
Regressionsanalys är en metod för att identifiera och analysera sambandet mellan en eller flera oberoende variabler och en beroende variabel. Metoden används flitigt inom en rad olika discipliner, t.ex. hälso- och sjukvård, samhällsvetenskap, teknik, ekonomi och företagsekonomi. Du kan använda regressionsanalys för att undersöka de grundläggande sambanden i data och utveckla prediktiva modeller som hjälper dig att fatta välgrundade beslut.
Den här artikeln ger dig en omfattande översikt över regressionsanalys, inklusive hur den fungerar, ett lättbegripligt exempel och en förklaring av hur den skiljer sig från korrelationsanalys.
Vad är regressionsanalys?
Regressionsanalys är en statistisk metod för att identifiera och kvantifiera sambandet mellan en beroende variabel och en eller flera oberoende variabler. I ett nötskal hjälper den dig att förstå hur förändringar i en eller flera oberoende variabler är relaterade till förändringar i den beroende variabeln.
För att få en grundlig förståelse av regressionsanalys måste du först förstå följande termer:
- Beroende variabel: Detta är den variabel som du är intresserad av att analysera eller förutsäga. Det är utfallsvariabeln som du försöker förstå och förklara.
- Oberoende variabler: Detta är de variabler som du tror har en effekt på den beroende variabeln. De kallas ofta för prediktorvariabler, eftersom de används för att förutsäga eller förklara förändringar i den beroende variabeln.
Regressionsanalys kan användas under en rad omständigheter, inklusive att förutsäga framtida värden för den beroende variabeln, förstå effekten av oberoende variabler på den beroende variabeln och hitta outliers eller ovanliga förekomster i datainsamlingen.
Regressionsanalys kan klassificeras i flera typer, inklusive enkel linjär regression, logistisk regression, polynomisk regression och multipel regression. Vilken regressionsmodell som är lämplig avgörs av typen av data och det aktuella undersökningsobjektet.
Hur fungerar regressionsanalys?
Syftet med regressionsanalys är att identifiera den bäst passande linjen eller kurvan som återspeglar sambandet mellan de oberoende variablerna och den beroende variabeln. Denna linje eller kurva genereras med hjälp av statistiska metoder som minskar skillnaderna mellan de förväntade och verkliga värdena i datainsamlingen.
Här följer formlerna för de två vanligaste typerna av regressionsanalys:
Enkel linjär regression
I Enkel linjär regression använder du en linje med bästa passform för att visa förhållandet mellan två variabler: den oberoende variabeln (x) och den beroende variabeln (y).
Den linje som passar bäst kan representeras av ekvationen: y = a + bx.
Här är a skärningspunkten och b linjens lutning. För att beräkna lutningen använder du formeln: b = (nΣ(xy) - ΣxΣy) / (nΣ(x2) - (Σx)2), där n är antalet observationer, Σxy är summan av produkten av x och y, Σx och Σy är summan av x respektive y, och Σ(x2) är summan av kvadraterna för x.
För att beräkna skärningspunkten används formeln: a = (Σy - bΣx) / n.
Multipel regression
Multipel linjär regression:
Formeln för ekvationen för den multipla linjära regressionsmodellen är:
y = b0 + b1x1 + b2x2 + ... + bnxn
där y är den beroende variabeln, x1, x2, ..., xn är de oberoende variablerna, och b0, b1, b2, ..., bn är koefficienterna för de oberoende variablerna.
Formeln för att skatta koefficienterna med hjälp av ordinära minsta kvadratmetoden är
β = (X'X)(-1)X'y
där β är en kolumnvektor av koefficienter, X är designmatrisen av oberoende variabler, X' är transponering av X, och y är vektorn av observationer av den beroende variabeln.
Exempel på regressionsanalys
Antag att du vill undersöka sambandet mellan en individs betygsmedelvärde (GPA) och antalet timmar de studerar per vecka. Du samlar in information från en uppsättning studenter, inklusive deras antal studietimmar och betygsmedelvärde.
Använd sedan regressionsanalysen för att se om det finns ett linjärt samband mellan de båda variablerna och om så är fallet kan du bygga en modell som förutsäger en students GPA baserat på antalet timmar de studerar per vecka.

