
I løpet av de siste årene har maskinlæring vokst frem som et kraftfullt verktøy innen vitenskapen, og har revolusjonert måten forskere utforsker og analyserer komplekse data på. Med sin evne til automatisk å lære seg mønstre, lage prediksjoner og avdekke skjult innsikt har maskinlæring åpnet nye veier for vitenskapelig forskning. Formålet med denne artikkelen er å sette søkelyset på maskinlæringens avgjørende rolle i vitenskapen ved å se nærmere på dens mange bruksområder, fremskrittene som er gjort på dette feltet, og potensialet for nye oppdagelser. Forskere som forstår hvordan maskinlæring fungerer, flytter grensene for kunnskap, avdekker kompliserte fenomener og baner vei for banebrytende innovasjoner.
Hva er maskinlæring?
Maskinlæring er en gren av Kunstig intelligens (AI) som fokuserer på å utvikle algoritmer og modeller som gjør det mulig for datamaskiner å lære av data og gjøre forutsigelser eller ta beslutninger uten å være eksplisitt programmert. Det innebærer studier av statistiske og beregningsmessige teknikker som gjør det mulig for datamaskiner å automatisk analysere og tolke mønstre, relasjoner og avhengigheter i data, noe som fører til utvinning av verdifull innsikt og kunnskap.
Relatert artikkel: Kunstig intelligens i vitenskapen
Maskinlæring i vitenskapen
Maskinlæring har vokst frem som et kraftfullt verktøy i ulike vitenskapelige disipliner, og har revolusjonert måten forskere analyserer og tolker komplekse datasett på. I vitenskapen brukes maskinlæringsteknikker til å løse ulike utfordringer, som å forutsi proteinstrukturer, klassifisere astronomiske objekter, modellere klimamønstre og identifisere mønstre i genetiske data. Forskere kan trene opp maskinlæringsalgoritmer til å avdekke skjulte mønstre, gjøre nøyaktige forutsigelser og få en dypere forståelse av komplekse fenomener ved hjelp av store datamengder. Maskinlæring i vitenskapen forbedrer ikke bare effektiviteten og nøyaktigheten i dataanalysen, men åpner også for nye måter å gjøre oppdagelser på, slik at forskere kan ta tak i komplekse vitenskapelige spørsmål og akselerere fremskrittene på sine respektive områder.
Typer av maskinlæring
Noen typer maskinlæring dekker et bredt spekter av tilnærminger og teknikker, som alle er tilpasset ulike problemområder og dataegenskaper. Forskere og praktikere kan velge den mest hensiktsmessige tilnærmingen for sine spesifikke oppgaver og utnytte kraften i maskinlæring til å hente ut innsikt og ta informerte beslutninger. Her er noen av typene maskinlæring:
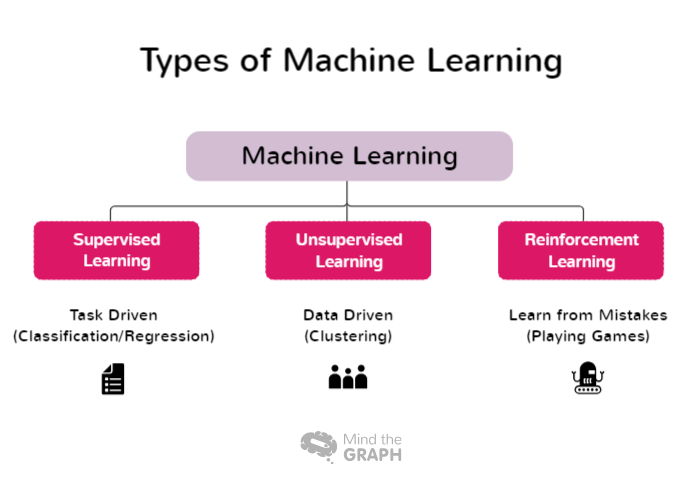
Veiledet læring
Veiledet læring er en grunnleggende tilnærming til maskinlæring der modellen trenes opp ved hjelp av merkede datasett. I denne sammenhengen refererer merkede data til inngangsdata som er paret med tilsvarende utdata- eller målmerker. Målet med veiledet læring er å gjøre det mulig for modellen å lære seg mønstre og sammenhenger mellom inndatafunksjonene og de tilhørende merkelappene, slik at den kan gjøre nøyaktige prediksjoner eller klassifiseringer på nye, usette data.
