
Regressionsanalyse er en metode til at identificere og analysere sammenhængen mellem en eller flere uafhængige variabler og en afhængig variabel. Denne metode bruges i vid udstrækning inden for en række discipliner, herunder sundhedspleje, samfundsvidenskab, ingeniørvidenskab, økonomi og forretning. Du kan bruge regressionsanalyse til at undersøge de grundlæggende relationer i data og udvikle prædiktive modeller, der hjælper dig med at træffe informerede beslutninger.
Denne artikel vil give dig et omfattende overblik over regressionsanalyse, herunder hvordan den fungerer, et letforståeligt eksempel, og den vil forklare, hvordan den adskiller sig fra korrelationsanalyse.
Hvad er regressionsanalyse?
Regressionsanalyse er en statistisk metode til at identificere og kvantificere forbindelsen mellem en afhængig variabel og en eller flere uafhængige variabler. I en nøddeskal hjælper den dig med at forstå, hvordan ændringer i en eller flere uafhængige variabler er relateret til ændringer i den afhængige variabel.
For at få en grundig forståelse af regressionsanalyse skal du først forstå følgende termer:
- Afhængig variabel: Dette er den variabel, som du er interesseret i at analysere eller forudsige. Det er den resultatvariabel, du forsøger at forstå og forklare.
- Uafhængige variabler: Det er de variabler, som du mener har en effekt på den afhængige variabel. De omtales ofte som prædiktorvariabler, da de bruges til at forudsige eller forklare ændringer i den afhængige variabel.
Regressionsanalyse kan bruges under en række omstændigheder, herunder til at forudsige fremtidige værdier af den afhængige variabel, til at forstå effekten af uafhængige variabler på den afhængige variabel og til at finde outliers eller usædvanlige forekomster i dataindsamlingen.
Regressionsanalyse kan klassificeres i flere typer, herunder enkelt lineær regression, logistisk regression, polynomisk regression og multipel regression. Den passende regressionsmodel bestemmes af dataenes art og undersøgelsens emne.
Hvordan fungerer regressionsanalyse?
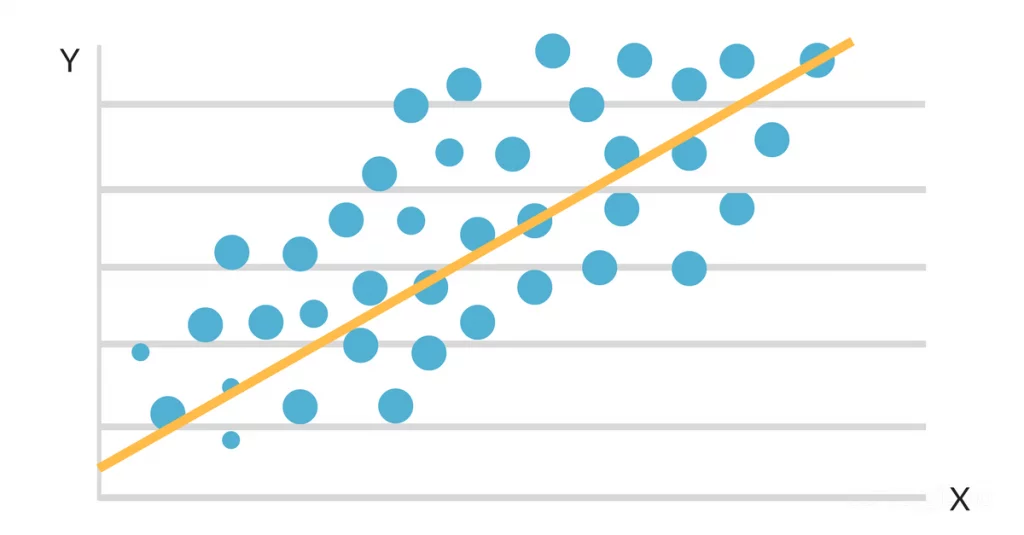
Formålet med regressionsanalyse er at identificere den bedst tilpassede linje eller kurve, der afspejler forbindelsen mellem de uafhængige variabler og den afhængige variabel. Denne bedst tilpassede linje eller kurve genereres ved hjælp af statistiske metoder, der reducerer forskellene mellem de forventede og reelle værdier i dataindsamlingen.
