
Hypothese testen is een fundamenteel instrument dat gebruikt wordt in wetenschappelijk onderzoek om hypotheses over populatieparameters op basis van steekproefgegevens te valideren of te verwerpen. Het biedt een gestructureerd kader om de statistische significantie van een hypothese te evalueren en conclusies te trekken over de ware aard van een populatie. Hypothesetests worden veel gebruikt op gebieden zoals biologie, psychologie, economie en techniek om de effectiviteit van nieuwe behandelingen te bepalen, relaties tussen variabelen te onderzoeken en gegevensgestuurde beslissingen te nemen. Ondanks het belang ervan kan het testen van hypothesen echter een uitdagend onderwerp zijn om te begrijpen en correct toe te passen.
In dit artikel geven we een inleiding tot hypothesetests, inclusief het doel, de soorten tests, de betrokken stappen, veelgemaakte fouten en best practices. Of je nu een beginner of een ervaren onderzoeker bent, dit artikel zal dienen als een waardevolle gids om het testen van hypotheses in je werk onder de knie te krijgen.
Inleiding tot hypothesetests
Het testen van een hypothese is een statistisch hulpmiddel dat vaak in onderzoek wordt gebruikt om te bepalen of er voldoende bewijs is om een hypothese te ondersteunen of te verwerpen. Het gaat om het formuleren van een hypothese over een populatieparameter, het verzamelen van gegevens en het analyseren van de gegevens om te bepalen hoe waarschijnlijk het is dat de hypothese waar is. Het is een cruciaal onderdeel van de wetenschappelijke methode en wordt op veel verschillende gebieden gebruikt.
Het proces van hypothesetests omvat meestal twee hypothesen: de nulhypothese en de alternatieve hypothese. De nulhypothese is een verklaring dat er geen significant verschil is tussen twee variabelen of geen verband tussen hen, terwijl de alternatieve hypothese de aanwezigheid van een verband of verschil suggereert. Onderzoekers verzamelen gegevens en voeren statistische analyses uit om te bepalen of de nulhypothese kan worden verworpen ten gunste van de alternatieve hypothese.
Hypothesetests worden gebruikt om beslissingen te nemen op basis van gegevens en het is belangrijk om de onderliggende aannames en beperkingen van het proces te begrijpen. Het is cruciaal om de juiste statistische tests en steekproefgroottes te kiezen om ervoor te zorgen dat de resultaten nauwkeurig en betrouwbaar zijn, en het kan een krachtig hulpmiddel zijn voor onderzoekers om hun theorieën te valideren en op feiten gebaseerde beslissingen te nemen.

Soorten hypothesetests
Hypothesetests kunnen grofweg worden ingedeeld in twee categorieën: hypothesetests met één steekproef en hypothesetests met twee steekproeven. Laten we deze categorieën eens nader bekijken:
Hypothese testen met één steekproef
Bij een hypothesetest met één steekproef verzamelt een onderzoeker gegevens van één populatie en vergelijkt deze met een bekende waarde of hypothese. De nulhypothese gaat er meestal van uit dat er geen significant verschil is tussen de populatiegemiddelden en de bekende of veronderstelde waarde. De onderzoeker voert dan een statistische test uit om te bepalen of het waargenomen verschil statistisch significant is. Enkele voorbeelden van hypothesetests met één steekproef zijn:
Eén steekproef t-test: Deze test wordt gebruikt om te bepalen of het gemiddelde van de steekproef significant verschilt van het veronderstelde gemiddelde van de populatie.
