
I de senere år har maskinlæring udviklet sig til et stærkt værktøj inden for videnskaben og revolutioneret den måde, hvorpå forskere udforsker og analyserer komplekse data. Med sin evne til automatisk at lære mønstre, lave forudsigelser og afdække skjulte indsigter har machine learning åbnet nye veje for videnskabelige undersøgelser. Denne artikel har til formål at fremhæve maskinlæringens afgørende rolle i videnskaben ved at udforske dens brede vifte af anvendelser, de fremskridt, der er gjort på dette område, og det potentiale, det har for yderligere opdagelser. Ved at forstå, hvordan machine learning fungerer, skubber forskere til grænserne for viden, opklarer indviklede fænomener og baner vejen for banebrydende innovationer.
Hvad er maskinlæring?
Machine Learning er en gren af Kunstig intelligens (AI), der fokuserer på at udvikle algoritmer og modeller, der gør det muligt for computere at lære af data og træffe forudsigelser eller beslutninger uden at være eksplicit programmeret. Det involverer studiet af statistiske og beregningsmæssige teknikker, der gør det muligt for computere automatisk at analysere og fortolke mønstre, relationer og afhængigheder inden for data, hvilket fører til udvinding af værdifuld indsigt og viden.
Relateret artikel: Kunstig intelligens i videnskaben
Maskinlæring i videnskaben
Machine Learning har vist sig at være et stærkt værktøj inden for forskellige videnskabelige discipliner og har revolutioneret den måde, hvorpå forskere analyserer og fortolker komplekse datasæt. I videnskaben anvendes Machine Learning-teknikker til at tackle forskellige udfordringer, såsom at forudsige proteinstrukturer, klassificere astronomiske objekter, modellere klimamønstre og identificere mønstre i genetiske data. Forskere kan træne Machine Learning-algoritmer til at afdække skjulte mønstre, lave præcise forudsigelser og få en dybere forståelse af komplekse fænomener ved at bruge store mængder data. Machine Learning i videnskaben forbedrer ikke kun effektiviteten og nøjagtigheden af dataanalysen, men åbner også op for nye måder at gå på opdagelse på, så forskerne kan løse komplekse videnskabelige spørgsmål og fremskynde udviklingen inden for deres respektive områder.
Typer af maskinlæring
Nogle typer Machine Learning dækker over en bred vifte af tilgange og teknikker, der hver især passer til forskellige problemdomæner og dataegenskaber. Forskere og praktikere kan vælge den mest passende tilgang til deres specifikke opgaver og udnytte kraften i Machine Learning til at udtrække indsigt og træffe informerede beslutninger. Her er nogle af typerne af Machine Learning:
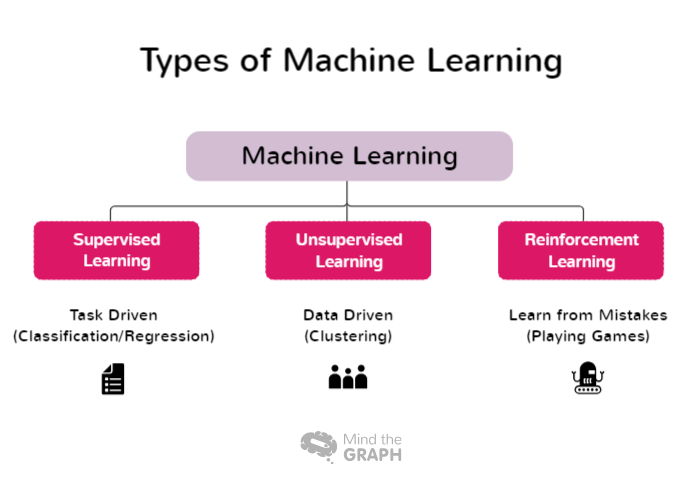
Overvåget læring
Supervised learning er en grundlæggende tilgang inden for maskinlæring, hvor modellen trænes ved hjælp af mærkede datasæt. I denne sammenhæng henviser mærkede data til inputdata, der er parret med tilsvarende output- eller målmærkater. Målet med supervised learning er at gøre det muligt for modellen at lære mønstre og relationer mellem inputfunktionerne og deres tilsvarende labels, så den kan lave nøjagtige forudsigelser eller klassifikationer på nye, usete data.
Under træningsprocessen justerer modellen iterativt sine parametre baseret på de leverede mærkede data og stræber efter at minimere forskellen mellem dens forudsagte output og de sande mærkninger. Det gør modellen i stand til at generalisere og komme med præcise forudsigelser på usete data. Supervised learning bruges i vid udstrækning i forskellige applikationer, herunder billedgenkendelse, talegenkendelse, naturlig sprogbehandling og prædiktiv analyse.
Læring uden opsyn
Unsupervised learning er en gren af machine learning, der fokuserer på at analysere og gruppere umærkede datasæt uden brug af foruddefinerede målmærkater. I unsupervised learning er algoritmerne designet til automatisk at opdage mønstre, ligheder og forskelle i dataene. Ved at afdække disse skjulte strukturer gør unsupervised learning det muligt for forskere og organisationer at få værdifuld indsigt og træffe datadrevne beslutninger.