Her er formlerne for de to mest almindelige typer af regressionsanalyse:
Enkelt lineær regression
I simpel lineær regression bruger man en line of best fit til at vise forholdet mellem to variabler: den uafhængige variabel (x) og den afhængige variabel (y).
Den linje, der passer bedst, kan repræsenteres ved ligningen: y = a + bx.
Her er a skæringspunktet, og b er linjens hældning. For at udregne hældningen bruger man formlen: b = (nΣ(xy) - ΣxΣy) / (nΣ(x2) - (Σx)2), hvor n er antallet af observationer, Σxy er summen af produktet af x og y, Σx og Σy er summen af henholdsvis x og y, og Σ(x2) er summen af kvadraterne af x.
For at beregne skæringspunktet bruger du formlen: a = (Σy - bΣx) / n.
Multipel regression
Multipel lineær regression:
Formlen for ligningen for den multiple lineære regressionsmodel er:
y = b0 + b1x1 + b2x2 + ... + bnxn
hvor y er den afhængige variabel, x1, x2, ..., xn er de uafhængige variabler, og b0, b1, b2, ..., bn er koefficienterne for de uafhængige variabler.
Formlen for estimering af koefficienterne ved hjælp af almindelige mindste kvadraters metode er:
β = (X'X)(-1)X'y
hvor β er en kolonnevektor af koefficienter, X er designmatrixen af uafhængige variabler, X' er transponering af X, og y er vektoren af observationer af den afhængige variabel.
Eksempel på regressionsanalyse
Antag, at du ønsker at undersøge sammenhængen mellem en persons karaktergennemsnit (GPA) og antallet af timer, de læser om ugen. Du indsamler oplysninger fra en række studerende, herunder deres antal studietimer og karaktergennemsnit.
Brug derefter regressionsanalysen til at se, om der er en lineær forbindelse mellem begge variabler, og hvis det er tilfældet, kan du bygge en model, der forudsiger en studerendes gennemsnit baseret på antallet af timer, de læser om ugen.

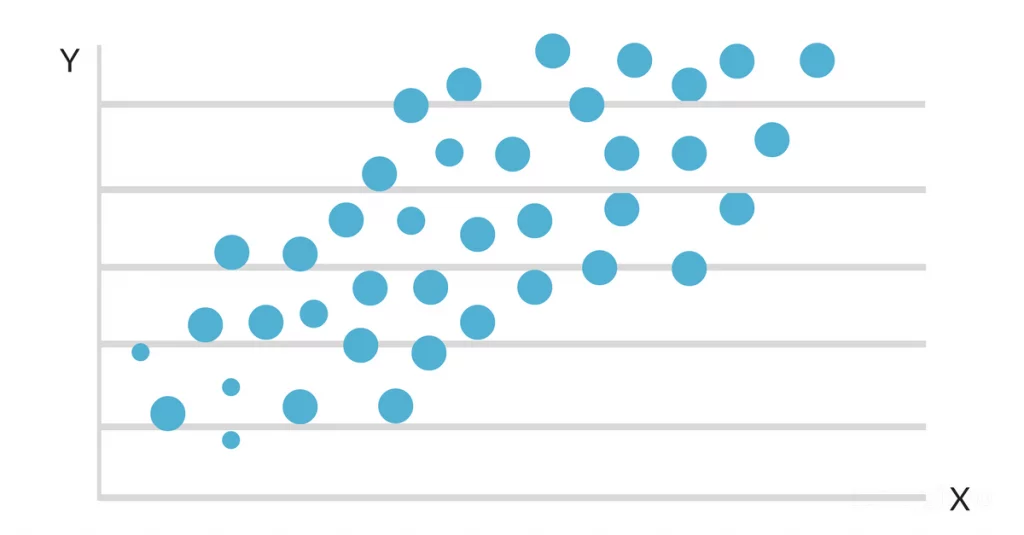
Når dataene plottes på et spredningskort, ser det ud til, at der er en gunstig lineær forbindelse mellem studietid og GPA. Hældningen og skæringspunktet for den linje, der passer bedst, estimeres derefter ved hjælp af en simpel lineær regressionsmodel. Den endelige løsning kunne se sådan ud:
GPA = 2,0 + 0,3 (studietimer pr. uge)
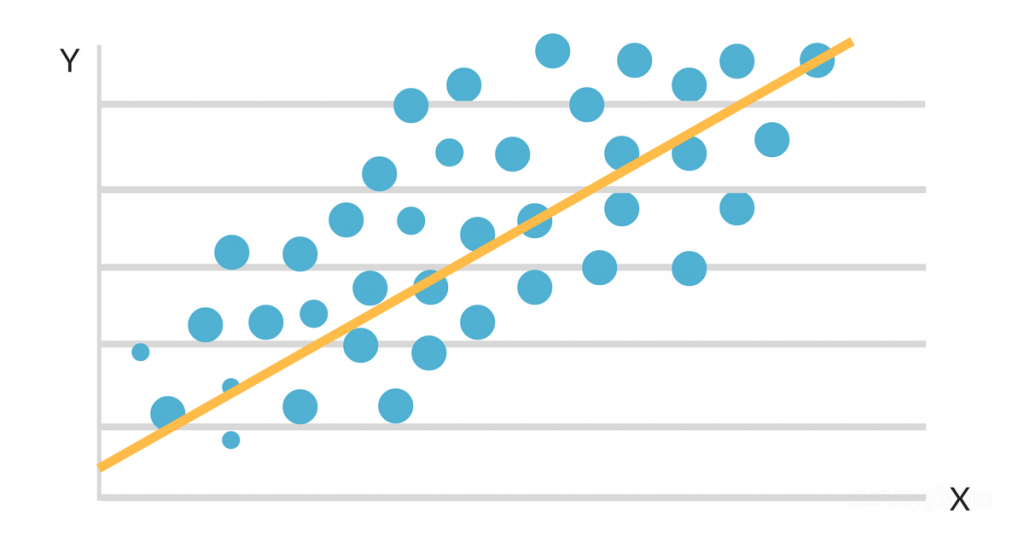