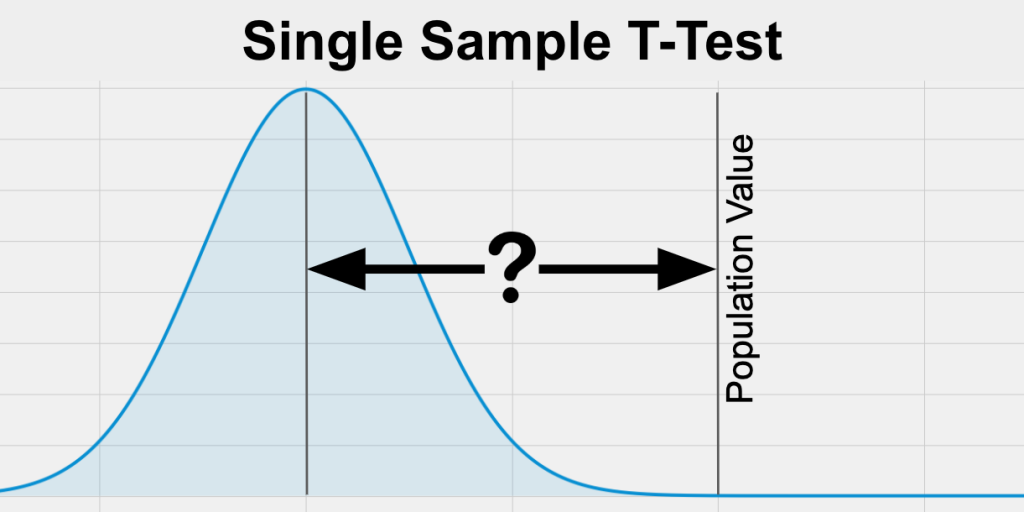
Eén steekproef z-test: Deze test wordt gebruikt om te bepalen of het gemiddelde van de steekproef significant verschilt van het veronderstelde gemiddelde van de populatie als de standaarddeviatie van de populatie bekend is.
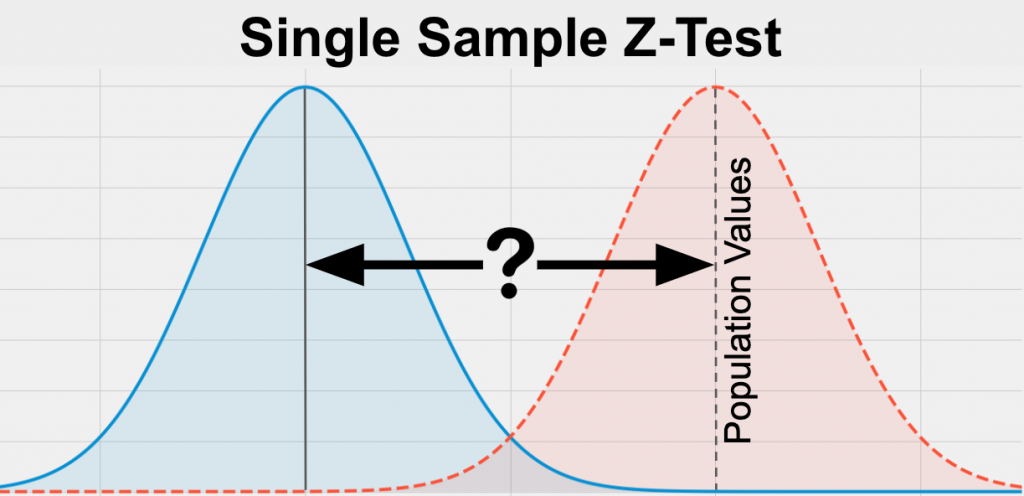
Hypothese testen met twee steekproeven
Bij een hypothesetest met twee steekproeven verzamelt een onderzoeker gegevens van twee verschillende populaties en vergelijkt deze met elkaar. De nulhypothese gaat er meestal van uit dat er geen significant verschil is tussen de twee populaties en de onderzoeker voert een statistische test uit om te bepalen of het waargenomen verschil statistisch significant is. Enkele voorbeelden van hypothesetests met twee steekproeven zijn:
Onafhankelijke steekproef t-test: Deze test wordt gebruikt om de gemiddelden van twee onafhankelijke steekproeven te vergelijken om te bepalen of ze significant van elkaar verschillen.