Denne tilgang er især nyttig i eksplorativ dataanalyse, hvor målet er at forstå den underliggende struktur i dataene og identificere potentielle mønstre eller relationer. Uovervåget læring finder også anvendelse inden for forskellige domæner som kundesegmentering, anomalidetektion, anbefalingssystemer og billedgenkendelse.
Forstærkningslæring
Reinforcement learning (RL) er en gren af maskinlæring, der fokuserer på, hvordan intelligente agenter kan lære at træffe optimale beslutninger i et miljø for at maksimere kumulative belønninger. I modsætning til supervised learning, som er afhængig af mærkede input/output-par, eller unsupervised learning, som søger at opdage skjulte mønstre, fungerer reinforcement learning ved at lære fra interaktioner med miljøet. Hensigten er at finde en balance mellem udforskning, hvor agenten opdager nye strategier, og udnyttelse, hvor agenten udnytter sin nuværende viden til at træffe informerede beslutninger.
I forstærkningslæring beskrives miljøet typisk som et Markov-beslutningsproces (MDP), som gør det muligt at bruge dynamiske programmeringsteknikker. I modsætning til klassiske dynamiske programmeringsmetoder kræver RL-algoritmer ikke en nøjagtig matematisk model af MDP og er designet til at håndtere store problemer, hvor nøjagtige metoder er upraktiske. Ved at anvende forstærkningslæringsteknikker kan agenter tilpasse sig og forbedre deres beslutningsevner over tid, hvilket gør det til en effektiv tilgang til opgaver som autonom navigation, robotteknologi, spil og ressourcestyring.
Algoritmer og teknikker til maskinlæring
Algoritmer og teknikker til maskinlæring tilbyder forskellige muligheder og anvendes i forskellige domæner til at løse komplekse problemer. Hver algoritme har sine egne styrker og svagheder, og en forståelse af deres egenskaber kan hjælpe forskere og praktikere med at vælge den bedst egnede tilgang til deres specifikke opgaver. Ved at udnytte disse algoritmer kan forskere få værdifuld indsigt fra data og træffe informerede beslutninger inden for deres respektive områder.
Tilfældige skove
Random Forests er en populær algoritme inden for maskinlæring, der falder ind under kategorien ensemble learning. Den kombinerer flere beslutningstræer for at lave forudsigelser eller klassificere data. Hvert beslutningstræ i den tilfældige skov trænes på en anden delmængde af dataene, og den endelige forudsigelse bestemmes ved at aggregere forudsigelserne fra alle de individuelle træer. Random Forests er kendt for deres evne til at håndtere komplekse datasæt, give præcise forudsigelser og håndtere manglende værdier. De bruges i vid udstrækning inden for forskellige områder, herunder finans, sundhedspleje og billedgenkendelse.
Algoritme til dyb læring
Deep Learning er en undergruppe af maskinlæring, der fokuserer på at træne kunstige neurale netværk med flere lag for at lære repræsentationer af data. Deep learning-algoritmer, som f.eks. Konvolutionelle neurale netværk (CNN'er) og Tilbagevendende neurale netværk (RNN'er), har opnået bemærkelsesværdig succes i opgaver som billed- og talegenkendelse, naturlig sprogbehandling og anbefalingssystemer. Deep learning-algoritmer kan automatisk lære hierarkiske funktioner fra rådata, så de kan fange indviklede mønstre og komme med meget præcise forudsigelser. Deep learning-algoritmer kræver dog store mængder af mærkede data og betydelige beregningsressourcer til træning. Hvis du vil vide mere om deep learning, kan du gå ind på IBM's hjemmeside.
Gaussiske processer
Gaussiske processer er en kraftfuld teknik, der bruges i maskinlæring til modellering og forudsigelser baseret på sandsynlighedsfordelinger. De er især nyttige, når man har at gøre med små, støjende datasæt. Gaussiske processer giver en fleksibel og ikke-parametrisk tilgang, der kan modellere komplekse forhold mellem variabler uden at gøre stærke antagelser om den underliggende datadistribution. De bruges ofte i regressionsproblemer, hvor målet er at estimere et kontinuerligt output baseret på inputfunktioner. Gaussiske processer har anvendelser inden for områder som geostatistik, finans og optimering.
Anvendelse af maskinlæring inden for videnskab
Anvendelsen af maskinlæring inden for videnskab åbner nye veje for forskning, så forskere kan tackle komplekse problemer, afdække mønstre og komme med forudsigelser baseret på store og forskelligartede datasæt. Ved at udnytte kraften i maskinlæring kan forskere få dybere indsigt, fremskynde videnskabelige opdagelser og fremme viden på tværs af forskellige videnskabelige domæner.
Medicinsk billedbehandling
Maskinlæring har bidraget væsentligt til medicinsk billeddannelse og revolutioneret diagnostiske og prognostiske muligheder. Machine learning-algoritmer kan analysere medicinske billeder som røntgenbilleder, MR- og CT-scanninger for at hjælpe med at opdage og diagnosticere forskellige sygdomme og tilstande. De kan hjælpe med at identificere uregelmæssigheder, segmentere organer eller væv og forudsige patientresultater. Ved at udnytte maskinlæring i medicinsk billeddannelse kan sundhedspersonale forbedre nøjagtigheden og effektiviteten af deres diagnoser, hvilket fører til bedre patientpleje og behandlingsplanlægning.
