
I nutidens hurtigt udviklende forskningslandskab har integrationen af kodning og programmering vist sig som en stærk kraft, der revolutionerer den måde, vi nærmer os videnskabelig undersøgelse på. Med den eksponentielle vækst i data og den stigende kompleksitet i forskningsspørgsmål er kodning blevet et vigtigt værktøj for forskere på tværs af en lang række discipliner.
Synergien mellem kodning og forskning rækker ud over dataanalyse. Gennem simulering og modellering kan forskere bruge kode til at skabe virtuelle eksperimenter og teste hypoteser in silico. Ved at emulere komplekse systemer og scenarier får forskere værdifuld indsigt i biologiske, fysiske og sociale fænomener, som kan være svære eller umulige at observere direkte. Sådanne simuleringer gør det muligt for forskere at lave forudsigelser, optimere processer og designe eksperimenter med større præcision og effektivitet.
Denne artikel undersøger den centrale rolle, som kodning spiller i forskning, og fremhæver dens transformative indvirkning på videnskabelig praksis og resultater.

Introduktion til kodning i forskning
Historien om kodning og programmering i forskningsmetoder er rig og fascinerende og præget af vigtige milepæle, der har haft indflydelse på, hvordan det videnskabelige samfund griber dataanalyse, automatisering og opdagelse an.
Kodning inden for forskning går tilbage til midten af det 20. århundrede, hvor fremskridt inden for computerteknologi skabte nye muligheder for behandling og analyse af data. I begyndelsen handlede kodning i høj grad om at designe programmeringssprog og algoritmer på lavt niveau til at løse matematiske problemer. Programmeringssprog som Fortran og COBOL blev skabt i denne periode og lagde fundamentet for yderligere fremskridt inden for forskningskodning.
Et vendepunkt blev nået i 1960'erne og 1970'erne, da forskerne indså, hvor effektiv kodning kunne være til at håndtere store mængder data. Fremkomsten af statistiske computersprog som SAS og SPSS i denne periode gav forskerne mulighed for at analysere datasæt hurtigere og udføre sofistikerede statistiske beregninger. Forskere inden for discipliner som samfundsvidenskab, økonomi og epidemiologi er nu afhængige af deres evne til at kode for at finde mønstre i deres data, teste hypoteser og udlede værdifulde indsigter.
I løbet af 1980'erne og 1990'erne blev antallet af personlige computere større, og kodningsværktøjerne blev mere tilgængelige. Integrerede udviklingsmiljøer (IDE'er) og grafiske brugergrænseflader (GUI'er) har mindsket adgangsbarriererne og hjulpet kodning med at blive en almindelig forskningsteknik ved at gøre den mere tilgængelig for et større spektrum af forskere. Udviklingen af scriptingsprog som Python og R gav også nye muligheder for dataanalyse, visualisering og automatisering, hvilket yderligere etablerede kodningens rolle i forskningen.
Den hurtige teknologiske udvikling i begyndelsen af det 21. århundrede drev big data-æraen frem og indvarslede en ny æra for kodning i akademisk forskning. For at få brugbare indsigter var forskerne nødt til at håndtere enorme mængder komplicerede og heterogene data, hvilket krævede avancerede kodningsmetoder.
Datavidenskab opstod som et resultat heraf, hvor man fusionerede kodningsekspertise med statistisk analyse, maskinlæring og datavisualisering. Med introduktionen af open source-frameworks og biblioteker som TensorFlow, PyTorch og sci-kit-learn har forskere nu adgang til kraftfulde værktøjer til at tackle udfordrende forskningsproblemer og maksimere potentialet i maskinlæringsalgoritmer.
I dag er kodning en afgørende del af forskningen inden for en lang række områder, fra naturvidenskab til samfundsvidenskab og meget mere. Det har udviklet sig til et universelt sprog, der gør det muligt for forskere at undersøge og analysere data, modellere og automatisere processer og simulere komplekse systemer. Kodning bliver brugt mere og mere, når det kombineres med banebrydende teknologier som kunstig intelligens, cloud computing og big data-analyse for at skubbe grænserne for forskning og hjælpe forskere med at løse vanskelige problemer og opdage nye indsigter.
