
W ostatnich latach uczenie maszynowe stało się potężnym narzędziem w dziedzinie nauki, rewolucjonizując sposób, w jaki naukowcy badają i analizują złożone dane. Dzięki zdolności do automatycznego uczenia się wzorców, tworzenia prognoz i odkrywania ukrytych spostrzeżeń, uczenie maszynowe otworzyło nowe możliwości dla badań naukowych. Niniejszy artykuł ma na celu podkreślenie kluczowej roli uczenia maszynowego w nauce poprzez zbadanie jego szerokiego zakresu zastosowań, postępów poczynionych w tej dziedzinie oraz potencjału, jaki kryje w sobie dla dalszych odkryć. Rozumiejąc działanie uczenia maszynowego, naukowcy przesuwają granice wiedzy, odkrywają skomplikowane zjawiska i torują drogę przełomowym innowacjom.
Czym jest uczenie maszynowe?
Uczenie maszynowe to gałąź Sztuczna inteligencja (AI), która koncentruje się na opracowywaniu algorytmów i modeli, które umożliwiają komputerom uczenie się na podstawie danych i podejmowanie prognoz lub decyzji bez wyraźnego programowania. Obejmuje ona badanie technik statystycznych i obliczeniowych, które pozwalają komputerom automatycznie analizować i interpretować wzorce, relacje i zależności w danych, prowadząc do wydobycia cennych spostrzeżeń i wiedzy.
Powiązany artykuł: Sztuczna inteligencja w nauce
Uczenie maszynowe w nauce
Uczenie maszynowe stało się potężnym narzędziem w różnych dyscyplinach naukowych, rewolucjonizując sposób, w jaki badacze analizują i interpretują złożone zbiory danych. W nauce techniki uczenia maszynowego są wykorzystywane do radzenia sobie z różnymi wyzwaniami, takimi jak przewidywanie struktur białek, klasyfikowanie obiektów astronomicznych, modelowanie wzorców klimatycznych i identyfikowanie wzorców w danych genetycznych. Naukowcy mogą trenować algorytmy uczenia maszynowego, aby odkrywać ukryte wzorce, dokonywać dokładnych prognoz i uzyskać głębsze zrozumienie złożonych zjawisk, wykorzystując duże ilości danych. Uczenie maszynowe w nauce nie tylko zwiększa wydajność i dokładność analizy danych, ale także otwiera nowe drogi do odkryć, umożliwiając badaczom rozwiązywanie złożonych pytań naukowych i przyspieszenie postępów w ich dziedzinach.
Rodzaje uczenia maszynowego
Niektóre rodzaje uczenia maszynowego obejmują szeroki zakres podejść i technik, z których każda jest dostosowana do różnych dziedzin problemów i charakterystyki danych. Naukowcy i praktycy mogą wybrać najbardziej odpowiednie podejście do swoich konkretnych zadań i wykorzystać moc uczenia maszynowego do wydobywania spostrzeżeń i podejmowania świadomych decyzji. Oto niektóre z rodzajów uczenia maszynowego:
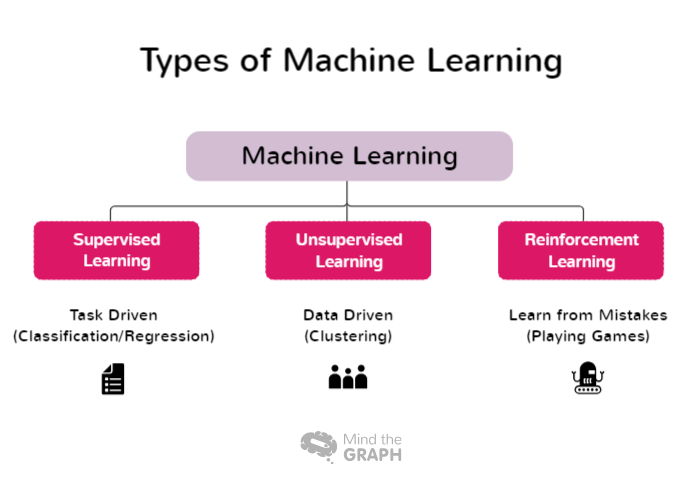
Uczenie nadzorowane
Uczenie nadzorowane to podstawowe podejście w uczeniu maszynowym, w którym model jest trenowany przy użyciu oznaczonych zestawów danych. W tym kontekście oznaczone dane odnoszą się do danych wejściowych, które są sparowane z odpowiednimi etykietami wyjściowymi lub docelowymi. Celem uczenia nadzorowanego jest umożliwienie modelowi uczenia się wzorców i relacji między funkcjami wejściowymi i odpowiadającymi im etykietami, co pozwala mu na dokonywanie dokładnych prognoz lub klasyfikacji na nowych, niewidocznych danych.
