
În ultimii ani, învățarea automată a apărut ca un instrument puternic în domeniul științei, revoluționând modul în care cercetătorii explorează și analizează datele complexe. Datorită capacității sale de a învăța automat tipare, de a face predicții și de a descoperi informații ascunse, învățarea automată a deschis noi căi pentru cercetarea științifică. Acest articol are ca obiectiv evidențierea rolului crucial al învățării automate în știință prin explorarea gamei sale largi de aplicații, a progreselor realizate în acest domeniu și a potențialului pe care îl deține pentru noi descoperiri. Înțelegând funcționarea învățării automate, oamenii de știință împing limitele cunoașterii, deslușind fenomene complicate și deschizând calea pentru inovații revoluționare.
Ce este învățarea automată?
Machine Learning este o ramură a Inteligența artificială (AI) care se concentrează pe dezvoltarea de algoritmi și modele care permit calculatoarelor să învețe din date și să facă predicții sau să ia decizii fără a fi programate în mod explicit. Aceasta implică studiul tehnicilor statistice și computaționale care permit calculatoarelor să analizeze și să interpreteze automat modele, relații și dependențe în cadrul datelor, ceea ce duce la extragerea unor informații și cunoștințe valoroase.
Articol conex: Inteligența artificială în știință
Învățarea mașinilor în știință
Învățarea automată a apărut ca un instrument puternic în diverse discipline științifice, revoluționând modul în care cercetătorii analizează și interpretează seturi complexe de date. În domeniul științei, tehnicile de învățare automată sunt utilizate pentru a aborda diverse provocări, cum ar fi predicția structurilor proteice, clasificarea obiectelor astronomice, modelarea modelelor climatice și identificarea modelelor în datele genetice. Oamenii de știință pot antrena algoritmi de învățare automată pentru a descoperi tipare ascunse, pentru a face predicții precise și pentru a obține o înțelegere mai profundă a fenomenelor complexe, utilizând volume mari de date. Învățarea automată în știință nu numai că îmbunătățește eficiența și acuratețea analizei datelor, dar deschide și noi căi de descoperire, permițând cercetătorilor să abordeze întrebări științifice complexe și să accelereze progresele în domeniile lor respective.
Tipuri de Machine Learning
Unele tipuri de învățare automată acoperă o gamă largă de abordări și tehnici, fiecare dintre ele fiind potrivită pentru diferite domenii de probleme și caracteristici ale datelor. Cercetătorii și practicienii pot alege cea mai potrivită abordare pentru sarcinile lor specifice și pot valorifica puterea învățării automate pentru a extrage informații și a lua decizii în cunoștință de cauză. Iată câteva dintre tipurile de Machine Learning:
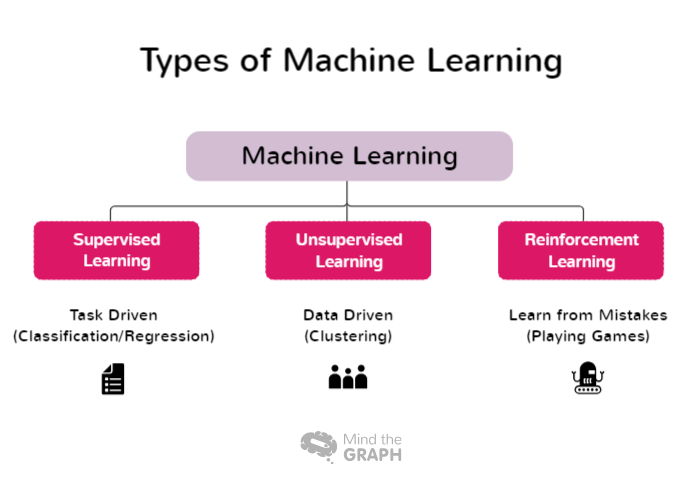
Învățare supravegheată
Învățarea supravegheată este o abordare fundamentală în învățarea automată în care modelul este antrenat folosind seturi de date etichetate. În acest context, datele etichetate se referă la datele de intrare care sunt asociate cu etichete de ieșire sau etichete țintă corespunzătoare. Scopul învățării supravegheate este de a permite modelului să învețe tipare și relații între caracteristicile de intrare și etichetele lor corespunzătoare, permițându-i să facă predicții sau clasificări precise pe date noi, nevăzute.
