
仮説検定は、標本データに基づいて母集団のパラメータに関する仮説を検証または棄却するために科学研究で使用される基本的なツールである。仮説の統計的有意性を評価し、母集団の真の性質に関する結論を導き出すための構造化された枠組みを提供する。仮説検定は、以下のような分野で広く使われている。 生物学、心理学、経済学、工学 新しい治療法の有効性を判断し、変数間の関係を探り、データに基づいた意思決定を行うためである。しかし、その重要性にもかかわらず、仮説検定は正しく理解し、適用するのが難しいテーマです。
この記事では、仮説検定の目的、検定の種類、手順、よくある間違い、ベストプラクティスなど、仮説検定について紹介します。あなたが初心者であろうと経験豊富な研究者であろうと、この記事はあなたの仕事で仮説検証をマスターするための貴重なガイドとなるでしょう。
仮説検定入門
仮説検定は、仮説を支持または棄却するのに十分な証拠があるかどうかを判断するために、研究で一般的に使用される統計ツールです。母集団のパラメータに関する仮説を立て、データを収集し、データを分析して仮説が真である可能性を判断する。科学的方法の重要な構成要素であり、幅広い分野で使用されている。
仮説検証のプロセスでは通常、帰無仮説と対立仮説という2つの仮説が用いられます。帰無仮説とは、2つの変数の間には有意な差がない、あるいは関係がないというもので、対立仮説は関係や差があることを示唆するものである。研究者はデータを収集し、帰無仮説が棄却されて対立仮説が支持されるかどうかを判断するために統計分析を行う。
仮説検定はデータに基づいて意思決定を行うために用いられるが、そのプロセスの基礎となる仮定と限界を理解することが重要である。結果が正確で信頼できるものであるためには、適切な統計的検定とサンプルサイズを選択することが極めて重要であり、研究者が理論を検証し、証拠に基づく意思決定を行うための強力なツールとなり得る。

仮説検定の種類
仮説検定は、1標本の仮説検定と2標本の仮説検定の2つに大別される。それぞれのカテゴリーを詳しく見てみよう:
一標本の仮説検定
1標本の仮説検定では、研究者は1つの集団からデータを収集し、既知の値または仮説と比較する。帰無仮説は通常、母集団の平均と既知の値または仮説の値との間に有意な差がないと仮定する。研究者は次に、観察された差が統計的に有意であるかどうかを決定するために統計的検定を行う。1標本の仮説検定の例をいくつか挙げる:
1標本のt検定: この検定は、標本平均が母集団の仮説平均と有意に異なるかどうかを決定するために使用される。
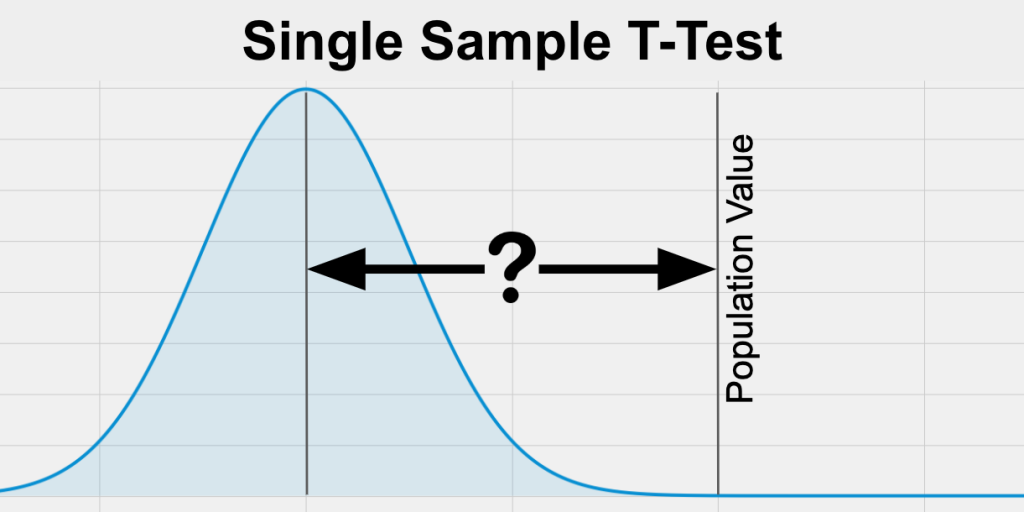
1標本のz検定: この検定は、母集団の標準偏差がわかっているときに、標本平均が母集団の仮説平均と有意に異なるかどうかを決定するのに使われる。
