
V zadnjih letih je strojno učenje postalo močno orodje na področju znanosti in je korenito spremenilo način, kako raziskovalci raziskujejo in analizirajo kompleksne podatke. Strojno učenje je s svojo sposobnostjo samodejnega učenja vzorcev, napovedovanja in odkrivanja skritih spoznanj odprlo nove poti za znanstveno raziskovanje. Namen tega članka je poudariti ključno vlogo strojnega učenja v znanosti z raziskovanjem njegovega širokega spektra uporabe, napredka na tem področju in možnosti, ki jih ima za nadaljnja odkritja. Z razumevanjem delovanja strojnega učenja znanstveniki premikajo meje znanja, razkrivajo zapletene pojave in utirajo pot revolucionarnim inovacijam.
Kaj je strojno učenje?
Strojno učenje je veja Umetna inteligenca (AI), ki se osredotoča na razvoj algoritmov in modelov, ki računalnikom omogočajo, da se učijo iz podatkov in sprejemajo napovedi ali odločitve, ne da bi bili izrecno programirani. Vključuje študij statističnih in računalniških tehnik, ki računalnikom omogočajo samodejno analizo in razlago vzorcev, odnosov in odvisnosti v podatkih, kar vodi k pridobivanju dragocenih vpogledov in znanja.
Sorodni članki:: Umetna inteligenca v znanosti
Strojno učenje v znanosti
Strojno učenje je postalo močno orodje v različnih znanstvenih disciplinah in je korenito spremenilo način, kako raziskovalci analizirajo in razlagajo zapletene podatkovne nize. V znanosti se tehnike strojnega učenja uporabljajo za reševanje različnih izzivov, kot so napovedovanje strukture beljakovin, razvrščanje astronomskih objektov, modeliranje podnebnih vzorcev in prepoznavanje vzorcev v genetskih podatkih. Znanstveniki lahko algoritme strojnega učenja usposobijo za odkrivanje skritih vzorcev, natančne napovedi in globlje razumevanje zapletenih pojavov z uporabo velikih količin podatkov. Strojno učenje v znanosti ne povečuje le učinkovitosti in natančnosti analize podatkov, temveč odpira tudi nove poti za odkrivanje, kar raziskovalcem omogoča reševanje zapletenih znanstvenih vprašanj in pospeševanje napredka na njihovih področjih.
Vrste strojnega učenja
Nekatere vrste strojnega učenja zajemajo široko paleto pristopov in tehnik, ki so primerne za različna problemska področja in značilnosti podatkov. Raziskovalci in praktiki lahko izberejo najprimernejši pristop za svoje specifične naloge in izkoristijo moč strojnega učenja za pridobivanje vpogledov in sprejemanje informiranih odločitev. V nadaljevanju so predstavljene nekatere vrste strojnega učenja:
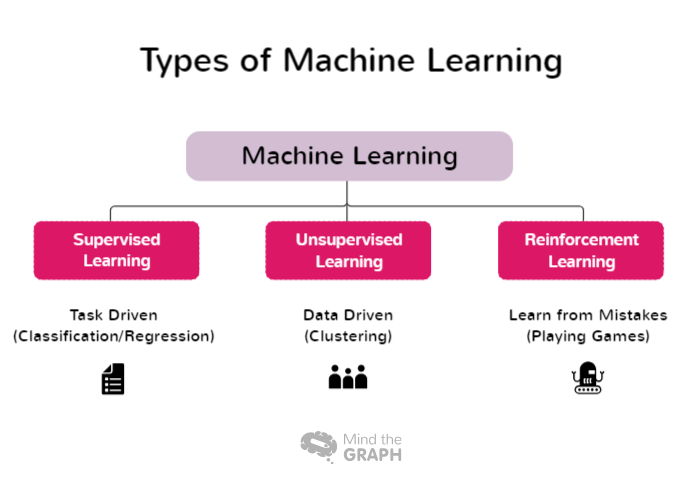
Nadzorovano učenje
Nadzorovano učenje je temeljni pristop v strojnem učenju, pri katerem se model uči z označenimi podatkovnimi nizi. V tem kontekstu se označeni podatki nanašajo na vhodne podatke, ki so povezani z ustreznimi izhodnimi ali ciljnimi oznakami. Cilj nadzorovanega učenja je omogočiti modelu, da se nauči vzorcev in razmerij med vhodnimi značilnostmi in ustreznimi oznakami, kar mu omogoča točne napovedi ali klasifikacije na novih, nevidenih podatkih.
