
Regression analysis is an approach for identifying and analyzing the connection between one or more independent variables and a dependent variable. This method is extensively used in a variety of disciplines, including healthcare, social sciences, engineering, economics, and business. You can use regression analysis to investigate the fundamental relationships in data and develop predictive models that will assist you in making informed decisions.
Denne artikkelen gir deg en omfattende oversikt over regresjonsanalyse, inkludert hvordan den fungerer, et lettfattelig eksempel og en forklaring på hvordan den skiller seg fra korrelasjonsanalyse.
Hva er regresjonsanalyse?
Regresjonsanalyse er en statistisk metode for å identifisere og kvantifisere sammenhengen mellom en avhengig variabel og en eller flere uavhengige variabler. Kort sagt hjelper den deg med å forstå hvordan endringer i en eller flere uavhengige variabler henger sammen med endringer i den avhengige variabelen.
For å få en grundig forståelse av regresjonsanalyse må du først forstå følgende begreper:
- Avhengig variabel: Dette er variabelen du er interessert i å analysere eller forutsi. Det er utfallsvariabelen du prøver å forstå og forklare.
- Uavhengige variabler: Dette er de variablene som du tror har en effekt på den avhengige variabelen. De omtales ofte som prediktorvariabler, ettersom de brukes til å forutsi eller forklare endringer i den avhengige variabelen.
Regresjonsanalyse kan brukes i en rekke sammenhenger, blant annet for å forutsi fremtidige verdier av den avhengige variabelen, forstå effekten av uavhengige variabler på den avhengige variabelen og finne ekstremverdier eller uvanlige forekomster i datainnsamlingen.
Regression analysis can be classified into several types, including single linear regression, logistic regression, polynomial regression, and multiple regression. The suitable regression model is determined by the nature of the data and the investigation’s subject under consideration.
Hvordan fungerer regresjonsanalyse?
Formålet med regresjonsanalyse er å identifisere den linjen eller kurven som passer best til sammenhengen mellom de uavhengige variablene og den avhengige variabelen. Denne linjen eller kurven som passer best, genereres ved hjelp av statistiske metoder som reduserer forskjellene mellom forventede og reelle verdier i datainnsamlingen.
Her er formlene for de to vanligste typene regresjonsanalyse:
Enkel lineær regresjon
I enkel lineær regresjon bruker du en linje med best mulig tilpasning for å vise sammenhengen mellom to variabler: den uavhengige variabelen (x) og den avhengige variabelen (y).
Den beste tilpasningslinjen kan representeres ved ligningen: y = a + bx.
Her er a skjæringspunktet, mens b er linjens helning. For å beregne helningen bruker du formelen: b = (nΣ(xy) - ΣxΣy) / (nΣ(x2) - (Σx)2), hvor n er antall observasjoner, Σxy er summen av produktet av x og y, Σx og Σy er summen av henholdsvis x og y, og Σ(x2) er summen av kvadratene til x.
For å beregne skjæringspunktet bruker du formelen: a = (Σy - bΣx) / n.
Multippel regresjon
Multippel lineær regresjon:
Formelen for ligningen til den multiple lineære regresjonsmodellen er:
y = b0 + b1x1 + b2x2 + ... + bnxn
der y er den avhengige variabelen, x1, x2, ..., xn er de uavhengige variablene, og b0, b1, b2, ..., bn er koeffisientene til de uavhengige variablene.
Formelen for estimering av koeffisientene ved hjelp av minste kvadraters metode er:
β = (X'X)(-1)X'y
der β er en kolonnevektor av koeffisienter, X er designmatrisen av uavhengige variabler, X' er transponering av X, og y er vektoren av observasjoner av den avhengige variabelen.