Podczas procesu uczenia model iteracyjnie dostosowuje swoje parametry w oparciu o dostarczone oznaczone dane, dążąc do zminimalizowania różnicy między przewidywanymi wynikami a prawdziwymi etykietami. Umożliwia to modelowi generalizację i dokładne przewidywanie na niewidocznych danych. Uczenie nadzorowane jest szeroko stosowane w różnych aplikacjach, w tym w rozpoznawaniu obrazów, rozpoznawaniu mowy, przetwarzaniu języka naturalnego i analizie predykcyjnej.
Uczenie się bez nadzoru
Uczenie bez nadzoru to gałąź uczenia maszynowego, która koncentruje się na analizie i grupowaniu nieoznakowanych zbiorów danych bez użycia predefiniowanych etykiet docelowych. W uczeniu bez nadzoru algorytmy są zaprojektowane do automatycznego wykrywania wzorców, podobieństw i różnic w danych. Odkrywając te ukryte struktury, uczenie bez nadzoru umożliwia badaczom i organizacjom uzyskanie cennych informacji i podejmowanie decyzji opartych na danych.
Podejście to jest szczególnie przydatne w eksploracyjnej analizie danych, gdzie celem jest zrozumienie podstawowej struktury danych i zidentyfikowanie potencjalnych wzorców lub relacji. Uczenie bez nadzoru znajduje również zastosowanie w różnych dziedzinach, takich jak segmentacja klientów, wykrywanie anomalii, systemy rekomendacji i rozpoznawanie obrazów.
Uczenie ze wzmocnieniem
Uczenie ze wzmocnieniem (RL) to gałąź uczenia maszynowego, która koncentruje się na tym, w jaki sposób inteligentni agenci mogą nauczyć się podejmować optymalne decyzje w środowisku, aby zmaksymalizować skumulowane nagrody. W przeciwieństwie do uczenia nadzorowanego, które opiera się na oznaczonych parach wejść/wyjść lub uczenia nienadzorowanego, które stara się odkryć ukryte wzorce, uczenie ze wzmocnieniem działa poprzez uczenie się na podstawie interakcji ze środowiskiem. Celem jest znalezienie równowagi między eksploracją, w której agent odkrywa nowe strategie, a eksploatacją, w której agent wykorzystuje swoją obecną wiedzę do podejmowania świadomych decyzji.
W uczeniu ze wzmocnieniem środowisko jest zazwyczaj opisywane jako Proces decyzyjny Markowa (MDP), co pozwala na wykorzystanie technik programowania dynamicznego. W przeciwieństwie do klasycznych metod programowania dynamicznego, algorytmy RL nie wymagają dokładnego modelu matematycznego MDP i są zaprojektowane do rozwiązywania problemów na dużą skalę, gdzie dokładne metody są niepraktyczne. Stosując techniki uczenia ze wzmocnieniem, agenci mogą dostosowywać i poprawiać swoje zdolności decyzyjne w czasie, co sprawia, że jest to potężne podejście do zadań takich jak autonomiczna nawigacja, robotyka, granie w gry i zarządzanie zasobami.
Algorytmy i techniki uczenia maszynowego
Algorytmy i techniki uczenia maszynowego oferują różnorodne możliwości i są stosowane w różnych dziedzinach do rozwiązywania złożonych problemów. Każdy algorytm ma swoje mocne i słabe strony, a zrozumienie ich charakterystyki może pomóc naukowcom i praktykom wybrać najbardziej odpowiednie podejście do ich konkretnych zadań. Wykorzystując te algorytmy, naukowcy mogą odblokować cenne spostrzeżenia z danych i podejmować świadome decyzje w swoich dziedzinach.
Lasy losowe
Random Forests to popularny algorytm w uczeniu maszynowym, który należy do kategorii uczenia zespołowego. Łączy on wiele drzew decyzyjnych w celu przewidywania lub klasyfikowania danych. Każde drzewo decyzyjne w lesie losowym jest trenowane na innym podzbiorze danych, a ostateczna prognoza jest określana przez agregację prognoz wszystkich poszczególnych drzew. Lasy losowe są znane ze swojej zdolności do obsługi złożonych zbiorów danych, zapewniania dokładnych prognoz i obsługi brakujących wartości. Są one szeroko stosowane w różnych dziedzinach, w tym w finansach, opiece zdrowotnej i rozpoznawaniu obrazów.