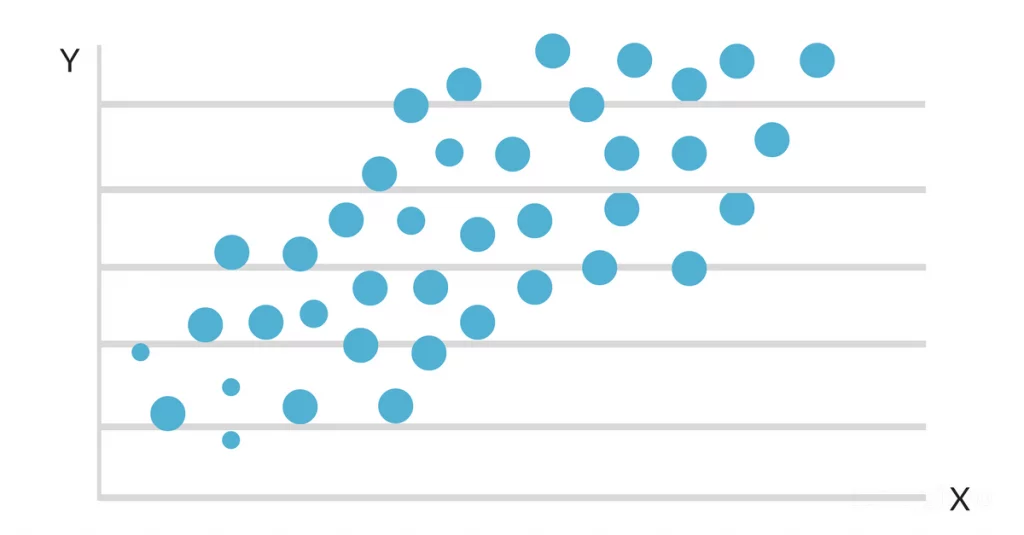
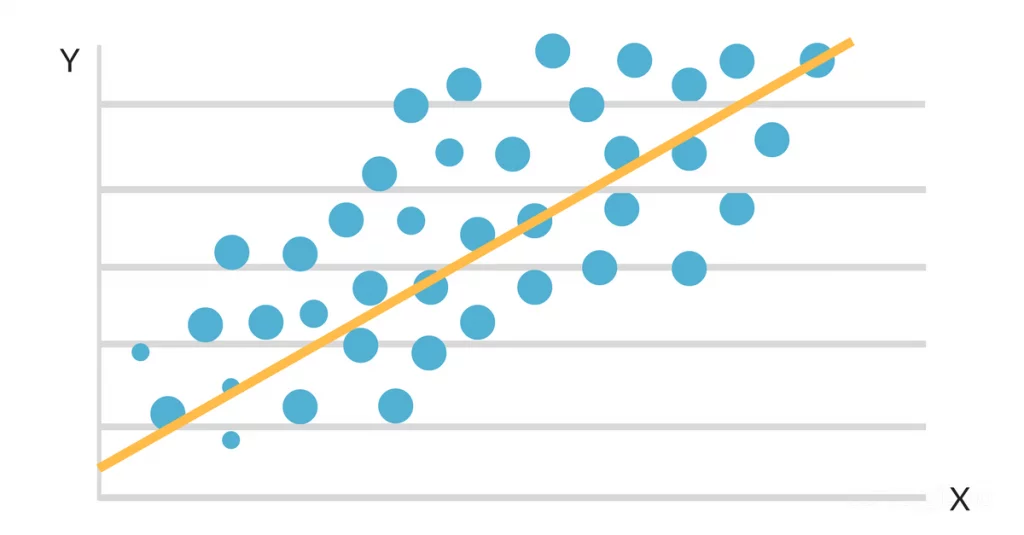
När data plottas på en spridningskarta verkar det som om det finns ett gynnsamt linjärt samband mellan studietid och GPA. Lutningen och skärningspunkten för den linje som passar bäst uppskattas sedan med hjälp av en enkel linjär regressionsmodell. Den slutliga lösningen kan se ut så här:
GPA = 2,0 + 0,3 (studietimmar per vecka)
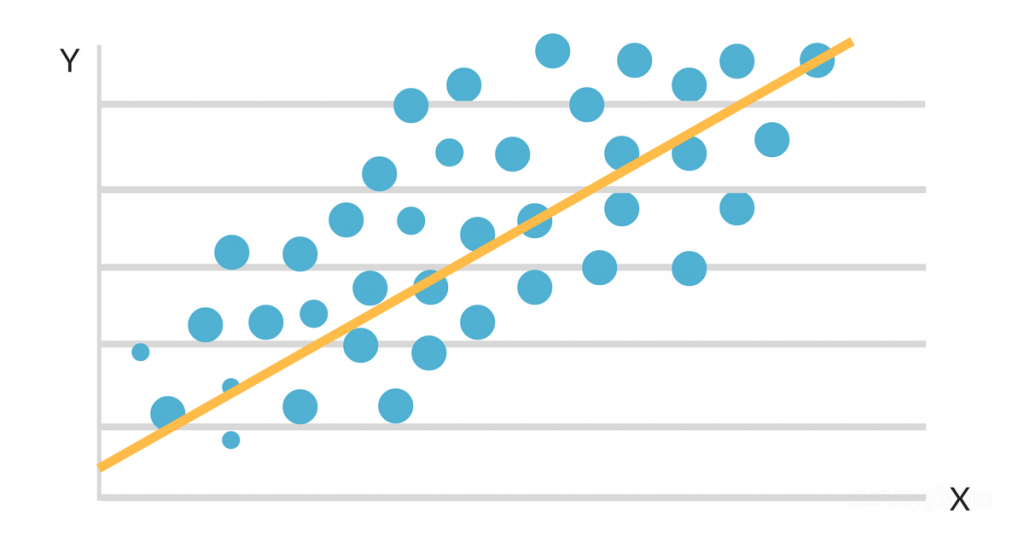
Denna ekvation säger att för varje extra studietimme per vecka kommer en elevs GPA att öka med 0,3 poäng, med allt annat likvärdigt. Denna algoritm kan användas för att prognostisera en students GPA baserat på hur många timmar de studerar per vecka, samt för att identifiera vilka studenter som riskerar att underprestera baserat på deras studierutiner.
Med hjälp av data från exemplet, värdena för b och a är följande:
n = 10 (antalet observationer)
Σx = 30 (summan av studietimmarna)
Σy = 25 (summan av GPA-värdena)
Σxy = 149 (summan av produkten av studietimmar och GPA)
Σ(x)2 = 102 (summan av kvadraterna för studietimmarna)
Använd dessa värden för att beräkna b som:
b = (nΣ(xy) - ΣxΣy) / (nΣ(x2) - (Σx)2)
= (10 * 149 – 30 * 25) / (10 * 102 – 302)
= 0.3
Och beräkna a som:
a = (Σy - bΣx) / n
= (25 – 0.3 * 30) / 10
= 2.0
Därför är ekvationen för linjen för bästa anpassning:
GPA = 2,0 + 0,3 (studietimmar per vecka)
Vad är skillnaden mellan korrelation och regression?
