
In der sich schnell entwickelnden Forschungslandschaft von heute hat sich die Integration von Kodierung und Programmierung zu einer starken Kraft entwickelt, die die Art und Weise, wie wir an wissenschaftliche Untersuchungen herangehen, revolutioniert. Angesichts des exponentiellen Datenwachstums und der zunehmenden Komplexität der Forschungsfragen ist die Kodierung zu einem unverzichtbaren Werkzeug für Forscher in einer Vielzahl von Disziplinen geworden.
Die Synergie zwischen Kodierung und Forschung geht über die Datenanalyse hinaus. Durch Simulation und Modellierung können Forscher mit Code virtuelle Experimente erstellen und Hypothesen in silico testen. Durch die Nachbildung komplexer Systeme und Szenarien gewinnen Forscher wertvolle Einblicke in das Verhalten biologischer, physikalischer und sozialer Phänomene, die sich nur schwer oder gar nicht direkt beobachten lassen. Solche Simulationen ermöglichen es den Forschern, Vorhersagen zu treffen, Prozesse zu optimieren und Experimente mit größerer Präzision und Effizienz zu planen.
Dieser Artikel befasst sich mit der zentralen Rolle, die das Kodieren in der Forschung spielt, und hebt seine transformative Wirkung auf wissenschaftliche Praktiken und Ergebnisse hervor.

Einführung in die Kodierung in der Forschung
Die Geschichte der Einbindung von Kodierung und Programmierung in Forschungsmethoden ist reichhaltig und faszinierend, unterbrochen von wichtigen Meilensteinen, die die Art und Weise beeinflusst haben, wie die wissenschaftliche Gemeinschaft Datenanalyse, Automatisierung und Entdeckung angeht.
Die Kodierung in der Forschung geht auf die Mitte des 20. Jahrhunderts zurück, als die Fortschritte in der Computertechnologie neue Möglichkeiten für die Verarbeitung und Analyse von Daten schufen. Anfangs ging es bei der Kodierung hauptsächlich um die Entwicklung von Low-Level-Programmiersprachen und Algorithmen zur Lösung mathematischer Probleme. In dieser Zeit wurden Programmiersprachen wie Fortran und COBOL entwickelt, die den Grundstein für weitere Fortschritte in der Forschungscodierung legten.
Ein Wendepunkt wurde in den 1960er und 1970er Jahren erreicht, als die Forscher erkannten, wie effektiv die Kodierung bei der Verwaltung großer Datenmengen sein kann. Das Aufkommen statistischer Computersprachen wie SAS und SPSS in diesem Zeitraum gab Forschern die Möglichkeit, Datensätze schneller zu analysieren und anspruchsvolle statistische Berechnungen durchzuführen. Forscher in Disziplinen wie den Sozial- und Wirtschaftswissenschaften und der Epidemiologie verlassen sich heute auf ihre Fähigkeit zu codieren, um Muster in ihren Daten zu finden, Hypothesen zu testen und wertvolle Erkenntnisse zu gewinnen.
In den 1980er und 1990er Jahren gab es immer mehr Personalcomputer und die Programmierwerkzeuge wurden leichter zugänglich. Integrierte Entwicklungsumgebungen (IDEs) und grafische Benutzeroberflächen (GUIs) haben die Einstiegshürden gesenkt und dazu beigetragen, dass das Programmieren zu einer verbreiteten Forschungstechnik wurde, indem es für ein größeres Spektrum von Forschern zugänglich gemacht wurde. Die Entwicklung von Skriptsprachen wie Python und R bot ebenfalls neue Möglichkeiten für die Datenanalyse, Visualisierung und Automatisierung, wodurch sich die Rolle des Codes in der Forschung weiter etablierte.
Die rasante technologische Entwicklung zu Beginn des 21. Jahrhunderts hat die Big-Data-Ära eingeläutet und eine neue Ära der Kodierung in der akademischen Forschung eingeleitet. Um nützliche Erkenntnisse zu gewinnen, mussten die Forscher mit enormen Mengen komplizierter und heterogener Daten umgehen, was fortschrittliche Kodierungsansätze erforderte.
Daraus entwickelte sich die Datenwissenschaft, die Programmierkenntnisse mit statistischer Analyse, maschinellem Lernen und Datenvisualisierung verbindet. Mit der Einführung von Open-Source-Frameworks und -Bibliotheken wie TensorFlow, PyTorch und sci-kit-learn haben Forscher nun Zugang zu leistungsstarken Werkzeugen, um anspruchsvolle Forschungsprobleme anzugehen und das Potenzial von Algorithmen für maschinelles Lernen zu maximieren.
Kodierung ist heute ein entscheidender Bestandteil der Forschung in einer Vielzahl von Bereichen, von den Naturwissenschaften bis zu den Sozialwissenschaften und darüber hinaus. Sie hat sich zu einer universellen Sprache entwickelt, die es Forschern ermöglicht, Daten zu untersuchen und zu analysieren, Prozesse zu modellieren und zu automatisieren und komplexe Systeme zu simulieren. In Kombination mit Spitzentechnologien wie künstlicher Intelligenz, Cloud Computing und Big-Data-Analysen wird Coding immer häufiger eingesetzt, um die Grenzen der Forschung zu erweitern und Wissenschaftlern zu helfen, schwierige Probleme zu lösen und neue Erkenntnisse zu gewinnen.