Eksempel på regresjonsanalyse
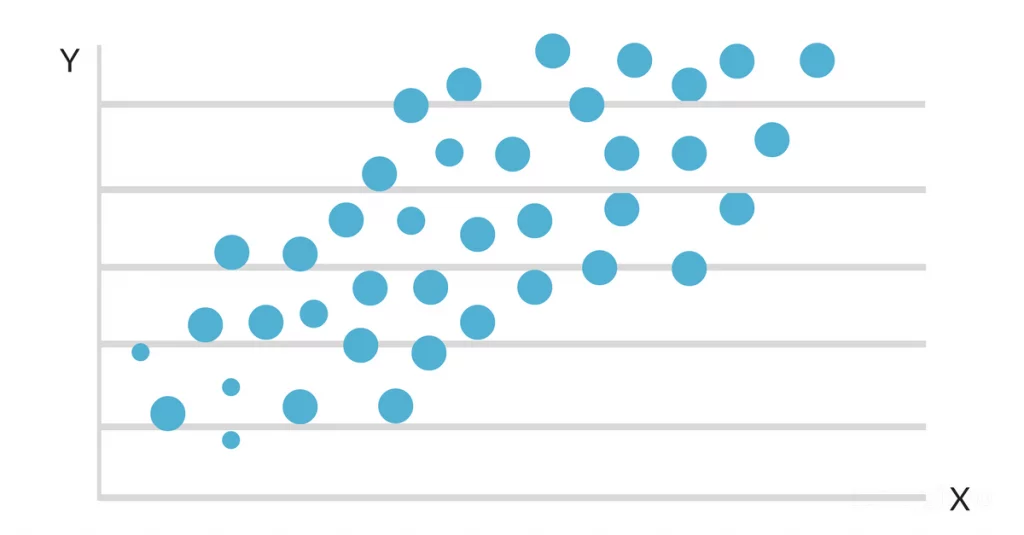
Anta at du ønsker å undersøke sammenhengen mellom en persons karaktersnitt (GPA) og antall timer vedkommende studerer per uke. Du samler inn informasjon fra et sett med studenter, inkludert antall studietimer og karaktersnitt.
Deretter kan du bruke regresjonsanalysen til å se om det er en lineær sammenheng mellom de to variablene, og i så fall kan du lage en modell som forutsier en students GPA basert på antall timer de studerer per uke.

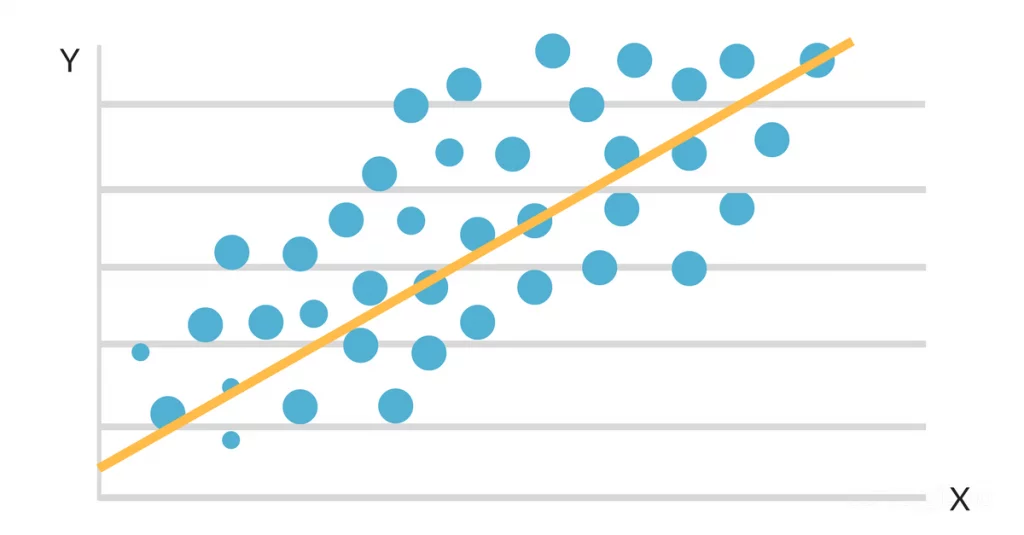
Når dataene plottes inn på et spredningskart, ser det ut til at det er en gunstig lineær sammenheng mellom studietid og GPA. Helling og skjæringspunkt for linjen med best mulig tilpasning estimeres deretter ved hjelp av en enkel lineær regresjonsmodell. Den endelige løsningen kan se slik ut:
GPA = 2,0 + 0,3 (timer studert per uke)
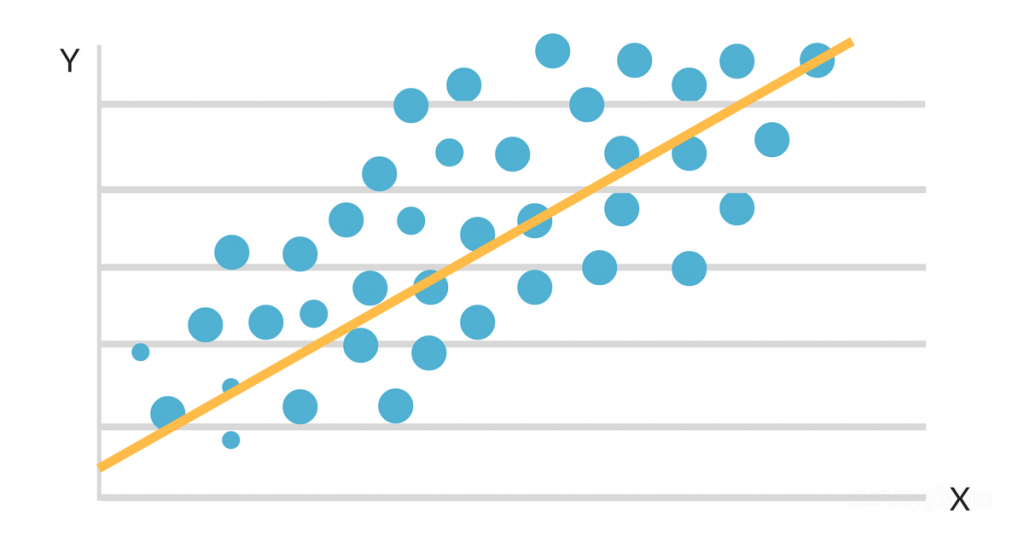
Denne ligningen sier at for hver ekstra time en student studerer per uke, vil karaktersnittet stige med 0,3 poeng, med alt annet likt. Denne algoritmen kan brukes til å forutsi en students GPA basert på hvor mange timer de studerer per uke, samt til å identifisere hvilke studenter som er i faresonen for å underprestere basert på studierutinene deres.
Ved hjelp av dataene fra eksemplet kan verdiene for b og a er som følger:
n = 10 (antall observasjoner)
Σx = 30 (summen av studietimene)
Σy = 25 (summen av GPA)
Σxy = 149 (summen av produktet av studietimer og GPA)
Σ(x)2 = 102 (summen av kvadratet av studietimene)
Bruk disse verdiene til å beregne b som:
b = (nΣ(xy) - ΣxΣy) / (nΣ(x2) - (Σx)2)