I løpet av treningsprosessen justerer modellen iterativt sine parametere basert på de merkede dataene og forsøker å minimere forskjellen mellom de predikerte resultatene og de sanne merkelappene. Dette gjør modellen i stand til å generalisere og gi nøyaktige prediksjoner på usette data. Overvåket læring er mye brukt i ulike applikasjoner, blant annet bildegjenkjenning, talegjenkjenning, naturlig språkbehandling og prediktiv analyse.
Læring uten tilsyn
Ikke-veiledet læring er en gren av maskinlæring som fokuserer på å analysere og gruppere umerkede datasett uten bruk av forhåndsdefinerte målmerker. I ikke-veiledet læring er algoritmene utviklet for automatisk å oppdage mønstre, likheter og forskjeller i dataene. Ved å avdekke disse skjulte strukturene gjør ikke-veiledet læring det mulig for forskere og organisasjoner å få verdifull innsikt og ta datadrevne beslutninger.
Denne tilnærmingen er spesielt nyttig i utforskende dataanalyse, der målet er å forstå den underliggende strukturen i dataene og identifisere potensielle mønstre eller sammenhenger. Ikke-veiledet læring brukes også på en rekke andre områder, for eksempel kundesegmentering, avviksdeteksjon, anbefalingssystemer og bildegjenkjenning.
Forsterkningslæring
Reinforcement learning (RL) er en gren av maskinlæring som fokuserer på hvordan intelligente agenter kan lære å ta optimale beslutninger i et miljø for å maksimere kumulative belønninger. I motsetning til veiledet læring, som baserer seg på merkede input/output-par, eller ikke-veiledet læring, som søker å oppdage skjulte mønstre, baserer forsterkningslæring seg på interaksjon med omgivelsene. Hensikten er å finne en balanse mellom utforskning, der agenten oppdager nye strategier, og utnyttelse, der agenten utnytter sin nåværende kunnskap til å ta informerte beslutninger.
Innenfor forsterkningslæring beskrives omgivelsene vanligvis som et Markov-beslutningsprosess (MDP), noe som gjør det mulig å bruke dynamiske programmeringsteknikker. I motsetning til klassiske dynamiske programmeringsmetoder krever ikke RL-algoritmer en eksakt matematisk modell av MDP og er utviklet for å håndtere store problemer der eksakte metoder er upraktiske. Ved å bruke forsterkningslæringsteknikker kan agenter tilpasse seg og forbedre beslutningsevnen sin over tid, noe som gjør det til en effektiv tilnærming for oppgaver som autonom navigasjon, robotikk, spill og ressursforvaltning.
Algoritmer og teknikker for maskinlæring
Maskinlæringsalgoritmer og -teknikker har ulike egenskaper og brukes på ulike områder for å løse komplekse problemer. Hver algoritme har sine egne styrker og svakheter, og en forståelse av deres egenskaper kan hjelpe forskere og praktikere med å velge den tilnærmingen som passer best for deres spesifikke oppgaver. Ved å utnytte disse algoritmene kan forskere få verdifull innsikt fra data og ta informerte beslutninger på sine respektive områder.
Tilfeldig skog
Random Forests er en populær algoritme innen maskinlæring som faller inn under kategorien ensemblelæring. Den kombinerer flere beslutningstrær for å lage prediksjoner eller klassifisere data. Hvert beslutningstre i den tilfeldige skogen trenes opp på en annen delmengde av dataene, og den endelige prediksjonen bestemmes ved å legge sammen prediksjonene fra alle de individuelle trærne. Random Forests er kjent for sin evne til å håndtere komplekse datasett, gi nøyaktige prediksjoner og håndtere manglende verdier. De er mye brukt på ulike områder, blant annet innen finans, helsevesen og bildegjenkjenning.