În timpul procesului de instruire, modelul își ajustează parametrii în mod iterativ pe baza datelor etichetate furnizate, încercând să minimizeze diferența dintre ieșirile sale prezise și etichetele reale. Acest lucru permite modelului să se generalizeze și să facă predicții precise pentru datele nevăzute. Învățarea supravegheată este utilizată pe scară largă în diverse aplicații, inclusiv recunoașterea imaginilor, recunoașterea vorbirii, procesarea limbajului natural și analiza predictivă.
Învățare nesupravegheată
Învățarea nesupravegheată este o ramură a învățării automate care se concentrează pe analiza și gruparea seturilor de date neetichetate fără a utiliza etichete țintă predefinite. În cadrul învățării nesupravegheate, algoritmii sunt concepuți pentru a detecta automat tipare, similitudini și diferențe în cadrul datelor. Prin descoperirea acestor structuri ascunse, învățarea nesupravegheată permite cercetătorilor și organizațiilor să obțină informații valoroase și să ia decizii bazate pe date.
Această abordare este deosebit de utilă în analiza exploratorie a datelor, unde obiectivul este de a înțelege structura de bază a datelor și de a identifica modele sau relații potențiale. Învățarea nesupravegheată își găsește, de asemenea, aplicații în diverse domenii, cum ar fi segmentarea clienților, detectarea anomaliilor, sistemele de recomandare și recunoașterea imaginilor.
Învățarea prin întărire
Învățarea prin întărire (RL) este o ramură a învățării automate care se concentrează pe modul în care agenții inteligenți pot învăța să ia decizii optime într-un mediu pentru a maximiza recompensele cumulative. Spre deosebire de învățarea supravegheată, care se bazează pe perechi de intrări/ieșiri etichetate, sau de învățarea nesupravegheată, care încearcă să descopere modele ascunse, învățarea prin consolidare funcționează prin învățarea din interacțiunile cu mediul. Intenția este de a găsi un echilibru între explorare, în care agentul descoperă noi strategii, și exploatare, în care agentul își valorifică cunoștințele actuale pentru a lua decizii în cunoștință de cauză.
În învățarea prin întărire, mediul este de obicei descris ca un Proces de decizie Markov (MDP), care permite utilizarea tehnicilor de programare dinamică. Spre deosebire de metodele clasice de programare dinamică, algoritmii RL nu necesită un model matematic exact al MDP și sunt concepuți pentru a gestiona probleme de mari dimensiuni în care metodele exacte sunt nepractice. Prin aplicarea tehnicilor de învățare prin întărire, agenții se pot adapta și își pot îmbunătăți abilitățile de luare a deciziilor în timp, ceea ce face ca această abordare să fie una puternică pentru sarcini precum navigația autonomă, robotica, jocurile și gestionarea resurselor.
Algoritmi și tehnici de învățare automată
Algoritmii și tehnicile de învățare automată oferă capacități diverse și sunt aplicate în diverse domenii pentru a rezolva probleme complexe. Fiecare algoritm are propriile puncte forte și puncte slabe, iar înțelegerea caracteristicilor acestora poate ajuta cercetătorii și practicienii să aleagă cea mai potrivită abordare pentru sarcinile lor specifice. Prin utilizarea acestor algoritmi, cercetătorii pot debloca informații valoroase din date și pot lua decizii în cunoștință de cauză în domeniile lor respective.
Păduri aleatorii
Random Forests este un algoritm popular în învățarea automată care se încadrează în categoria învățării de ansamblu. Acesta combină mai mulți arbori de decizie pentru a face predicții sau a clasifica datele. Fiecare arbore de decizie din pădurea aleatorie este antrenat pe un subset diferit de date, iar predicția finală este determinată prin agregarea predicțiilor tuturor arborilor individuali. Pădurile aleatorii sunt cunoscute pentru capacitatea lor de a gestiona seturi de date complexe, de a oferi predicții precise și de a gestiona valorile lipsă. Acestea sunt utilizate pe scară largă în diverse domenii, inclusiv în finanțe, sănătate și recunoașterea imaginilor.