Med postopkom učenja model iterativno prilagaja svoje parametre na podlagi zagotovljenih označenih podatkov in si prizadeva čim bolj zmanjšati razliko med napovedanimi rezultati in resničnimi oznakami. To modelu omogoča, da posplošuje in natančno napoveduje podatke, ki jih še ni videl. Nadzorovano učenje se pogosto uporablja v različnih aplikacijah, vključno s prepoznavanjem slik, prepoznavanjem govora, obdelavo naravnega jezika in napovedno analitiko.
Nenadzorovano učenje
Nenadzorovano učenje je veja strojnega učenja, ki se osredotoča na analizo in združevanje neoznačenih podatkovnih nizov brez uporabe vnaprej določenih ciljnih oznak. Pri nenadzorovanem učenju so algoritmi zasnovani tako, da samodejno zaznajo vzorce, podobnosti in razlike v podatkih. Z odkrivanjem teh skritih struktur nenadzorovano učenje raziskovalcem in organizacijam omogoča pridobivanje dragocenih vpogledov in sprejemanje odločitev, ki temeljijo na podatkih.
Ta pristop je še posebej uporaben pri raziskovalni analizi podatkov, kjer je cilj razumeti osnovno strukturo podatkov in ugotoviti morebitne vzorce ali povezave. Nenadzorovano učenje se uporablja tudi na različnih področjih, kot so segmentacija strank, odkrivanje anomalij, priporočilni sistemi in prepoznavanje slik.
Učenje z okrepitvijo
Učenje z okrepitvijo (RL) je veja strojnega učenja, ki se osredotoča na to, kako se lahko inteligentni agenti naučijo sprejemati optimalne odločitve v okolju, da bi povečali kumulativne nagrade. Za razliko od nadzorovanega učenja, ki temelji na označenih parih vhod/izhod, ali nenadzorovanega učenja, ki poskuša odkriti skrite vzorce, okrepljeno učenje deluje tako, da se uči iz interakcij z okoljem. Namen je najti ravnovesje med raziskovanjem, pri katerem agent odkriva nove strategije, in izkoriščanjem, pri katerem agent uporablja svoje trenutno znanje za sprejemanje informiranih odločitev.
Pri učenju z ojačitvami je okolje običajno opisano kot Markov proces odločanja (MDP), ki omogoča uporabo tehnik dinamičnega programiranja. Za razliko od klasičnih metod dinamičnega programiranja algoritmi RL ne zahtevajo natančnega matematičnega modela MDP in so zasnovani za reševanje obsežnih problemov, pri katerih so natančne metode nepraktične. Z uporabo tehnik okrepljenega učenja se lahko agenti sčasoma prilagodijo in izboljšajo svoje sposobnosti odločanja, zaradi česar je to učinkovit pristop za naloge, kot so avtonomna navigacija, robotika, igranje iger in upravljanje virov.
Algoritmi in tehnike strojnega učenja
Algoritmi in tehnike strojnega učenja ponujajo različne možnosti in se uporabljajo na različnih področjih za reševanje zapletenih problemov. Vsak algoritem ima svoje prednosti in slabosti, razumevanje njihovih značilnosti pa lahko raziskovalcem in praktikom pomaga pri izbiri najprimernejšega pristopa za njihove specifične naloge. Z uporabo teh algoritmov lahko znanstveniki iz podatkov pridobijo dragocene vpoglede in sprejemajo utemeljene odločitve na svojih področjih.
Naključni gozdovi
Naključni gozdovi so priljubljen algoritem v strojnem učenju, ki spada v kategorijo skupinskega učenja. Združuje več odločitvenih dreves za napovedovanje ali razvrščanje podatkov. Vsako odločitveno drevo v naključnem gozdu je usposobljeno na različnem podsklopu podatkov, končna napoved pa je določena z združitvijo napovedi vseh posameznih dreves. Naključni gozdovi so znani po tem, da lahko obdelujejo kompleksne nabore podatkov, zagotavljajo natančne napovedi in obravnavajo manjkajoče vrednosti. Široko se uporabljajo na različnih področjih, vključno s financami, zdravstvom in prepoznavanjem slik.