Algoritme for dyp læring
Dyp læring er en undergruppe av maskinlæring som fokuserer på opplæring av kunstige nevrale nettverk med flere lag for å lære representasjoner av data. Algoritmer for dyp læring, for eksempel Konvolusjonelle nevrale nettverk (CNN) og Tilbakevendende nevrale nettverk (RNN), har hatt stor suksess i oppgaver som bilde- og talegjenkjenning, naturlig språkbehandling og anbefalingssystemer. Dybdelæringsalgoritmer kan automatisk lære seg hierarkiske egenskaper fra rådata, noe som gjør dem i stand til å fange opp komplekse mønstre og gi svært nøyaktige prediksjoner. Dyplæringsalgoritmer krever imidlertid store mengder merkede data og betydelige beregningsressurser for å kunne lære dem opp. Hvis du vil vite mer om dybdelæring, kan du gå til IBMs nettsted.
Gaussiske prosesser
Gaussiske prosesser er en kraftig teknikk som brukes i maskinlæring for å modellere og lage prediksjoner basert på sannsynlighetsfordelinger. De er spesielt nyttige når man arbeider med små, støyende datasett. Gaussiske prosesser gir en fleksibel og ikke-parametrisk tilnærming som kan modellere komplekse sammenhenger mellom variabler uten å gjøre sterke antagelser om den underliggende datafordelingen. Gaussiske prosesser brukes ofte i regresjonsproblemer, der målet er å estimere et kontinuerlig utdata basert på inndatafunksjoner. Gaussiske prosesser brukes blant annet innen geostatistikk, finans og optimering.
Anvendelse av maskinlæring i vitenskapen
Anvendelsen av maskinlæring i vitenskapen åpner nye muligheter for forskning, og gjør det mulig for forskere å løse komplekse problemer, avdekke mønstre og gjøre forutsigelser basert på store og mangfoldige datasett. Ved å utnytte kraften i maskinlæring kan forskere få dypere innsikt, akselerere vitenskapelige oppdagelser og fremme kunnskap på tvers av ulike vitenskapelige domener.
Medisinsk avbildning
Maskinlæring har gitt betydelige bidrag til medisinsk bildebehandling og revolusjonert mulighetene for diagnostikk og prognose. Maskinlæringsalgoritmer kan analysere medisinske bilder som røntgenbilder, MR-bilder og CT-skanninger for å hjelpe til med å oppdage og diagnostisere ulike sykdommer og tilstander. De kan bidra til å identifisere avvik, segmentere organer eller vev og forutsi pasientens utfall. Ved å utnytte maskinlæring i medisinsk bildebehandling kan helsepersonell øke nøyaktigheten og effektiviteten i diagnostiseringen, noe som fører til bedre pasientbehandling og behandlingsplanlegging.
Aktiv læring
Aktiv læring er en maskinlæringsteknikk som gjør det mulig for algoritmen å interaktivt spørre et menneske eller et orakel om merkede data. I vitenskapelig forskning kan aktiv læring være verdifullt når man arbeider med begrensede merkede datasett eller når annoteringsprosessen er tidkrevende eller kostbar. Ved å velge ut de mest informative eksemplene for merking på en intelligent måte kan aktive læringsalgoritmer oppnå høy nøyaktighet med færre merkede eksempler, noe som reduserer byrden ved manuell annotering og fremskynder vitenskapelige oppdagelser.