= (10 * 149 – 30 * 25) / (10 * 102 – 302)
= 0.3
Og beregne a som:
a = (Σy - bΣx) / n
= (25 – 0.3 * 30) / 10
= 2.0
Derfor er likningen for linjen med best mulig tilpasning:
GPA = 2,0 + 0,3 (timer studert per uke)
Hva er forskjellen mellom korrelasjon og regresjon?
Både korrelasjon og regresjon er statistiske metoder for å undersøke sammenhengen mellom to variabler. De tjener ulike formål og gir ulike typer informasjon.
Korrelasjon er et mål på styrken og forløpet av en sammenheng mellom to variabler. Den går fra -1 til +1, der -1 representerer en perfekt negativ korrelasjon, 0 representerer ingen korrelasjon og +1 representerer en perfekt positiv korrelasjon. Korrelasjon indikerer i hvilken grad to variabler henger sammen, men sier ikke noe om årsak eller forutsigbarhet.
Regression, on the other hand, is a method for modeling the connection between two variables, typically in order to forecast or explain one variable based on the other. Regression analysis can provide estimations of the size and direction of the relationship, as well as statistical significance tests, confidence ranges, and future result forecasts.
Dine kreasjoner, klare i løpet av få minutter
Mind the Graph is an online platform that offers you an extensive library of scientific illustrations and infographic designs that can be simply modified to meet your unique needs. Make professional-looking charts, posters, and graphical abstracts in minutes by using a drag-and-drop interface and a wide range of tools and features.



{kind=link}
{kind=link}

Abonner på nyhetsbrevet vårt
Eksklusivt innhold av høy kvalitet om effektiv visuell
kommunikasjon innen vitenskap.