Algoritem globokega učenja
Globoko učenje je podvrsta strojnega učenja, ki se osredotoča na usposabljanje umetnih nevronskih mrež z več plastmi za učenje predstavitev podatkov. Algoritmi globokega učenja, kot so npr. Konvolucijske nevronske mreže (CNN) in Rekurentne nevronske mreže (RNN) so dosegli izjemen uspeh pri nalogah, kot so prepoznavanje slik in govora, obdelava naravnega jezika in priporočilni sistemi. Algoritmi globokega učenja se lahko samodejno naučijo hierarhičnih značilnosti iz neobdelanih podatkov, kar jim omogoča, da zajamejo zapletene vzorce in pripravijo zelo natančne napovedi. Vendar pa algoritmi globokega učenja za usposabljanje potrebujejo velike količine označenih podatkov in znatne računalniške vire. Če želite izvedeti več o globokem učenju, obiščite IBM-ova spletna stran.
Gaussovi procesi
Gaussovi procesi so močna tehnika, ki se uporablja v strojnem učenju za modeliranje in napovedovanje na podlagi verjetnostnih porazdelitev. Posebej uporabne so pri obravnavi majhnih in hrupnih podatkovnih nizov. Gaussovi procesi zagotavljajo prilagodljiv in neparametričen pristop, ki lahko modelira zapletene odnose med spremenljivkami brez močnih predpostavk o osnovni porazdelitvi podatkov. Pogosto se uporabljajo pri regresijskih problemih, kjer je cilj oceniti zvezni izhod na podlagi vhodnih značilnosti. Gaussovi procesi se uporabljajo na področjih, kot so geostatistika, finance in optimizacija.
Uporaba strojnega učenja v znanosti
Uporaba strojnega učenja v znanosti odpira nove možnosti za raziskave, saj znanstvenikom omogoča reševanje zapletenih problemov, odkrivanje vzorcev in napovedovanje na podlagi velikih in raznolikih zbirk podatkov. Z izkoriščanjem moči strojnega učenja lahko znanstveniki pridobijo globlje vpoglede, pospešijo znanstvena odkritja in pospešijo znanje na različnih znanstvenih področjih.
Medicinsko slikanje
Strojno učenje je pomembno prispevalo k medicinskemu slikanju ter revolucionarno spremenilo diagnostične in prognostične zmogljivosti. Algoritmi strojnega učenja lahko analizirajo medicinske slike, kot so rentgenski posnetki, magnetna resonanca in računalniška tomografija, ter tako pomagajo pri odkrivanju in diagnosticiranju različnih bolezni in stanj. Pomagajo lahko pri prepoznavanju anomalij, segmentaciji organov ali tkiv ter napovedovanju izidov zdravljenja. Z uporabo strojnega učenja pri medicinskem slikanju lahko zdravstveni delavci povečajo natančnost in učinkovitost svojih diagnoz, kar vodi k boljši oskrbi bolnikov in načrtovanju zdravljenja.
Aktivno učenje
Aktivno učenje je tehnika strojnega učenja, ki algoritmu omogoča interaktivno poizvedovanje po označenih podatkih pri človeku ali oraklju. V znanstvenih raziskavah je aktivno učenje lahko koristno, kadar delamo z omejenimi nabori označenih podatkov ali kadar je postopek anotacije dolgotrajen ali drag. Z inteligentnim izbiranjem najbolj informativnih primerov za označevanje lahko algoritmi aktivnega učenja dosežejo visoko natančnost z manjšim številom označenih primerov, kar zmanjša breme ročne anotacije in pospeši znanstvena odkritja.
Znanstvene aplikacije
Strojno učenje se pogosto uporablja v različnih znanstvenih disciplinah. V genomiki lahko algoritmi strojnega učenja analizirajo zaporedja DNK in RNK za prepoznavanje genetskih variacij, napovedovanje strukture beljakovin in razumevanje funkcij genov. V znanosti o materialih se strojno učenje uporablja za načrtovanje novih materialov z želenimi lastnostmi, pospeševanje odkrivanja materialov in optimizacijo proizvodnih procesov. Tehnike strojnega učenja se uporabljajo tudi v znanosti o okolju za napovedovanje in spremljanje ravni onesnaženosti, napovedovanje vremena in analizo podnebnih podatkov. Poleg tega ima ključno vlogo v fiziki, kemiji, astronomiji in na številnih drugih znanstvenih področjih, saj omogoča modeliranje, simulacijo in analizo na podlagi podatkov.