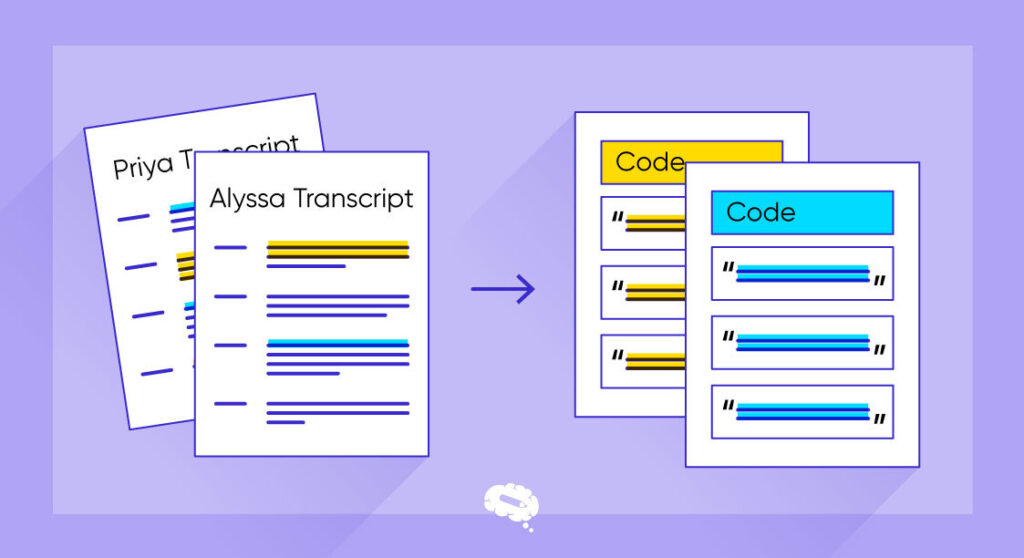
Typer af kodning i forskning
Der er mange forskellige typer og anvendelser af kodning i forskning, og forskere bruger dem til at forbedre deres studier. Her er et par af de vigtigste kodningstyper, der anvendes i forskning:
Dataanalyse Kodning
At skrive kode til at behandle, rense og analysere store og komplicerede datasæt er kendt som dataanalysekodning. Forskere kan lave statistiske undersøgelser, visualisere data og identificere mønstre eller tendenser ved at bruge kodesprog som Python, R, MATLAB eller SQL til at udvinde værdifuld indsigt.
Automatisering af kodning
Automatisering af gentagne opgaver og arbejdsgange i forskningsprocesser er emnet for automatiseringskodning. Forskere kan fremskynde dataindsamling, dataforberedelse, eksperimentelle procedurer eller rapportgenerering ved at skrive scripts eller programmer. Det sparer tid og sikrer konsistens mellem eksperimenter eller analyser.
Simulering og modellering Kodning
For at udvikle computerbaserede simuleringer eller modeller, der replikerer systemer eller fænomener fra den virkelige verden, bruger man simulering og modelleringskodning. Forskere kan teste hypoteser, undersøge komplekse systemers opførsel og undersøge scenarier, der kunne være udfordrende eller dyre at genskabe i den virkelige verden ved at anvende kodningssimulationer.
Maskinlæring og kunstig intelligens (AI)
Maskinlæring og AI-kodning indebærer at lære algoritmer og modeller at analysere information, identificere tendenser, forudsige resultater eller udføre bestemte opgaver. Inden for områder som billedanalyse, naturlig sprogbehandling eller prædiktiv analyse bruger forskere kodningsteknikker til at forbehandle data, konstruere og finjustere modeller, evaluere ydeevne og bruge disse modeller til at løse forskningsudfordringer.
Webudvikling og datavisualisering
Webudviklingskodning bruges i forskning til at producere interaktive webbaserede værktøjer, data dashboards eller onlineundersøgelser til at indsamle og vise data. For at kunne forklare forskningsresultaterne kan forskere også bruge kodning til at skabe plots, diagrammer eller interaktive visualiseringer.