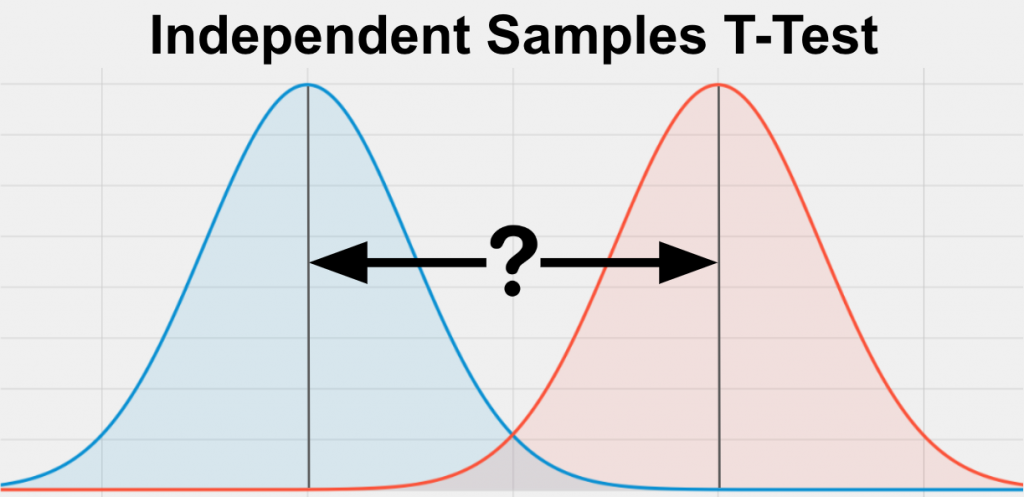
Gepaarde steekproef t-test: Deze test wordt gebruikt om de gemiddelden van twee verwante steekproeven te vergelijken, zoals pre-test en post-test scores van dezelfde groep proefpersonen.
Figuur: https://statstest.b-cdn.net/wp-content/uploads/2020/10/Paired-Samples-T-Test.jpg
Samengevat worden hypothesetests met één steekproef gebruikt om hypotheses over één populatie te testen, terwijl hypothesetests met twee steekproeven worden gebruikt om twee populaties te vergelijken. Welke test het meest geschikt is, hangt af van de aard van de gegevens en de onderzoeksvraag die wordt onderzocht.
Stappen van hypothesetests
Hypothesetests omvatten een reeks stappen die onderzoekers helpen bepalen of er voldoende bewijs is om een hypothese te ondersteunen of te verwerpen. Deze stappen kunnen grofweg in vier categorieën worden ingedeeld:
De hypothese formuleren
De eerste stap in hypothesetests is het formuleren van de nulhypothese en alternatieve hypothese. De nulhypothese gaat er meestal van uit dat er geen significant verschil is tussen twee variabelen, terwijl de alternatieve hypothese de aanwezigheid van een verband of verschil suggereert. Het is belangrijk om duidelijke en toetsbare hypothesen te formuleren voordat je verder gaat met het verzamelen van gegevens.
Gegevens verzamelen
De tweede stap is het verzamelen van relevante gegevens die gebruikt kunnen worden om de hypotheses te testen. Het gegevensverzamelingsproces moet zorgvuldig worden ontworpen om ervoor te zorgen dat de steekproef representatief is voor de populatie die van belang is. De steekproefgrootte moet groot genoeg zijn om statistisch geldige resultaten te produceren.
Gegevens analyseren
De derde stap is het analyseren van de gegevens met behulp van geschikte statistische toetsen. De keuze van de test hangt af van de aard van de gegevens en de onderzoeksvraag die wordt onderzocht. De resultaten van de statistische analyse geven informatie over de vraag of de nulhypothese kan worden verworpen ten gunste van de alternatieve hypothese.
Resultaten interpreteren
De laatste stap is het interpreteren van de resultaten van de statistische analyse. De onderzoeker moet bepalen of de resultaten statistisch significant zijn en of ze de hypothese ondersteunen of verwerpen. De onderzoeker moet ook rekening houden met de beperkingen van het onderzoek en de mogelijke implicaties van de resultaten.
Veelvoorkomende fouten bij hypothesetests
Hypothese testen is een statistische methode die gebruikt wordt om te bepalen of er genoeg bewijs is om een specifieke hypothese over een populatieparameter op basis van een steekproef van gegevens te ondersteunen of te verwerpen. De twee soorten fouten die kunnen optreden bij hypothesetests zijn:
Type I fout: Dit gebeurt wanneer de onderzoeker de nulhypothese verwerpt, ook al is deze waar. Type I fout staat ook bekend als vals positief.
Type II fout: Dit doet zich voor wanneer de onderzoeker er niet in slaagt de nulhypothese te verwerpen, hoewel deze vals is. Type II fout staat ook bekend als vals negatief.