Prednosti strojnega učenja v znanosti
Prednosti strojnega učenja v znanosti so številne in vplivne. Tukaj je nekaj ključnih prednosti:
Izboljšano napovedno modeliranje: Algoritmi strojnega učenja lahko analizirajo velike in zapletene podatkovne nize ter prepoznajo vzorce, trende in povezave, ki jih s tradicionalnimi statističnimi metodami ni mogoče zlahka prepoznati. To znanstvenikom omogoča razvoj natančnih napovednih modelov za različne znanstvene pojave in rezultate, kar vodi k natančnejšim napovedim in boljšemu odločanju.
Večja učinkovitost in avtomatizacija: Tehnike strojnega učenja avtomatizirajo ponavljajoča se in dolgotrajna opravila, kar znanstvenikom omogoča, da se osredotočijo na bolj zapletene in ustvarjalne vidike raziskav. Algoritmi strojnega učenja lahko obdelajo velike količine podatkov, opravijo hitro analizo ter učinkovito ustvarijo vpoglede in zaključke. To vodi k večji produktivnosti in pospešuje hitrost znanstvenih odkritij.
Izboljšana analiza in interpretacija podatkov: Algoritmi strojnega učenja so odlični pri analizi podatkov, saj znanstvenikom omogočajo, da iz velikih in heterogenih zbirk podatkov pridobijo dragocene informacije. Prepoznajo lahko skrite vzorce, korelacije in anomalije, ki jih človeški raziskovalci morda ne bi takoj opazili. Tehnike strojnega učenja pomagajo tudi pri razlagi podatkov, saj zagotavljajo razlage, vizualizacije in povzetke, kar omogoča globlje razumevanje zapletenih znanstvenih pojavov.
Olajšana podpora pri odločanju: Modeli strojnega učenja lahko znanstvenikom služijo kot orodja za podporo pri odločanju. Algoritmi strojnega učenja lahko z analizo preteklih podatkov in informacij v realnem času pomagajo pri procesih odločanja, kot so izbira najbolj obetavnih raziskovalnih poti, optimizacija eksperimentalnih parametrov ali prepoznavanje morebitnih tveganj ali izzivov v znanstvenih projektih. To znanstvenikom pomaga pri sprejemanju informiranih odločitev in povečuje možnosti za doseganje uspešnih rezultatov.
Pospešeno znanstveno odkrivanje: Strojno učenje pospešuje znanstvena odkritja, saj raziskovalcem omogoča učinkovitejše raziskovanje velikih količin podatkov, ustvarjanje hipotez in potrjevanje teorij. Z uporabo algoritmov strojnega učenja lahko znanstveniki vzpostavijo nove povezave, odkrijejo nova spoznanja in opredelijo smeri raziskav, ki bi jih sicer morda spregledali. To vodi do prebojev na različnih znanstvenih področjih in spodbuja inovacije.
Vizualno sporočanje znanosti z močjo najboljšega in brezplačnega izdelovalca infografik
Mind the Graph je dragocen vir, ki znanstvenikom pomaga pri učinkovitem vizualnem sporočanju njihovih raziskav. Z močjo najboljšega in brezplačnega programa za izdelavo infografik ta platforma znanstvenikom omogoča ustvarjanje privlačnih in informativnih infografik, ki vizualno prikazujejo zapletene znanstvene koncepte in podatke. Ne glede na to, ali gre za predstavitev rezultatov raziskav, razlago znanstvenih procesov ali vizualizacijo podatkovnih trendov, platforma Mind the Graph znanstvenikom zagotavlja sredstva za jasno in prepričljivo vizualno sporočanje njihove znanosti. Brezplačno se prijavite in začnite ustvarjati zasnovo zdaj.





Naročite se na naše novice
Ekskluzivna visokokakovostna vsebina o učinkovitih vizualnih
komuniciranje v znanosti.