Softwareudvikling og oprettelse af værktøjer
For at supplere deres forskning kan nogle forskere skabe specifikke softwareværktøjer eller applikationer. For at muliggøre datahåndtering, analyse eller eksperimentel kontrol indebærer denne type kodning at bygge, udvikle og vedligeholde softwareløsninger, der er tilpasset bestemte forskningsmål.
Fælles kodning
At arbejde på kodeprojekter med fagfæller eller kolleger er kendt som kollaborativ kodning. For at øge gennemsigtigheden, reproducerbarheden og den kollektive videnskabelige viden kan forskere deltage i kodegennemgange, bidrage til open source-projekter og dele deres kode og metodologi.
Metoder til kodning af kvalitative data
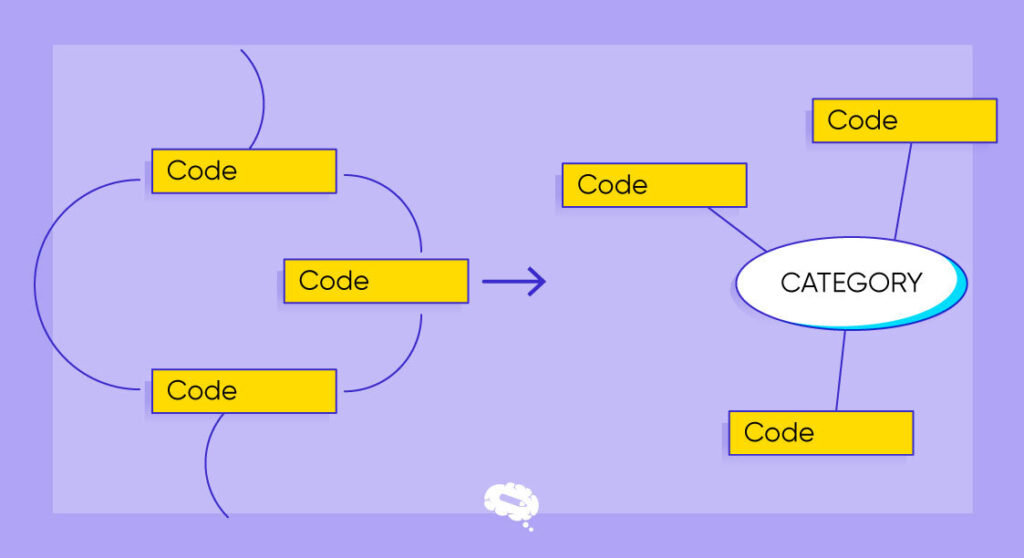
Forskere bruger en række forskellige teknikker, når de skal kode kvalitative data for at vurdere og skabe mening i de data, de har indsamlet. Følgende er nogle almindelige metoder til kodning af kvalitative data:
- Tematisk kodning: Forskere identificerer tilbagevendende temaer eller mønstre i data ved at tildele beskrivende koder til tekstsegmenter, der repræsenterer specifikke temaer, hvilket letter organisering og analyse af kvalitativ information.
- Beskrivende kodning: Det gør det muligt at skabe et indledende overblik og identificere forskellige aspekter eller dimensioner af det fænomen, der undersøges. Koder tildeles til datasegmenter baseret på indholdet eller kvaliteten af informationen.
- Kodning in vivo: Det bevarer autenticiteten og lægger vægt på levede erfaringer ved at bruge deltagernes egne ord eller sætninger som koder til at destillere deres erfaringer eller perspektiver.
- Konceptuel kodning: Det giver mulighed for at bruge allerede eksisterende teorier og etablere forbindelser mellem kvalitative data og teoretiske konstruktioner. Data kodes baseret på teoretiske begreber eller rammer, der er relevante for forskningen.
- Sammenlignende kodning: Systematiske sammenligninger mellem forskellige situationer eller personer foretages for at afdække ligheder og forskelle i data. Disse sammenligninger repræsenteres derefter af koder. Denne tilgang forbedrer forståelsen af variationer og finesser i datasættet.
- Mønsterkodning: I de kvalitative data finder man tilbagevendende mønstre eller sekvenser af hændelser og tildeler dem koder for at indikere mønstrene. Ved at afsløre tidsmæssige eller kausale forbindelser kaster mønsterkodning lys over underliggende dynamikker eller processer.