Om deze fouten te minimaliseren is het belangrijk om het onderzoek zorgvuldig op te zetten en uit te voeren, de juiste statistische tests te kiezen en de resultaten goed te interpreteren. Onderzoekers moeten ook de beperkingen van hun onderzoek erkennen en rekening houden met mogelijke foutenbronnen bij het trekken van conclusies.
nulhypothesen en alternatieve hypothesen
Bij het testen van hypothesen zijn er twee soorten hypothesen: een nulhypothese en een alternatieve hypothese.
De nulhypothese
De nulhypothese (H0) is een verklaring die veronderstelt dat er geen significant verschil of verband is tussen twee variabelen. Het is de standaardhypothese die als waar wordt aangenomen totdat er voldoende bewijs is om hem te verwerpen. De nulhypothese wordt vaak geschreven als een verklaring van gelijkheid, zoals "het gemiddelde van groep A is gelijk aan het gemiddelde van groep B".
De alternatieve hypothese
De alternatieve hypothese (Ha) is een verklaring die de aanwezigheid van een significant verschil of verband tussen twee variabelen suggereert. Het is de hypothese die de onderzoeker wil testen. De alternatieve hypothese wordt vaak geschreven als een verklaring van ongelijkheid, zoals "het gemiddelde van groep A is niet gelijk aan het gemiddelde van groep B".
De nulhypothese en de alternatieve hypothese vullen elkaar aan en sluiten elkaar uit. Als de nulhypothese wordt verworpen, wordt de alternatieve hypothese aanvaard. Als de nulhypothese niet kan worden verworpen, wordt de alternatieve hypothese niet ondersteund.
Het is belangrijk op te merken dat de nulhypothese niet noodzakelijk waar is. Het is gewoon een verklaring die aanneemt dat er geen significant verschil of verband is tussen de variabelen die worden bestudeerd. Het doel van hypothesetests is om te bepalen of er voldoende bewijs is om de nulhypothese te verwerpen ten gunste van de alternatieve hypothese.
Significantieniveau en P-waarde
Bij het testen van hypothesen is het significantieniveau (alfa) de kans op een Type I fout, dat wil zeggen het verwerpen van de nulhypothese terwijl deze feitelijk waar is. Het meest gebruikte significantieniveau in wetenschappelijk onderzoek is 0,05, wat betekent dat er een kans van 5% is om een Type I fout te maken.
De p-waarde is een statistische maat die aangeeft hoe waarschijnlijk het is dat de waargenomen resultaten of extremere resultaten worden verkregen als de nulhypothese waar is. Het is een maat voor de sterkte van het bewijs tegen de nulhypothese. Een kleine p-waarde (meestal minder dan het gekozen significantieniveau van 0,05) suggereert dat er sterk bewijs tegen de nulhypothese is, terwijl een grote p-waarde suggereert dat er niet genoeg bewijs is om de nulhypothese te verwerpen.
Als de p-waarde kleiner is dan het significantieniveau (p alpha), dan wordt de nulhypothese niet verworpen en de alternatieve hypothese niet ondersteund.
Als je een eenvoudig te begrijpen samenvatting van het significantieniveau wilt, dan vind je die in dit artikel: Een gemakkelijk te begrijpen samenvatting van het significantieniveau.
Het is belangrijk op te merken dat statistische significantie niet noodzakelijkerwijs praktische significantie of belangrijkheid impliceert. Een klein verschil of verband tussen variabelen kan statistisch significant zijn, maar praktisch gezien niet. Bovendien hangt statistische significantie onder andere af van de grootte van de steekproef en de effectgrootte en moet deze worden geïnterpreteerd in de context van de onderzoeksopzet en de onderzoeksvraag.
Vermogensanalyse voor hypothesetests
Poweranalyse is een statistische methode die wordt gebruikt bij hypothesetests om de steekproefgrootte te bepalen die nodig is om een specifiek effect met een bepaalde mate van betrouwbaarheid te detecteren. De power van een statistische test is de kans op het correct verwerpen van de nulhypothese wanneer deze vals is of de kans op het vermijden van een Type II fout.
Een poweranalyse is belangrijk omdat het onderzoekers helpt de juiste steekproefgrootte te bepalen die nodig is om een gewenst powerniveau te bereiken. Een onderzoek met een lage power kan falen in het detecteren van een echt effect, wat leidt tot een Type II fout, terwijl een onderzoek met een hoge power meer kans heeft om een echt effect te detecteren, wat leidt tot nauwkeurigere en betrouwbaardere resultaten.
