
Under de senaste åren har maskininlärning vuxit fram som ett kraftfullt verktyg inom vetenskapen och revolutionerat hur forskare utforskar och analyserar komplexa data. Med sin förmåga att automatiskt lära sig mönster, göra förutsägelser och avslöja dolda insikter har maskininlärning öppnat nya vägar för vetenskapliga undersökningar. Syftet med den här artikeln är att belysa maskininlärningens avgörande roll inom vetenskapen genom att utforska dess breda användningsområde, de framsteg som gjorts inom detta område och den potential som finns för ytterligare upptäckter. Genom att förstå hur maskininlärning fungerar kan forskare tänja på gränserna för kunskap, avslöja komplicerade fenomen och bana väg för banbrytande innovationer.
Vad är maskininlärning?
Maskininlärning är en gren av Artificiell intelligens (AI) som fokuserar på att utveckla algoritmer och modeller som gör det möjligt för datorer att lära sig av data och göra förutsägelser eller fatta beslut utan att vara uttryckligen programmerade. Det handlar om att studera statistiska och beräkningstekniska metoder som gör att datorer automatiskt kan analysera och tolka mönster, relationer och beroenden i data, vilket leder till att värdefulla insikter och kunskaper kan utvinnas.
Relaterad artikel: Artificiell intelligens inom vetenskap
Maskininlärning inom vetenskap
Maskininlärning har utvecklats till ett kraftfullt verktyg inom olika vetenskapliga discipliner och har revolutionerat forskarnas sätt att analysera och tolka komplexa datamängder. Inom vetenskapen används maskininlärningstekniker för att hantera olika utmaningar, såsom att förutsäga proteinstrukturer, klassificera astronomiska objekt, modellera klimatmönster och identifiera mönster i genetiska data. Forskare kan träna maskininlärningsalgoritmer för att upptäcka dolda mönster, göra korrekta förutsägelser och få en djupare förståelse för komplexa fenomen genom att använda stora datamängder. Maskininlärning inom vetenskap förbättrar inte bara effektiviteten och noggrannheten i dataanalysen utan öppnar också nya vägar för upptäckt, vilket gör det möjligt för forskare att ta itu med komplexa vetenskapliga frågor och påskynda framstegen inom sina respektive områden.
Typer av maskininlärning
Vissa typer av maskininlärning täcker ett brett spektrum av metoder och tekniker, var och en lämpad för olika problemdomäner och dataegenskaper. Forskare och utövare kan välja det lämpligaste tillvägagångssättet för sina specifika uppgifter och utnyttja kraften i maskininlärning för att extrahera insikter och fatta välgrundade beslut. Här är några av de olika typerna av maskininlärning:
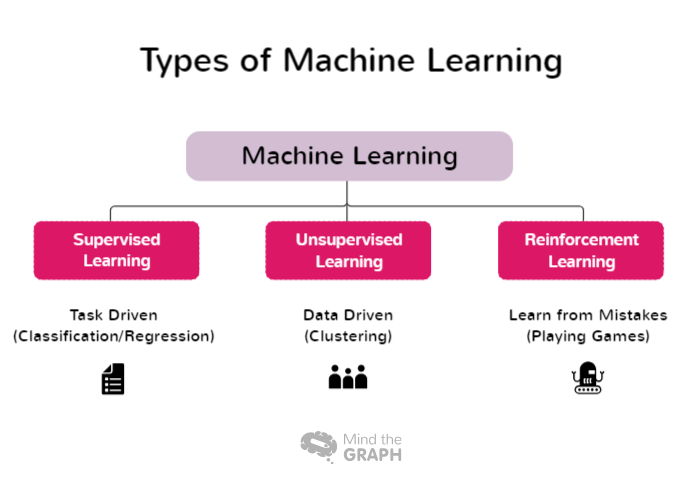
Övervakad inlärning
Övervakad inlärning är en grundläggande metod inom maskininlärning där modellen tränas med hjälp av märkta datamängder. I detta sammanhang avser märkta data indata som är parade med motsvarande utdata eller måletiketter. Målet med supervised learning är att modellen ska lära sig mönster och relationer mellan indatafunktionerna och deras motsvarande etiketter, så att den kan göra korrekta förutsägelser eller klassificeringar på nya, osedda data.
Under träningsprocessen justerar modellen iterativt sina parametrar baserat på de märkta data som tillhandahålls och strävar efter att minimera skillnaden mellan dess förutsagda utdata och de sanna etiketterna. Detta gör det möjligt för modellen att generalisera och göra korrekta förutsägelser på osedda data. Övervakad inlärning används ofta i olika applikationer, inklusive bildigenkänning, taligenkänning, naturlig språkbehandling och prediktiv analys.
Inlärning utan tillsyn
Unsupervised learning är en gren inom maskininlärning som fokuserar på analys och klustring av omärkta datamängder utan användning av fördefinierade målmärkningar. I unsupervised learning är algoritmerna utformade för att automatiskt upptäcka mönster, likheter och skillnader i data. Genom att avslöja dessa dolda strukturer gör unsupervised learning det möjligt för forskare och organisationer att få värdefulla insikter och fatta datadrivna beslut.