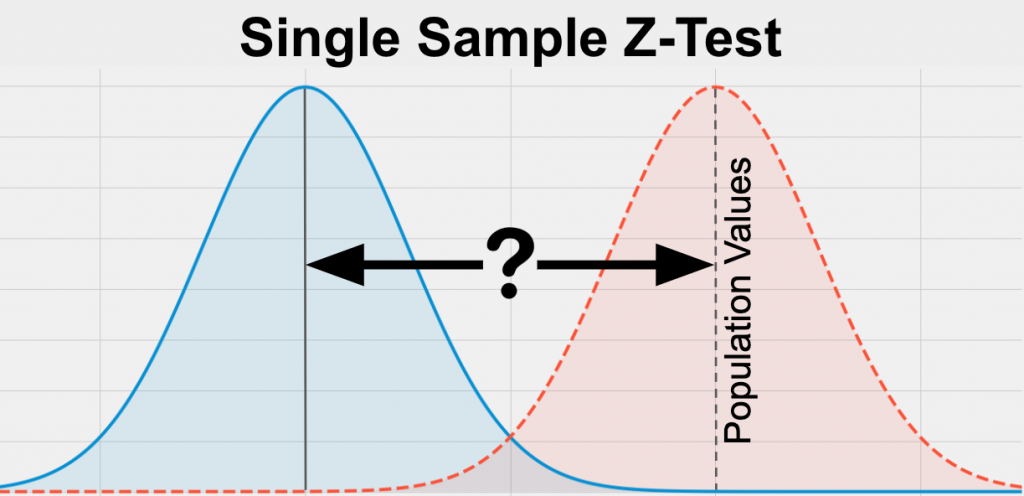
つのサンプル仮説検定
2標本の仮説検定では、研究者は2つの異なる集団からデータを収集し、それらを互いに比較する。帰無仮説は通常、2つの母集団の間に有意差がないと仮定し、研究者は観察された差が統計的に有意であるかどうかを決定するために統計的検定を実行する。2標本の仮説検定の例をいくつか挙げる:
独立標本のt検定: この検定は、2つの独立標本の平均を比較し、それらが互いに有意に異なるかどうかを決定するために使用される。
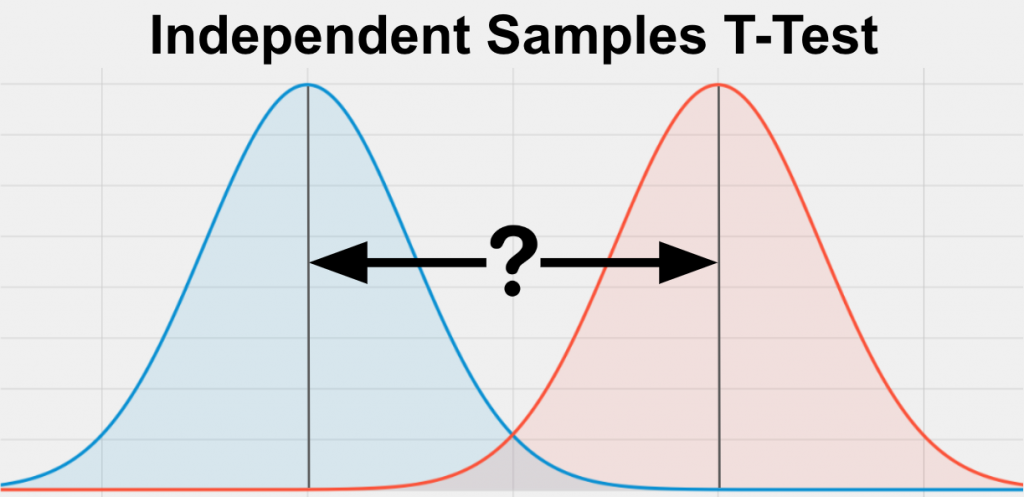
対の標本のt検定: この検定は、同じ被験者グループのテスト前とテスト後の得点など、関連する2つの標本の平均を比較するのに使われる。
図 https://statstest.b-cdn.net/wp-content/uploads/2020/10/Paired-Samples-T-Test.jpg
要約すると、1標本の仮説検定は1つの母集団に関する仮説を検定するのに使われ、2標本の仮説検定は2つの母集団を比較するのに使われます。使用する適切な検定は、データの性質と調査される研究課題によって異なります。
仮説検証のステップ
仮説検証には、仮説を支持または棄却するのに十分な証拠があるかどうかを研究者が判断するための一連のステップが含まれる。これらのステップは、4つのカテゴリーに大別することができる:
仮説の策定
仮説検定の最初のステップは、帰無仮説と対立仮説を立てることである。帰無仮説は通常、2つの変数の間に有意差がないと仮定し、対立仮説は関係または差の存在を示唆する。データ収集を進める前に、明確で検証可能な仮説を立てることが重要である。
データ収集
第二段階は、仮説の検証に使用できる関連データを収集することである。データ収集のプロセスは、サンプルが対象母集団を代表するように注意深く設計されなければならない。サンプル・サイズは、統計的に有効な結果を出すのに十分な大きさでなければならない。
データの分析
第3のステップは、適切な統計検定を使ってデータを分析することである。どの検定を選択するかは、データの性質と調査する研究課題によって異なる。統計分析の結果は、帰無仮説が棄却され、対立仮説が支持されるかどうかの情報を提供する。
結果の解釈
最後のステップは、統計分析結果の解釈である。研究者は、結果が統計的に有意かどうか、仮説を支持するか棄却するかを判断する必要がある。研究者はまた、研究の限界と結果の潜在的な影響についても考慮する必要がある。
仮説検定でよくある誤り
仮説検定は、データの標本に基づいて、母集団のパラメータに関する特定の仮説を支持または棄却するのに十分な証拠があるかどうかを決定するために使用される統計的手法である。仮説検定で発生する可能性のあるエラーは2種類あります:
タイプIエラー: これは、帰無仮説が真であるにもかかわらず、研究者がそれを棄却する場合に起こる。タイプIエラーは偽陽性としても知られている。
第二種の過誤: 帰無仮説が偽であるにもかかわらず、それを棄却できない場合に起こる。II型過誤は偽陰性としても知られている。
このような誤差を最小限にするためには、慎重に研究を計画・実施し、適切な統計的検定を選択し、結果を適切に解釈することが重要である。研究者はまた、研究の限界を認識し、結論を導き出す際に潜在的な誤りの原因を考慮すべきである。
帰無仮説と対立仮説
仮説検定では、帰無仮説と対立仮説の2種類の仮説がある。
帰無仮説
帰無仮説(H0)とは、2つの変数の間に有意な差や関係がないと仮定する記述である。帰無仮説は、それを棄却する十分な証拠があるまで真であると仮定されるデフォルトの仮説です。帰無仮説は、"A群の平均はB群の平均と等しい "というように、しばしば等質性の記述として書かれる。
代替仮説
対立仮説(Ha)は、2つの変数の間に有意な差または関係があることを示唆する記述である。これは、研究者が検証することに関心がある仮説です。対立仮説は、"グループAの平均はグループBの平均と等しくない "というような不等式の記述として書かれることが多い。
帰無仮説と対立仮説は相補的であり、相互に排他的である。帰無仮説が棄却されれば、対立仮説が受け入れられる。帰無仮説が棄却できなければ、対立仮説は支持されない。
帰無仮説は必ずしも真ではないことに注意することが重要である。帰無仮説とは、研究対象の変数間に有意な差や関係がないと仮定する単なる声明である。仮説検定の目的は、帰無仮説を棄却して対立仮説を支持する十分な証拠があるかどうかを決定することである。
有意水準とP値
仮説検定では、有意水準(α)は帰無仮説が実際には真であるにもかかわらず、それを棄却するタイプIの誤りを犯す確率である。科学研究で最もよく使われる有意水準は0.05で、これは5%の確率でタイプIの誤りを犯すことを意味する。
p値は、帰無仮説が真である場合に、観察された結果またはより極端な結果が得られる確率を示す統計的尺度である。帰無仮説に対する証拠の強さの尺度である。小さいp値(通常、選択された有意水準0.05より小さい)は、帰無仮説に対する強い証拠があることを示唆し、大きいp値は、帰無仮説を棄却するのに十分な証拠がないことを示唆する。
p値が有意水準(p<アルファ)より小さければ、帰無仮説が棄却され、対立仮説が受け入れられる。これは、調査されている変数の間に有意な差または関係があることを示唆する十分な証拠があることを意味します。一方、p-値が有意水準(p > α)より大きければ、帰無仮説は棄却されず、対立仮説は支持されない。
有意水準についてわかりやすくまとめたい方は、こちらの記事をご覧ください: 有意水準についてわかりやすくまとめたもの.