Vitenskapelige anvendelser
Maskinlæring brukes i stor utstrekning innen ulike vitenskapelige disipliner. Innen genomikk kan maskinlæringsalgoritmer analysere DNA- og RNA-sekvenser for å identifisere genetiske variasjoner, forutsi proteinstrukturer og forstå genfunksjoner. Innen materialvitenskap brukes maskinlæring til å designe nye materialer med ønskede egenskaper, akselerere materialforskning og optimalisere produksjonsprosesser. Maskinlæringsteknikker brukes også innen miljøvitenskap for å forutsi og overvåke forurensningsnivåer, lage værprognoser og analysere klimadata. I tillegg spiller maskinlæring en avgjørende rolle innen fysikk, kjemi, astronomi og mange andre vitenskapelige fagområder ved å muliggjøre datadrevet modellering, simulering og analyse.
Fordelene med maskinlæring innen vitenskap
Fordelene med maskinlæring innen forskning er mange og virkningsfulle. Her er noen av de viktigste fordelene:
Forbedret prediktiv modellering: Maskinlæringsalgoritmer kan analysere store og komplekse datasett for å identifisere mønstre, trender og sammenhenger som det kan være vanskelig å gjenkjenne med tradisjonelle statistiske metoder. Dette gjør det mulig for forskere å utvikle nøyaktige prediksjonsmodeller for ulike vitenskapelige fenomener og resultater, noe som fører til mer presise forutsigelser og bedre beslutninger.
Økt effektivitet og automatisering: Maskinlæringsteknikker automatiserer repetitive og tidkrevende oppgaver, slik at forskere kan fokusere på mer komplekse og kreative aspekter ved forskningen. Maskinlæringsalgoritmer kan håndtere store datamengder, utføre raske analyser og generere innsikt og konklusjoner på en effektiv måte. Dette fører til økt produktivitet og øker tempoet i den vitenskapelige forskningen.
Forbedret dataanalyse og -tolkning: Maskinlæringsalgoritmer utmerker seg innen dataanalyse og gjør det mulig for forskere å hente ut verdifull innsikt fra store og heterogene datasett. De kan identifisere skjulte mønstre, korrelasjoner og anomalier som kanskje ikke er umiddelbart synlige for menneskelige forskere. Maskinlæringsteknikker hjelper også til med å tolke data ved å gi forklaringer, visualiseringer og oppsummeringer, noe som bidrar til en dypere forståelse av komplekse vitenskapelige fenomener.
Tilrettelagt beslutningsstøtte: Maskinlæringsmodeller kan fungere som beslutningsstøtteverktøy for forskere. Ved å analysere historiske data og sanntidsinformasjon kan maskinlæringsalgoritmer bistå i beslutningsprosesser, for eksempel ved å velge de mest lovende forskningsveiene, optimalisere eksperimentelle parametere eller identifisere potensielle risikoer eller utfordringer i vitenskapelige prosjekter. Dette hjelper forskere med å ta informerte beslutninger og øker sjansene for å oppnå vellykkede resultater.
Raskere vitenskapelig oppdagelse: Maskinlæring fremskynder vitenskapelige oppdagelser ved å gjøre det mulig for forskere å utforske store datamengder, generere hypoteser og validere teorier mer effektivt. Ved å utnytte maskinlæringsalgoritmer kan forskere skape nye sammenhenger, avdekke ny innsikt og identifisere forskningsretninger som ellers kunne ha blitt oversett. Dette fører til gjennombrudd på ulike vitenskapelige områder og fremmer innovasjon.
Formidle vitenskap visuelt med kraften i den beste og gratis infografikkskaperen
Mind the Graph er en verdifull ressurs som hjelper forskere med å kommunisere forskningen sin visuelt på en effektiv måte. Ved hjelp av den beste og gratis infografikkprodusenten kan forskere lage engasjerende og informativ infografikk som visuelt beskriver komplekse vitenskapelige konsepter og data. Enten det dreier seg om å presentere forskningsresultater, forklare vitenskapelige prosesser eller visualisere datatrender, gir Mind the Graph-plattformen forskere muligheten til å kommunisere vitenskapen sin på en tydelig og overbevisende måte. Registrer deg gratis og begynn å lage et design nå.





Abonner på nyhetsbrevet vårt
Eksklusivt innhold av høy kvalitet om effektiv visuell
kommunikasjon innen vitenskap.