Aktiv læring
Aktiv læring er en maskinlæringsteknik, der gør det muligt for algoritmen interaktivt at spørge et menneske eller et orakel om mærkede data. I videnskabelig forskning kan aktiv læring være værdifuld, når man arbejder med begrænsede mærkede datasæt, eller når annotationsprocessen er tidskrævende eller dyr. Ved intelligent at vælge de mest informative forekomster til mærkning kan aktive læringsalgoritmer opnå høj nøjagtighed med færre mærkede eksempler, hvilket reducerer byrden ved manuel annotering og fremskynder videnskabelig opdagelse.
Videnskabelige anvendelser
Maskinlæring finder udbredt anvendelse inden for forskellige videnskabelige discipliner. Inden for genomforskning kan maskinlæringsalgoritmer analysere DNA- og RNA-sekvenser for at identificere genetiske variationer, forudsige proteinstrukturer og forstå genfunktioner. Inden for materialevidenskab anvendes machine learning til at designe nye materialer med de ønskede egenskaber, fremskynde materialeforskning og optimere fremstillingsprocesser. Maskinlæringsteknikker bruges også inden for miljøvidenskab til at forudsige og overvåge forureningsniveauer, vejrprognoser og analyse af klimadata. Desuden spiller det en afgørende rolle inden for fysik, kemi, astronomi og mange andre videnskabelige områder ved at muliggøre datadrevet modellering, simulering og analyse.
Fordele ved maskinlæring inden for videnskab
Fordelene ved maskinlæring inden for videnskab er mange og virkningsfulde. Her er nogle af de vigtigste fordele:
Forbedret prædiktiv modellering: Maskinlæringsalgoritmer kan analysere store og komplekse datasæt for at identificere mønstre, tendenser og relationer, som måske ikke er lette at genkende ved hjælp af traditionelle statistiske metoder. Det gør det muligt for forskere at udvikle præcise forudsigelsesmodeller for forskellige videnskabelige fænomener og resultater, hvilket fører til mere præcise forudsigelser og bedre beslutningstagning.
Øget effektivitet og automatisering: Maskinlæringsteknikker automatiserer gentagne og tidskrævende opgaver, så forskere kan fokusere deres indsats på mere komplekse og kreative aspekter af forskningen. Machine learning-algoritmer kan håndtere store mængder data, udføre hurtige analyser og generere indsigter og konklusioner effektivt. Det fører til øget produktivitet og accelererer tempoet i videnskabelige opdagelser.
Forbedret dataanalyse og -fortolkning: Maskinlæringsalgoritmer er fremragende til dataanalyse og gør det muligt for forskere at udtrække værdifuld indsigt fra store og heterogene datasæt. De kan identificere skjulte mønstre, korrelationer og anomalier, som måske ikke er umiddelbart synlige for menneskelige forskere. Machine learning-teknikker hjælper også med datafortolkning ved at give forklaringer, visualiseringer og resuméer, der gør det lettere at få en dybere forståelse af komplekse videnskabelige fænomener.
Faciliteret beslutningsstøtte: Machine learning-modeller kan fungere som beslutningsstøtteværktøjer for forskere. Ved at analysere historiske data og realtidsinformation kan maskinlæringsalgoritmer hjælpe med beslutningsprocesser, såsom at vælge de mest lovende forskningsveje, optimere eksperimentelle parametre eller identificere potentielle risici eller udfordringer i videnskabelige projekter. Dette hjælper forskere med at træffe informerede beslutninger og øger chancerne for at opnå vellykkede resultater.
Accelereret videnskabelig opdagelse: Maskinlæring fremskynder videnskabelige opdagelser ved at gøre det muligt for forskere at udforske store mængder data, generere hypoteser og validere teorier mere effektivt. Ved at udnytte maskinlæringsalgoritmer kan forskere skabe nye forbindelser, afdække nye indsigter og identificere forskningsretninger, der ellers kunne være blevet overset. Det fører til gennembrud inden for forskellige videnskabelige områder og fremmer innovation.
Kommuniker videnskab visuelt med kraften fra den bedste og gratis infografikproducent
Mind the Graph platformen er en værdifuld ressource, der hjælper forskere med effektivt at kommunikere deres forskning visuelt. Med kraften fra den bedste og gratis infografikproducent gør denne platform det muligt for forskere at skabe engagerende og informativ infografik, der visuelt skildrer komplekse videnskabelige koncepter og data. Uanset om det handler om at præsentere forskningsresultater, forklare videnskabelige processer eller visualisere datatendenser, giver Mind the Graph-platformen forskere mulighed for visuelt at kommunikere deres videnskab klart og overbevisende. Tilmeld dig gratis, og begynd at skabe et design nu.





Tilmeld dig vores nyhedsbrev
Eksklusivt indhold af høj kvalitet om effektiv visuel
kommunikation inden for videnskab.