Algorytm głębokiego uczenia
Deep Learning to podzbiór uczenia maszynowego, który koncentruje się na szkoleniu sztucznych sieci neuronowych z wieloma warstwami w celu uczenia się reprezentacji danych. Algorytmy głębokiego uczenia, takie jak Konwolucyjne sieci neuronowe (CNN) i Rekurencyjne sieci neuronowe (RNN), osiągnęły niezwykły sukces w zadaniach takich jak rozpoznawanie obrazu i mowy, przetwarzanie języka naturalnego i systemy rekomendacji. Algorytmy głębokiego uczenia mogą automatycznie uczyć się hierarchicznych cech z surowych danych, umożliwiając im wychwytywanie skomplikowanych wzorców i dokonywanie bardzo dokładnych prognoz. Algorytmy głębokiego uczenia wymagają jednak dużych ilości oznaczonych danych i znacznych zasobów obliczeniowych do szkolenia. Aby dowiedzieć się więcej o uczeniu głębokim, odwiedź stronę Witryna IBM.
Procesy gaussowskie
Procesy gaussowskie są potężną techniką wykorzystywaną w uczeniu maszynowym do modelowania i tworzenia prognoz opartych na rozkładach prawdopodobieństwa. Są one szczególnie przydatne, gdy mamy do czynienia z małymi, zaszumionymi zbiorami danych. Procesy gaussowskie zapewniają elastyczne i nieparametryczne podejście, które może modelować złożone relacje między zmiennymi bez przyjmowania silnych założeń dotyczących podstawowego rozkładu danych. Są one powszechnie stosowane w regresji, gdzie celem jest oszacowanie ciągłego wyniku na podstawie cech wejściowych. Procesy Gaussa znajdują zastosowanie w takich dziedzinach jak geostatystyka, finanse i optymalizacja.
Zastosowanie uczenia maszynowego w nauce
Zastosowanie uczenia maszynowego w nauce otwiera nowe możliwości badawcze, umożliwiając naukowcom rozwiązywanie złożonych problemów, odkrywanie wzorców i prognozowanie na podstawie dużych i różnorodnych zbiorów danych. Wykorzystując moc uczenia maszynowego, naukowcy mogą uzyskać głębszy wgląd, przyspieszyć odkrycia naukowe i poszerzyć wiedzę w różnych dziedzinach nauki.
Obrazowanie medyczne
Uczenie maszynowe wniosło znaczący wkład w obrazowanie medyczne, rewolucjonizując możliwości diagnostyczne i prognostyczne. Algorytmy uczenia maszynowego mogą analizować obrazy medyczne, takie jak zdjęcia rentgenowskie, rezonans magnetyczny i tomografia komputerowa, aby pomóc w wykrywaniu i diagnozowaniu różnych chorób i stanów. Mogą one pomóc w identyfikacji anomalii, segmentacji narządów lub tkanek oraz przewidywaniu wyników leczenia pacjentów. Wykorzystując uczenie maszynowe w obrazowaniu medycznym, pracownicy służby zdrowia mogą zwiększyć dokładność i skuteczność swoich diagnoz, co prowadzi do lepszej opieki nad pacjentem i planowania leczenia.
Aktywna nauka
Aktywne uczenie się to technika uczenia maszynowego, która umożliwia algorytmowi interaktywne odpytywanie człowieka lub wyroczni o oznakowane dane. W badaniach naukowych aktywne uczenie może być cenne podczas pracy z ograniczonymi zestawami danych z etykietami lub gdy proces adnotacji jest czasochłonny lub kosztowny. Inteligentnie wybierając najbardziej informacyjne przypadki do etykietowania, algorytmy aktywnego uczenia mogą osiągnąć wysoką dokładność przy mniejszej liczbie etykietowanych przykładów, zmniejszając obciążenie związane z ręczną adnotacją i przyspieszając odkrycia naukowe.