統計的有意性は、必ずしも実際的有意性や重要性を意味しないことに注意することが重要である。変数間の小さな差や関係は、統計的に有意であっても、実際的には有意でない場合がある。さらに、統計的有意性は、他の要因の中でもサンプルサイズと効果量に依存し、研究デザインと研究課題の文脈で解釈されるべきである。
仮説検定のための検出力分析
検出力分析は、仮説検定で使用される統計的手法で、特定の効果量を一定の信頼度で検出するために必要なサンプル・サイズを決定する。統計的検定の検出力とは、帰無仮説が偽のときに正しく棄却される確率、またはII型過誤を回避できる確率のことである。
検出力分析が重要なのは、研究者が望ましい検出力レベルを達成するために必要な適切なサンプルサイズを決定するのに役立つからである。検出力が低い研究は、真の効果を検出できない可能性があり、タイプⅡのエラーにつながるが、検出力が高い研究は真の効果を検出できる可能性が高く、より正確で信頼できる結果につながる。
検出力分析を実施するために、研究者は望ましい検出力レベル、有意水準、効果量、標本サイズを特定する必要がある。効果量は、研究される変数間の差または関係の大きさの尺度であり、通常、先行研究またはパイロット・スタディから推定される。そして、検出力分析は、望ましい検出力レベルを達成するために必要なサンプルサイズを決定することができる。
検出力分析は、サンプルサイズ、効果量、有意水準に基づいて、完了した研究の検出力を決定するためにレトロスペクティブに使用することもできる。これは、研究者が結論の強さを評価し、追加研究が必要かどうかを判断するのに役立ちます。
全体として、検出力分析は仮説検定において重要なツールである。なぜなら、研究者が真の効果を検出し、II型過誤を回避するのに十分な検出力を持つ研究をデザインするのに役立つからである。
ベイズ仮説検定
ベイズ仮説検定は、研究者が各仮説の下で観測されたデータの尤度、および各仮説の事前確率に基づいて、競合する仮説に対する証拠を評価することを可能にする統計的手法である。p値に基づいて帰無仮説を棄却することに重点を置く古典的な仮説検定とは異なり、ベイズ仮説検定は、研究者が各仮説に対する証拠の強さを定量化できるようにすることで、仮説検定によりニュアンスがあり、有益なアプローチを提供する。
ベイズ仮説検定では、研究者は既存の知識や信念に基づいて、各仮説の事前確率分布から始める。次に、ベイズの定理を用いて、各仮説の下での観測データの尤度に基づいて事前確率分布を更新する。結果として得られる事後確率分布は、観測データが与えられた場合の各仮説の確率を表している。
ある仮説と別の仮説の証拠の強さは、ベイズ係数を計算することで定量化できる。ベイズ係数は、ある仮説と別の仮説の下で観測されたデータの尤度を、それらの事前確率で重み付けした比率である。ベイズ係数が1より大きいと一方の仮説を支持する証拠となり、ベイズ係数が1より小さいと他方の仮説を支持する証拠となる。
ベイズ仮説検定には、古典的仮説検定に比べていくつかの利点がある。第一に、研究者が観察されたデータに基づいて事前信念を更新することを可能にし、より正確で信頼できる結論に導くことができる。第二に、観察されたデータが所定の水準で統計的に有意であるかどうかを示すだけのp値よりも、より有益な証拠の尺度を提供する。最後に、古典的な手法では分析が困難な、複数のパラメータと仮説を持つ複雑なモデルにも対応できる。
全体として、ベイズ仮説検定は、研究者がより多くの情報に基づいた意思決定を行い、データからより正確な結論を導き出すのに役立つ、強力で柔軟な統計手法である。
科学的に正確なインフォグラフィックを数分で作る
Mind the Graph プラットフォームは、科学者が科学的に正確なインフォグラフィックスを簡単に作成できる強力なツールです。直感的なインターフェイス、カスタマイズ可能なテンプレート、科学的なイラストやアイコンの豊富なライブラリにより、Mind the Graphは、研究者がより多くの聴衆に効果的に研究結果を伝えるプロフェッショナルなグラフィックを簡単に作成できるようにします。




ニュースレターを購読する
効果的なビジュアルに関する高品質なコンテンツを独占配信
科学におけるコミュニケーション