Om een poweranalyse uit te voeren, moeten onderzoekers het gewenste powerlevel, significantieniveau, effectgrootte en steekproefgrootte specificeren. De effectgrootte is een maat voor de grootte van het verschil of de relatie tussen variabelen die worden bestudeerd en wordt meestal geschat op basis van eerder onderzoek of pilotstudies. De machtsanalyse kan dan de noodzakelijke steekproefgrootte bepalen die nodig is om het gewenste machtsniveau te bereiken.
Een poweranalyse kan ook retrospectief worden gebruikt om de power van een afgerond onderzoek te bepalen, op basis van de steekproefgrootte, de effectgrootte en het significantieniveau. Dit kan onderzoekers helpen om de kracht van hun conclusies te evalueren en te bepalen of aanvullend onderzoek nodig is.
In het algemeen is poweranalyse een belangrijk hulpmiddel bij het testen van hypotheses, omdat het onderzoekers helpt bij het ontwerpen van onderzoeken met voldoende power om ware effecten te detecteren en type II-fouten te vermijden.
Bayesiaanse hypothesetest
Bayesiaanse hypothesetests zijn statistische methoden waarmee onderzoekers het bewijs voor en tegen concurrerende hypothesen kunnen evalueren op basis van de waarschijnlijkheid van de geobserveerde gegevens onder elke hypothese en de voorafgaande waarschijnlijkheid van elke hypothese. In tegenstelling tot klassieke hypothesetests, die zich richten op het verwerpen van nulhypothesen op basis van p-waarden, biedt Bayesiaanse hypothesetests een meer genuanceerde en informatieve benadering van hypothesetests, doordat onderzoekers de sterkte van het bewijs voor en tegen elke hypothese kunnen kwantificeren.
Bij Bayesiaanse hypothesetests beginnen onderzoekers met een prior-waarschijnlijkheidsverdeling voor elke hypothese, gebaseerd op bestaande kennis of overtuigingen. Vervolgens actualiseren ze de prior-kansverdeling op basis van de waarschijnlijkheid van de geobserveerde gegevens onder elke hypothese, met behulp van de stelling van Bayes. De resulterende posterior kansverdeling geeft de waarschijnlijkheid van elke hypothese weer, gegeven de geobserveerde gegevens.
De sterkte van het bewijs voor de ene hypothese versus de andere kan worden gekwantificeerd door de factor van Bayes te berekenen, die de verhouding is van de waarschijnlijkheid van de waargenomen gegevens onder de ene hypothese versus de andere, gewogen door hun voorafgaande waarschijnlijkheden. Een Bayes-factor groter dan 1 wijst op bewijs ten gunste van de ene hypothese, terwijl een Bayes-factor kleiner dan 1 wijst op bewijs ten gunste van de andere hypothese.
Bayesiaanse hypothesetests hebben verschillende voordelen ten opzichte van klassieke hypothesetests. Ten eerste stelt het onderzoekers in staat om hun prior beliefs bij te werken op basis van geobserveerde gegevens, wat kan leiden tot nauwkeurigere en betrouwbaardere conclusies. Ten tweede biedt het een informatievere maatstaf voor bewijs dan p-waarden, die alleen aangeven of de waargenomen gegevens statistisch significant zijn op een vooraf bepaald niveau. Tot slot kunnen complexe modellen met meerdere parameters en hypotheses worden gebruikt, die moeilijk te analyseren zijn met klassieke methoden.
In het algemeen is Bayesiaanse hypothesetesting een krachtige en flexibele statistische methode die onderzoekers kan helpen beter geïnformeerde beslissingen te nemen en nauwkeurigere conclusies uit hun gegevens te trekken.
Wetenschappelijk nauwkeurige infografieken maken in een paar minuten
Mind the Graph platform is een krachtige tool die wetenschappers helpt om op een eenvoudige manier wetenschappelijk accurate infographics te maken. Met zijn intuïtieve interface, aanpasbare sjablonen en uitgebreide bibliotheek van wetenschappelijke illustraties en pictogrammen, maakt Mind the Graph het onderzoekers gemakkelijk om professioneel ogende afbeeldingen te maken die hun bevindingen effectief communiceren naar een breder publiek.




Abonneer u op onze nieuwsbrief
Exclusieve inhoud van hoge kwaliteit over effectieve visuele
communicatie in de wetenschap.