- Kodning af relationer: I de kvalitative data analyseres forbindelser, afhængigheder eller sammenhænge mellem forskellige begreber eller temaer. For at forstå interaktionerne og forbindelserne mellem mange forskellige dataelementer udvikler forskere koder, der beskriver disse relationer.
Fordele ved kodning af kvalitativ forskning
I forbindelse med databehandling har kodning af kvalitativ forskning en række fordele. For det første giver det den analytiske proces struktur og orden, så forskerne logisk kan kategorisere og organisere kvalitative data. Ved at reducere mængden af data er det lettere at identificere vigtige temaer og mønstre.
Kodning gør det desuden muligt at udforske dataene grundigt og afsløre kontekst og skjulte betydninger. Ved at tilbyde en dokumenteret og gentagelig proces forbedrer det også forskningens gennemsigtighed og stringens.
Kodning gør sammenligning og syntese af data mere ligetil, hjælper med at skabe teorier og giver dyb indsigt til fortolkning. Det giver tilpasningsevne, fleksibilitet og kapacitet til gruppeanalyse, hvilket fremmer konsensus og styrker pålideligheden af resultaterne.
Kodning giver en bedre forståelse af forskningsemnet ved at kombinere kvalitative data med andre forskningsmetoder.
Generelt forbedrer kodning af kvalitativ forskning kvaliteten, dybden og fortolkningskapaciteten af dataanalysen, så forskerne kan få indsigtsfuld viden og udvikle deres undersøgelsesområder.
Tips til kodning af kvalitative data
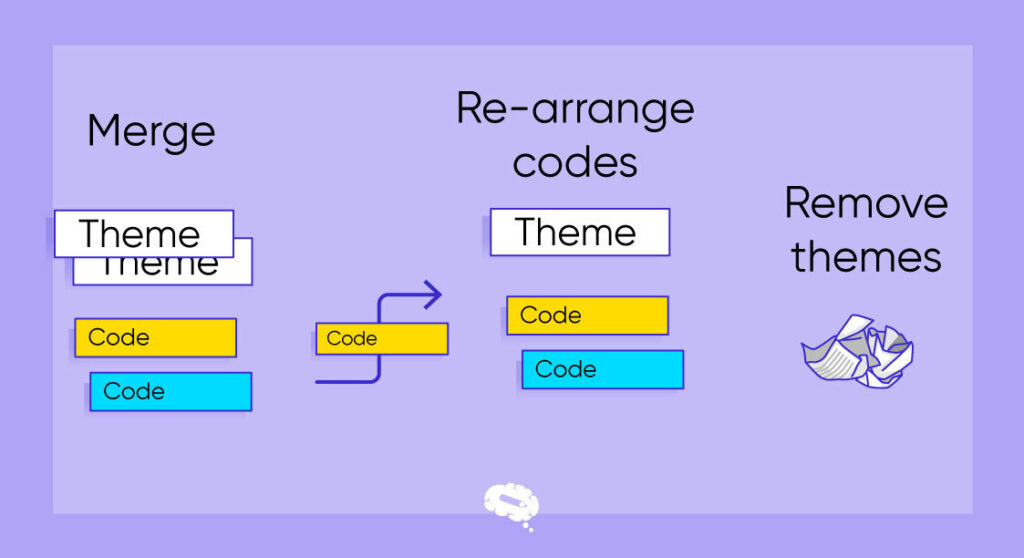
- Bliv fortrolig med dataene: Før du begynder kodningsprocessen, skal du grundigt forstå indholdet og konteksten af de kvalitative data ved at læse og fordybe dig i dem.
- Brug et kodningssystem: Uanset om du bruger deskriptive koder, tematiske koder eller en kombination af metoder, skal du skabe et klart og konsekvent kodningssystem. For at sikre ensartethed i hele undersøgelsen skal du beskrive dit kodningssystem skriftligt.
- Kod induktivt og deduktivt: Overvej at bruge både induktiv og deduktiv kodning for at indfange en bred vifte af ideer. Induktiv kodning indebærer at identificere temaer, der dukker op fra data; deduktiv kodning indebærer at bruge teorier eller begreber, der allerede eksisterer.