Denne ligning siger, at for hver ekstra times studier om ugen vil en studerendes gennemsnit stige med 0,3 point, når alt andet er lige. Denne algoritme kan bruges til at forudsige en studerendes GPA baseret på, hvor mange timer de studerer om ugen, samt til at identificere, hvilke studerende der er i risiko for at underpræstere baseret på deres studierutiner.
Ved hjælp af dataene fra eksemplet kan værdierne for b og a er som følger:
n = 10 (antallet af observationer)
Σx = 30 (summen af studietimerne)
Σy = 25 (summen af gennemsnitskaraktererne)
Σxy = 149 (summen af produktet af studietimer og GPA)
Σ(x)2 = 102 (summen af kvadraterne af studietimer)
Brug disse værdier til at beregne b som:
b = (nΣ(xy) - ΣxΣy) / (nΣ(x2) - (Σx)2)
= (10 * 149 – 30 * 25) / (10 * 102 – 302)
= 0.3
Og beregn a som:
a = (Σy - bΣx) / n
= (25 – 0.3 * 30) / 10
= 2.0
Derfor er ligningen for den linje, der passer bedst:
GPA = 2,0 + 0,3 (studietimer pr. uge)
Hvad er forskellen mellem korrelation og regression?
Både korrelation og regression er statistiske metoder til at undersøge sammenhængen mellem to variabler. De tjener forskellige formål og giver forskellige typer information.
Korrelation er et mål for styrken og forløbet af en forbindelse mellem to variabler. Den går fra -1 til +1, hvor -1 repræsenterer en perfekt negativ korrelation, 0 repræsenterer ingen korrelation, og +1 repræsenterer en perfekt positiv korrelation. Korrelation angiver, i hvor høj grad to variabler er forbundet, men det angiver ikke årsag eller forudsigelighed.
Regression er derimod en metode til at modellere forbindelsen mellem to variabler, typisk for at forudsige eller forklare den ene variabel baseret på den anden. Regressionsanalyse kan give estimater af forholdets størrelse og retning samt statistiske signifikanstests, konfidensintervaller og prognoser for fremtidige resultater.
Dine kreationer, klar på få minutter
Mind the Graph er en online platform, der tilbyder dig et omfattende bibliotek med videnskabelige illustrationer og infografiske designs, som du nemt kan ændre, så de opfylder dine unikke behov. Lav professionelt udseende diagrammer, plakater og grafiske abstracts på få minutter ved hjælp af en drag-and-drop-brugerflade og en lang række værktøjer og funktioner.



{kind=link}
{kind=link}

Tilmeld dig vores nyhedsbrev
Eksklusivt indhold af høj kvalitet om effektiv visuel
kommunikation inden for videnskab.