gli scienziati possono ottenere approfondimenti, accelerare le scoperte scientifiche e far progredire le conoscenze in vari ambiti scientifici.
Imaging medico
L'apprendimento automatico ha dato un contributo significativo all'imaging medico, rivoluzionando le capacità diagnostiche e prognostiche. Gli algoritmi di apprendimento automatico possono analizzare immagini mediche come radiografie, risonanze magnetiche e TAC per aiutare a rilevare e diagnosticare varie malattie e condizioni. Possono aiutare a identificare le anomalie, a segmentare gli organi o i tessuti e a prevedere gli esiti dei pazienti. Sfruttando l'apprendimento automatico nell'imaging medico, gli operatori sanitari possono migliorare l'accuratezza e l'efficienza delle loro diagnosi, con conseguente miglioramento dell'assistenza ai pazienti e della pianificazione dei trattamenti.
Apprendimento attivo
L'apprendimento attivo è una tecnica di apprendimento automatico che consente all'algoritmo di interrogare interattivamente un essere umano o un oracolo per ottenere dati etichettati. Nella ricerca scientifica, l'apprendimento attivo può essere prezioso quando si lavora con insiemi di dati etichettati limitati o quando il processo di annotazione è lungo o costoso. Selezionando in modo intelligente le istanze più informative per l'etichettatura, gli algoritmi di apprendimento attivo possono ottenere un'elevata precisione con un numero inferiore di esempi etichettati, riducendo l'onere dell'annotazione manuale e accelerando la scoperta scientifica.
Applicazioni scientifiche
L'apprendimento automatico trova applicazioni diffuse in varie discipline scientifiche. Nella genomica, gli algoritmi di apprendimento automatico possono analizzare le sequenze di DNA e RNA per identificare le variazioni genetiche, prevedere le strutture delle proteine e comprendere le funzioni dei geni. Nella scienza dei materiali, l'apprendimento automatico viene impiegato per progettare nuovi materiali con le proprietà desiderate, accelerare la scoperta dei materiali e ottimizzare i processi di produzione. Le tecniche di apprendimento automatico sono utilizzate anche nelle scienze ambientali per prevedere e monitorare i livelli di inquinamento, le previsioni meteorologiche e l'analisi dei dati climatici. Inoltre, svolgono un ruolo cruciale in fisica, chimica, astronomia e in molti altri campi scientifici, consentendo la modellazione, la simulazione e l'analisi basate sui dati.
Vantaggi dell'apprendimento automatico nella scienza
I vantaggi dell'apprendimento automatico in ambito scientifico sono numerosi e di grande impatto. Ecco alcuni vantaggi chiave:
Modellazione predittiva avanzata: Gli algoritmi di apprendimento automatico possono analizzare insiemi di dati grandi e complessi per identificare modelli, tendenze e relazioni che potrebbero non essere facilmente riconoscibili attraverso i metodi statistici tradizionali. Ciò consente agli scienziati di sviluppare modelli predittivi accurati per vari fenomeni ed esiti scientifici, portando a previsioni più precise e a un migliore processo decisionale.
Maggiore efficienza e automazione: Le tecniche di apprendimento automatico automatizzano i compiti ripetitivi e dispendiosi in termini di tempo, consentendo agli scienziati di concentrarsi su aspetti più complessi e creativi della ricerca. Gli algoritmi di apprendimento automatico possono gestire grandi quantità di dati, eseguire analisi rapide e generare intuizioni e conclusioni in modo efficiente. Questo porta a una maggiore produttività e accelera il ritmo delle scoperte scientifiche.
Miglioramento dell'analisi e dell'interpretazione dei dati: Gli algoritmi di apprendimento automatico eccellono nell'analisi dei dati, consentendo agli scienziati di estrarre preziose intuizioni da insiemi di dati ampi ed eterogenei. Possono identificare schemi nascosti, correlazioni e anomalie che potrebbero non essere immediatamente evidenti ai ricercatori umani. Le tecniche di apprendimento automatico aiutano anche l'interpretazione dei dati fornendo spiegazioni, visualizzazioni e sintesi, facilitando una comprensione più profonda di fenomeni scientifici complessi.
Supporto decisionale facilitato: I modelli di apprendimento automatico possono servire come strumenti di supporto alle decisioni per gli scienziati. Analizzando i dati storici e le informazioni in tempo reale, gli algoritmi di apprendimento automatico possono aiutare nei processi decisionali, come la selezione delle vie di ricerca più promettenti, l'ottimizzazione dei parametri sperimentali o l'identificazione di potenziali rischi o sfide nei progetti scientifici. Ciò aiuta gli scienziati a prendere decisioni informate e aumenta le possibilità di ottenere risultati positivi.
Accelerazione della scoperta scientifica: L'apprendimento automatico accelera la scoperta scientifica consentendo ai ricercatori di esplorare grandi quantità di dati, generare ipotesi e convalidare teorie in modo più efficiente. Sfruttando gli algoritmi di apprendimento automatico, gli scienziati possono creare nuove connessioni, scoprire nuove intuizioni e identificare direzioni di ricerca che altrimenti sarebbero state trascurate. Questo porta a scoperte in vari campi scientifici e promuove l'innovazione.
Comunicare la scienza in modo visivo con il potere del miglior creatore di infografiche gratuito
Mind the Graph è una risorsa preziosa che aiuta gli scienziati a comunicare efficacemente e visivamente le loro ricerche. Grazie alla potenza del miglior creatore di infografiche gratuito, questa piattaforma consente agli scienziati di creare infografiche coinvolgenti e informative che rappresentano visivamente concetti e dati scientifici complessi. Che si tratti di presentare i risultati della ricerca, spiegare i processi scientifici o visualizzare le tendenze dei dati, la piattaforma Mind the Graph fornisce agli scienziati i mezzi per comunicare visivamente la loro scienza in modo chiaro e convincente. Iscrivetevi gratuitamente e iniziate subito a creare un progetto.





Iscriviti alla nostra newsletter
Contenuti esclusivi di alta qualità su visual efficaci
comunicazione nella scienza.