- Brug åben kodning til at begynde med: Start med vilkårligt at tildele koder til forskellige datasegmenter uden at bruge forudbestemte kategorier. Denne åbne kodningsstrategi muliggør udforskning og opdagelse af tidlige mønstre og temaer.
- Gennemgå og finpuds koder: Efterhånden som du gennemgår analysen, skal du regelmæssigt undersøge og justere koderne. Afklar definitioner, kombiner lignende koder, og sørg for, at koderne afspejler det indhold, de er tildelt.
- Opret et revisionsspor: Registrer dine kodningsbeslutninger, rationaler og tankeprocesser i detaljer. Dette revisionsspor fungerer som en reference for kommende analyser eller diskussioner og hjælper med at opretholde gennemsigtighed og reproducerbarhed.
Etiske overvejelser i kodning
Når man koder kvalitative data, skal etikken komme i første række. Prioritering af informeret samtykke kan hjælpe forskere med at sikre, at deltagerne har givet deres godkendelse til brug af data, herunder kodning og analyse. For at beskytte deltagernes navne og personlige oplysninger under kodningsprocessen er anonymitet og fortrolighed afgørende.
For at sikre upartiskhed og retfærdighed skal forskerne være reflekterede over personlige fordomme og deres indflydelse på kodningsbeslutninger. Det er vigtigt at respektere deltagernes meninger og erfaringer og at afholde sig fra at udnytte eller misrepræsentere dem.
Evnen til at genkende og formidle forskellige synspunkter med den rette kulturelle bevidsthed er uundværlig, ligesom det er vigtigt at behandle deltagerne med respekt og overholde indgåede aftaler.
Ved at forholde sig til disse etiske overvejelser opretholder forskerne deres integritet, beskytter deltagernes rettigheder og bidrager til en ansvarlig kvalitativ forskningspraksis.
Almindelige fejl, der skal undgås ved kodning i forskning
Når du koder i forskning, er det vigtigt at være opmærksom på almindelige fejl, der kan påvirke kvaliteten og nøjagtigheden af din analyse. Her er nogle fejl, du skal undgå:
- Mangel på præcise kodeinstruktioner: For at bevare konsistensen skal du sørge for, at der er eksplicitte kodningsinstruktioner.
- Overkodning eller underkodning: Find en balance mellem at indsamle vigtige detaljer og undgå en alt for grundig analyse.
- Ignorering eller afvisning af afvigende tilfælde: Anerkend og kod outliers for at få omfattende indsigt.
- Manglende konsekvens: Konsekvent anvendelse af kodningsregler og gennemgang af koder for pålidelighed.
- Mangel på interkoder-reliabilitet: Skab konsensus blandt teammedlemmerne for at løse uoverensstemmelser.
- Manglende dokumentation af kodningsbeslutninger: Oprethold et detaljeret revisionsspor for gennemsigtighed og fremtidig reference.
- Fordomme og antagelser: Vær opmærksom på fordomme, og stræb efter objektivitet i kodningen.
- Utilstrækkelig træning eller fortrolighed med data: Invester tid i at forstå dataene, og søg vejledning, hvis det er nødvendigt.
- Mangel på udforskning af data: Analysér dataene grundigt for at indfange deres rigdom og dybde.
- Manglende gennemgang og validering af koder: Gennemgå regelmæssigt kodningsskemaet og søg input til at forbedre det.
Slip kraften i infografik løs med Mind the Graph
Ved at give akademikere mulighed for at producere engagerende og iøjnefaldende infografik revolutionerer Mind the Graph den videnskabelige kommunikation. Platformen gør det muligt for forskere at overvinde konventionelle kommunikationsbarrierer og engagere et bredere publikum ved at forklare data, strømline komplicerede koncepter, booste præsentationer, opmuntre til samarbejde og tillade tilpasning. Udnyt kraften i infografik med Mind the Graph, og åbn op for nye veje til effektiv videnskabelig kommunikation.








Tilmeld dig vores nyhedsbrev
Eksklusivt indhold af høj kvalitet om effektiv visuel
kommunikation inden for videnskab.