Zastosowania naukowe
Uczenie maszynowe znajduje szerokie zastosowanie w różnych dyscyplinach naukowych. W genomice algorytmy uczenia maszynowego mogą analizować sekwencje DNA i RNA w celu identyfikacji odmian genetycznych, przewidywania struktur białek i zrozumienia funkcji genów. W materiałoznawstwie uczenie maszynowe jest wykorzystywane do projektowania nowych materiałów o pożądanych właściwościach, przyspieszania odkrywania materiałów i optymalizacji procesów produkcyjnych. Techniki uczenia maszynowego są również wykorzystywane w naukach o środowisku do przewidywania i monitorowania poziomów zanieczyszczeń, prognozowania pogody i analizowania danych klimatycznych. Co więcej, odgrywa ono kluczową rolę w fizyce, chemii, astronomii i wielu innych dziedzinach nauki, umożliwiając modelowanie, symulację i analizę opartą na danych.
Korzyści z uczenia maszynowego w nauce
Korzyści płynące z uczenia maszynowego w nauce są liczne i znaczące. Oto kilka kluczowych zalet:
Ulepszone modelowanie predykcyjne: Algorytmy uczenia maszynowego mogą analizować duże i złożone zbiory danych w celu identyfikacji wzorców, trendów i relacji, które mogą nie być łatwo rozpoznawalne za pomocą tradycyjnych metod statystycznych. Umożliwia to naukowcom opracowanie dokładnych modeli predykcyjnych dla różnych zjawisk naukowych i wyników, co prowadzi do bardziej precyzyjnych prognoz i lepszego podejmowania decyzji.
Zwiększona wydajność i automatyzacja: Techniki uczenia maszynowego automatyzują powtarzalne i czasochłonne zadania, pozwalając naukowcom skupić się na bardziej złożonych i kreatywnych aspektach badań. Algorytmy uczenia maszynowego mogą obsługiwać ogromne ilości danych, przeprowadzać szybką analizę oraz skutecznie generować spostrzeżenia i wnioski. Prowadzi to do zwiększenia produktywności i przyspieszenia tempa odkryć naukowych.
Ulepszona analiza i interpretacja danych: Algorytmy uczenia maszynowego doskonale radzą sobie z analizą danych, umożliwiając naukowcom wydobywanie cennych informacji z dużych i heterogenicznych zbiorów danych. Mogą one identyfikować ukryte wzorce, korelacje i anomalie, które mogą nie być od razu widoczne dla ludzkich badaczy. Techniki uczenia maszynowego pomagają również w interpretacji danych, zapewniając wyjaśnienia, wizualizacje i podsumowania, ułatwiając głębsze zrozumienie złożonych zjawisk naukowych.
Ułatwione wspomaganie decyzji: Modele uczenia maszynowego mogą służyć naukowcom jako narzędzia wspomagające podejmowanie decyzji. Analizując dane historyczne i informacje w czasie rzeczywistym, algorytmy uczenia maszynowego mogą pomagać w procesach decyzyjnych, takich jak wybór najbardziej obiecujących ścieżek badawczych, optymalizacja parametrów eksperymentalnych lub identyfikacja potencjalnego ryzyka lub wyzwań w projektach naukowych. Pomaga to naukowcom podejmować świadome decyzje i zwiększa szanse na osiągnięcie pomyślnych wyników.
Przyspieszone odkrycia naukowe: Uczenie maszynowe przyspiesza odkrycia naukowe, umożliwiając badaczom eksplorowanie ogromnych ilości danych, generowanie hipotez i skuteczniejsze weryfikowanie teorii. Wykorzystując algorytmy uczenia maszynowego, naukowcy mogą tworzyć nowe połączenia, odkrywać nowe spostrzeżenia i identyfikować kierunki badań, które w przeciwnym razie mogłyby zostać przeoczone. Prowadzi to do przełomów w różnych dziedzinach nauki i promuje innowacje.
Wizualne przekazywanie wiedzy naukowej za pomocą najlepszego i darmowego kreatora infografik
Mind the Graph jest cennym zasobem, który pomaga naukowcom w skutecznym wizualnym komunikowaniu swoich badań. Dzięki mocy najlepszego i darmowego kreatora infografik, platforma ta umożliwia naukowcom tworzenie angażujących i pouczających infografik, które wizualnie przedstawiają złożone koncepcje naukowe i dane. Niezależnie od tego, czy chodzi o prezentowanie wyników badań, wyjaśnianie procesów naukowych, czy wizualizację trendów danych, platforma Mind the Graph zapewnia naukowcom środki do wizualnego przekazywania ich nauki w sposób jasny i przekonujący. Zarejestruj się za darmo i zacznij tworzyć projekty już teraz.





Zapisz się do naszego newslettera
Ekskluzywne, wysokiej jakości treści na temat skutecznych efektów wizualnych
komunikacja w nauce.