Algoritm de învățare profundă
Învățarea profundă este un subansamblu al învățării automate care se concentrează pe instruirea rețelelor neuronale artificiale cu mai multe straturi pentru a învăța reprezentări ale datelor. Algoritmii de învățare profundă, cum ar fi Rețele neuronale convoluționale (CNN) și Rețele neuronale recurente (RNN), au înregistrat un succes remarcabil în sarcini precum recunoașterea imaginilor și a vorbirii, procesarea limbajului natural și sistemele de recomandare. Algoritmii de învățare profundă pot învăța automat caracteristici ierarhice din datele brute, permițându-le să capteze modele complexe și să facă predicții foarte precise. Cu toate acestea, algoritmii de învățare aprofundată necesită cantități mari de date etichetate și resurse de calcul substanțiale pentru instruire. Pentru a afla mai multe despre învățarea profundă, accesați Site-ul IBM.
Procese gaussiene
Procesele gaussiene sunt o tehnică puternică utilizată în învățarea automată pentru modelarea și realizarea de predicții bazate pe distribuții de probabilitate. Acestea sunt deosebit de utile atunci când se lucrează cu seturi de date mici și zgomotoase. Procesele gaussiene oferă o abordare flexibilă și neparametrică care poate modela relații complexe între variabile fără a face presupuneri puternice cu privire la distribuția de bază a datelor. Acestea sunt utilizate în mod obișnuit în probleme de regresie, unde obiectivul este de a estima o ieșire continuă pe baza caracteristicilor de intrare. Procesele gaussiene au aplicații în domenii precum geostatistica, finanțele și optimizarea.
Aplicarea învățării automate în știință
Aplicarea învățării automate în știință deschide noi căi de cercetare, permițând oamenilor de știință să abordeze probleme complexe, să descopere modele și să facă predicții pe baza unor seturi de date mari și diverse. Prin valorificarea puterii învățării automate, oamenii de știință pot obține perspective mai profunde, pot accelera descoperirile științifice și pot avansa cunoștințele în diverse domenii științifice.
Imagistică medicală
Învățarea mecanică a adus contribuții semnificative în domeniul imagisticii medicale, revoluționând capacitățile de diagnosticare și prognostic. Algoritmii de învățare automată pot analiza imaginile medicale, cum ar fi radiografiile, RMN-urile și tomografiile, pentru a ajuta la detectarea și diagnosticarea diferitelor boli și afecțiuni. Aceștia pot ajuta la identificarea anomaliilor, la segmentarea organelor sau a țesuturilor și la prezicerea rezultatelor pacienților. Prin valorificarea învățării automate în imagistica medicală, profesioniștii din domeniul sănătății pot spori acuratețea și eficiența diagnosticelor lor, ceea ce duce la o mai bună îngrijire a pacienților și la o mai bună planificare a tratamentului.
Învățare activă
Învățarea activă este o tehnică de învățare automată care permite algoritmului să interogheze în mod interactiv un om sau un oracol pentru date etichetate. În cercetarea științifică, învățarea activă poate fi valoroasă atunci când se lucrează cu seturi limitate de date etichetate sau când procesul de adnotare este costisitor sau consumator de timp. Prin selectarea inteligentă a celor mai informative instanțe pentru etichetare, algoritmii de învățare activă pot obține o precizie ridicată cu mai puține exemple etichetate, reducând povara adnotării manuale și accelerând descoperirile științifice.