Både korrelation och regression är statistiska metoder för att undersöka sambandet mellan två variabler. De har olika syften och ger olika typer av information.
Korrelation är ett mått på styrkan och förloppet av ett samband mellan två variabler. Det går från -1 till +1, där -1 representerar en perfekt negativ korrelation, 0 representerar ingen korrelation och +1 representerar en perfekt positiv korrelation. Korrelationen anger i vilken grad två variabler är kopplade till varandra, men den anger inte orsak eller förutsägbarhet.
Regression, å andra sidan, är en metod för att modellera sambandet mellan två variabler, vanligtvis i syfte att prognostisera eller förklara en variabel baserat på den andra. Regressionsanalys kan ge uppskattningar av sambandets storlek och riktning, samt statistiska signifikanstester, konfidensintervall och prognoser för framtida resultat.
Dina kreationer, klara inom några minuter
Mind the Graph är en onlineplattform som erbjuder dig ett omfattande bibliotek med vetenskapliga illustrationer och infografiska mönster som enkelt kan modifieras för att uppfylla dina unika behov. Skapa professionella diagram, affischer och grafiska sammanfattningar på några minuter med hjälp av ett dra-och-släpp-gränssnitt och ett brett utbud av verktyg och funktioner.



{kind=link}
{kind=link}

Prenumerera på vårt nyhetsbrev
Exklusivt innehåll av hög kvalitet om effektiv visuell
kommunikation inom vetenskap.