Detta tillvägagångssätt är särskilt användbart vid explorativ dataanalys, där målet är att förstå den underliggande strukturen i data och identifiera potentiella mönster eller relationer. Oövervakad inlärning används också inom olika områden, t.ex. kundsegmentering, anomalidetektering, rekommendationssystem och bildigenkänning.
Förstärkningsinlärning
Förstärkningsinlärning (RL) är en gren av maskininlärning som fokuserar på hur intelligenta agenter kan lära sig att fatta optimala beslut i en miljö för att maximera kumulativa belöningar. Till skillnad från övervakad inlärning som bygger på märkta input/output-par eller oövervakad inlärning som försöker upptäcka dolda mönster, fungerar förstärkningsinlärning genom att lära sig från interaktioner med miljön. Avsikten är att hitta en balans mellan utforskning, där agenten upptäcker nya strategier, och utnyttjande, där agenten utnyttjar sin nuvarande kunskap för att fatta välgrundade beslut.
Vid förstärkningsinlärning beskrivs miljön vanligtvis som en Markov beslutsprocess (MDP), vilket gör det möjligt att använda dynamiska programmeringstekniker. Till skillnad från klassiska dynamiska programmeringsmetoder kräver RL-algoritmer inte en exakt matematisk modell av MDP och är utformade för att hantera storskaliga problem där exakta metoder är opraktiska. Genom att använda tekniker för förstärkt inlärning kan agenter anpassa sig och förbättra sin förmåga att fatta beslut över tid, vilket gör det till en kraftfull metod för uppgifter som autonom navigering, robotteknik, spel och resurshantering.
Algoritmer och tekniker för maskininlärning
Algoritmer och tekniker för maskininlärning erbjuder olika möjligheter och används inom olika domäner för att lösa komplexa problem. Varje algoritm har sina egna styrkor och svagheter, och att förstå deras egenskaper kan hjälpa forskare och praktiker att välja det lämpligaste tillvägagångssättet för sina specifika uppgifter. Genom att utnyttja dessa algoritmer kan forskare få värdefulla insikter från data och fatta välgrundade beslut inom sina respektive områden.
Slumpmässiga skogar
Random Forests är en populär algoritm inom maskininlärning som faller under kategorin ensembleinlärning. Den kombinerar flera beslutsträd för att göra förutsägelser eller klassificera data. Varje beslutsträd i den slumpmässiga skogen tränas på en annan delmängd av data, och den slutliga förutsägelsen bestäms genom att aggregera förutsägelserna från alla de enskilda träden. Random Forests är kända för sin förmåga att hantera komplexa datamängder, ge korrekta förutsägelser och hantera saknade värden. De används ofta inom olika områden, bland annat finans, sjukvård och bildigenkänning.
Algoritm för djupinlärning
Deep Learning är en delmängd av maskininlärning som fokuserar på att utbilda artificiella neurala nätverk med flera lager för att lära sig representationer av data. Algoritmer för djupinlärning, t.ex. Konvolutionella neurala nätverk (CNN) och Återkommande neurala nätverk (RNN), har nått anmärkningsvärda framgångar i uppgifter som bild- och taligenkänning, naturlig språkbehandling och rekommendationssystem. Algoritmer för djupinlärning kan automatiskt lära sig hierarkiska funktioner från rådata, vilket gör att de kan fånga in invecklade mönster och göra mycket exakta förutsägelser. Algoritmer för djupinlärning kräver dock stora mängder märkta data och betydande beräkningsresurser för träning. Om du vill veta mer om djupinlärning kan du gå till IBM:s webbplats.
Gaussiska processer
Gaussiska processer är en kraftfull teknik som används inom maskininlärning för att modellera och göra förutsägelser baserade på sannolikhetsfördelningar. De är särskilt användbara när man hanterar små, brusiga dataset. Gaussiska processer är en flexibel och icke-parametrisk metod som kan modellera komplexa samband mellan variabler utan att göra starka antaganden om den underliggande datafördelningen. De används ofta i regressionsproblem, där målet är att uppskatta en kontinuerlig utdata baserat på indatafunktioner. Gaussiska processer har tillämpningar inom områden som geostatistik, finans och optimering.
Tillämpning av maskininlärning inom vetenskap
Tillämpningen av maskininlärning inom vetenskap öppnar upp nya vägar för forskning, vilket gör det möjligt för forskare att hantera komplexa problem, upptäcka mönster och göra förutsägelser baserat på stora och olika datamängder. Genom att utnyttja kraften i maskininlärning kan forskare få djupare insikter, påskynda vetenskapliga upptäckter och öka kunskapen inom olika vetenskapliga områden.
Medicinsk bildbehandling
Maskininlärning har gjort betydande framsteg inom medicinsk bildbehandling och revolutionerat möjligheterna till diagnostik och prognos. Algoritmer för maskininlärning kan analysera medicinska bilder som röntgen, magnetröntgen och datortomografi för att underlätta upptäckt och diagnos av olika sjukdomar och tillstånd. De kan hjälpa till att identifiera avvikelser, segmentera organ eller vävnader och förutsäga patientresultat. Genom att utnyttja maskininlärning inom medicinsk bildbehandling kan vårdpersonal förbättra noggrannheten och effektiviteten i sina diagnoser, vilket leder till bättre patientvård och behandlingsplanering.