Aplicații științifice
Învățarea automată găsește aplicații pe scară largă în diverse discipline științifice. În genomică, algoritmii de învățare automată pot analiza secvențele de ADN și ARN pentru a identifica variațiile genetice, pentru a prezice structurile proteinelor și pentru a înțelege funcțiile genelor. În știința materialelor, învățarea automată este utilizată pentru a proiecta noi materiale cu proprietățile dorite, pentru a accelera descoperirea materialelor și pentru a optimiza procesele de fabricație. Tehnicile de învățare automată sunt, de asemenea, utilizate în știința mediului pentru a prezice și monitoriza nivelurile de poluare, pentru a prognoza vremea și pentru a analiza datele climatice. În plus, joacă un rol crucial în fizică, chimie, astronomie și în multe alte domenii științifice, permițând modelarea, simularea și analiza bazate pe date.
Beneficiile învățării automate în știință
Beneficiile învățării automate în domeniul științei sunt numeroase și cu impact. Iată câteva avantaje cheie:
Modelare predictivă îmbunătățită: Algoritmii de învățare automată pot analiza seturi de date mari și complexe pentru a identifica modele, tendințe și relații care nu pot fi ușor de recunoscut prin metode statistice tradiționale. Acest lucru le permite oamenilor de știință să dezvolte modele predictive precise pentru diverse fenomene și rezultate științifice, ceea ce duce la previziuni mai precise și la îmbunătățirea procesului decizional.
Eficiență sporită și automatizare: Tehnicile de învățare automată automatizează sarcinile repetitive și consumatoare de timp, permițând oamenilor de știință să își concentreze eforturile asupra unor aspecte mai complexe și mai creative ale cercetării. Algoritmii de învățare automată pot gestiona cantități mari de date, pot efectua analize rapide și pot genera perspective și concluzii în mod eficient. Acest lucru duce la o productivitate sporită și accelerează ritmul descoperirilor științifice.
Îmbunătățirea analizei și interpretării datelor: Algoritmii de învățare automată excelează la analiza datelor, permițând oamenilor de știință să extragă informații valoroase din seturi de date mari și eterogene. Aceștia pot identifica tipare ascunse, corelații și anomalii care ar putea să nu fie imediat evidente pentru cercetătorii umani. De asemenea, tehnicile de învățare automată ajută la interpretarea datelor, oferind explicații, vizualizări și rezumate, facilitând o înțelegere mai profundă a fenomenelor științifice complexe.
Sprijin pentru luarea deciziilor facilitat: Modelele de învățare automată pot servi drept instrumente de sprijinire a deciziilor pentru oamenii de știință. Prin analiza datelor istorice și a informațiilor în timp real, algoritmii de învățare automată pot ajuta în procesele de luare a deciziilor, cum ar fi selectarea celor mai promițătoare căi de cercetare, optimizarea parametrilor experimentali sau identificarea potențialelor riscuri sau provocări în cadrul proiectelor științifice. Acest lucru îi ajută pe oamenii de știință să ia decizii în cunoștință de cauză și crește șansele de a obține rezultate de succes.
Accelerarea descoperirilor științifice: Învățarea automată accelerează descoperirea științifică, permițând cercetătorilor să exploreze cantități mari de date, să genereze ipoteze și să valideze teorii mai eficient. Prin utilizarea algoritmilor de învățare automată, oamenii de știință pot face noi conexiuni, pot descoperi perspective noi și pot identifica direcții de cercetare care altfel ar fi putut fi trecute cu vederea. Acest lucru duce la descoperiri în diverse domenii științifice și promovează inovarea.
Comunicați știința în mod vizual cu puterea celui mai bun și gratuit creator de infografice
Mind the Graph este o resursă valoroasă care îi ajută pe oamenii de știință să își comunice în mod eficient cercetările din punct de vedere vizual. Cu puterea celui mai bun și gratuit creator de infografice, această platformă permite oamenilor de știință să creeze infografice atractive și informative care descriu vizual concepte și date științifice complexe. Fie că este vorba de prezentarea rezultatelor cercetării, de explicarea proceselor științifice sau de vizualizarea tendințelor datelor, platforma Mind the Graph le oferă oamenilor de știință mijloacele de a-și comunica vizual știința în mod clar și convingător. Înscrieți-vă gratuit și începeți să creați un design acum.





Abonează-te la newsletter-ul nostru
Conținut exclusiv de înaltă calitate despre vizuale eficiente
comunicarea în domeniul științei.