Aktivt lärande
Aktiv inlärning är en maskininlärningsteknik som gör det möjligt för algoritmen att interaktivt fråga en människa eller ett orakel efter märkta data. Inom vetenskaplig forskning kan aktiv inlärning vara värdefull när man arbetar med begränsade märkta datamängder eller när annoteringsprocessen är tidskrävande eller dyr. Genom att på ett intelligent sätt välja de mest informativa exemplen för märkning kan aktiva inlärningsalgoritmer uppnå hög noggrannhet med färre märkta exempel, vilket minskar bördan av manuell annotering och påskyndar vetenskapliga upptäckter.
Vetenskapliga tillämpningar
Maskininlärning används i stor utsträckning inom olika vetenskapliga discipliner. Inom genomik kan maskininlärningsalgoritmer analysera DNA- och RNA-sekvenser för att identifiera genetiska variationer, förutsäga proteinstrukturer och förstå genernas funktioner. Inom materialvetenskap används maskininlärning för att designa nya material med önskade egenskaper, påskynda materialupptäckt och optimera tillverkningsprocesser. Maskininlärningstekniker används också inom miljövetenskap för att förutsäga och övervaka föroreningsnivåer, väderprognoser och analys av klimatdata. Dessutom spelar de en avgörande roll inom fysik, kemi, astronomi och många andra vetenskapliga områden genom att möjliggöra datadriven modellering, simulering och analys.
Fördelar med maskininlärning inom vetenskap
Fördelarna med maskininlärning inom vetenskap är många och betydelsefulla. Här är några av de viktigaste fördelarna:
Förbättrad prediktiv modellering: Algoritmer för maskininlärning kan analysera stora och komplexa datamängder för att identifiera mönster, trender och samband som kanske inte är så lätta att identifiera med traditionella statistiska metoder. Detta gör det möjligt för forskare att utveckla exakta prognosmodeller för olika vetenskapliga fenomen och resultat, vilket leder till mer exakta förutsägelser och förbättrat beslutsfattande.
Ökad effektivitet och automatisering: Maskininlärningstekniker automatiserar repetitiva och tidskrävande uppgifter, vilket gör att forskare kan fokusera sina ansträngningar på mer komplexa och kreativa aspekter av forskning. Algoritmer för maskininlärning kan hantera stora mängder data, utföra snabba analyser och generera insikter och slutsatser på ett effektivt sätt. Detta leder till ökad produktivitet och påskyndar vetenskapliga upptäckter.
Förbättrad analys och tolkning av data: Maskininlärningsalgoritmer är utmärkta för dataanalys och gör det möjligt för forskare att utvinna värdefulla insikter från stora och heterogena datamängder. De kan identifiera dolda mönster, korrelationer och avvikelser som kanske inte är omedelbart uppenbara för mänskliga forskare. Maskininlärningstekniker hjälper också till att tolka data genom att tillhandahålla förklaringar, visualiseringar och sammanfattningar, vilket underlättar en djupare förståelse av komplexa vetenskapliga fenomen.
Underlättat beslutsstöd: Maskininlärningsmodeller kan fungera som beslutsstödsverktyg för forskare. Genom att analysera historiska data och realtidsinformation kan maskininlärningsalgoritmer hjälpa till i beslutsprocesser, till exempel att välja de mest lovande forskningsvägarna, optimera experimentella parametrar eller identifiera potentiella risker eller utmaningar i vetenskapliga projekt. Detta hjälper forskare att fatta välgrundade beslut och ökar chanserna att uppnå framgångsrika resultat.
Påskyndad vetenskaplig upptäckt: Maskininlärning påskyndar vetenskapliga upptäckter genom att göra det möjligt för forskare att utforska stora mängder data, generera hypoteser och validera teorier mer effektivt. Genom att utnyttja algoritmer för maskininlärning kan forskare skapa nya kopplingar, få nya insikter och identifiera forskningsinriktningar som annars kanske hade förbisetts. Detta leder till genombrott inom olika vetenskapliga områden och främjar innovation.
Kommunicera vetenskap visuellt med hjälp av den bästa och kostnadsfria infografikskaparen
Mind the Graph är en värdefull resurs som hjälper forskare att effektivt kommunicera sin forskning visuellt. Med kraften i den bästa och gratis infografiktillverkaren gör denna plattform det möjligt för forskare att skapa engagerande och informativ infografik som visuellt skildrar komplexa vetenskapliga koncept och data. Oavsett om det handlar om att presentera forskningsresultat, förklara vetenskapliga processer eller visualisera datatrender ger Mind the Graph-plattformen forskare möjlighet att visuellt kommunicera sin vetenskap på ett tydligt och övertygande sätt. Registrera dig kostnadsfritt och börja skapa en design nu.





Prenumerera på vårt nyhetsbrev
Exklusivt innehåll av hög kvalitet om effektiv visuell
kommunikation inom vetenskap.