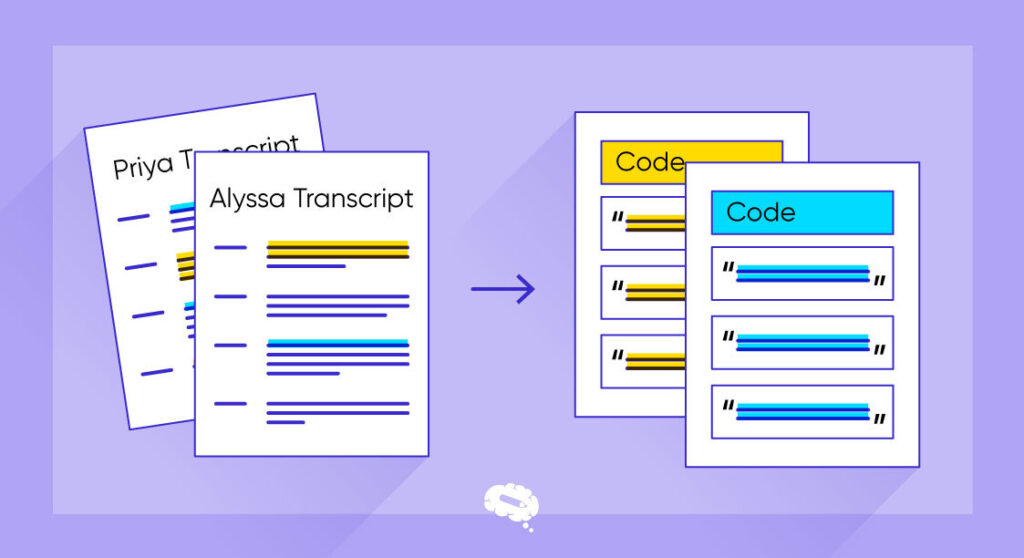
Arten der Kodierung in der Forschung
Es gibt viele verschiedene Arten und Anwendungen von Kodierung in der Forschung, und Forscher nutzen sie, um ihre Studien zu verbessern. Hier sind einige der wichtigsten Kodierungstypen, die in der Forschung verwendet werden:
Datenanalyse Kodierung
Das Schreiben von Code zur Verarbeitung, Bereinigung und Analyse umfangreicher und komplizierter Datensätze wird als Datenanalysecodierung bezeichnet. Forscher können statistische Studien durchführen, Daten visualisieren und Muster oder Trends erkennen, indem sie Programmiersprachen wie Python, R, MATLAB oder SQL verwenden, um wertvolle Erkenntnisse zu gewinnen.
Automatisierung Kodierung
Die Automatisierung von sich wiederholenden Aufgaben und Arbeitsabläufen in Forschungsprozessen ist das Thema der Automatisierungscodierung. Durch das Schreiben von Skripten oder Programmen können Forscher die Datenerfassung, die Datenaufbereitung, experimentelle Verfahren oder die Berichterstellung beschleunigen. Dies spart Zeit und gewährleistet die Konsistenz zwischen Experimenten oder Analysen.
Simulation und Modellierung Kodierung
Um computergestützte Simulationen oder Modelle zu entwickeln, die reale Systeme oder Phänomene nachbilden, werden Simulationen und Modellierungscodierung eingesetzt. Mit Hilfe von Simulationen können Forscher Hypothesen testen, das Verhalten komplexer Systeme untersuchen und Szenarien erforschen, deren Nachbildung in der realen Welt schwierig oder teuer wäre.
Maschinelles Lernen und künstliche Intelligenz (KI)
Beim maschinellen Lernen und der KI-Codierung geht es darum, Algorithmen und Modelle zu unterrichten, um Informationen zu analysieren, Trends zu erkennen, Ergebnisse vorherzusagen oder bestimmte Aufgaben auszuführen. In Bereichen wie der Bildanalyse, der Verarbeitung natürlicher Sprache oder der prädiktiven Analytik verwenden Forscher Kodierungstechniken, um Daten vorzuverarbeiten, Modelle zu erstellen und fein abzustimmen, die Leistung zu bewerten und diese Modelle zur Lösung von Forschungsaufgaben einzusetzen.
Webentwicklung und Datenvisualisierung
Webentwicklungscodierung wird in der Forschung verwendet, um interaktive webbasierte Tools, Daten-Dashboards oder Online-Umfragen zur Erfassung und Darstellung von Daten zu erstellen. Um die Forschungsergebnisse erfolgreich zu erläutern, können Forscher auch Kodierung verwenden, um Diagramme, Tabellen oder interaktive Visualisierungen zu erstellen.
Softwareentwicklung und Erstellung von Tools
Zur Ergänzung ihrer Forschung erstellen manche Forscher spezielle Software-Tools oder Anwendungen. Um die Datenverwaltung, die Analyse oder die Kontrolle von Experimenten zu ermöglichen, umfasst diese Art der Codierung den Aufbau, die Entwicklung und die Wartung von Softwarelösungen, die an bestimmte Forschungsziele angepasst sind.
Kollaborative Kodierung
Die Arbeit an Code-Projekten mit Gleichgesinnten oder Kollegen wird als kollaboratives Coding bezeichnet. Um die Transparenz, die Reproduzierbarkeit und das kollektive wissenschaftliche Wissen zu verbessern, können Forscher an Code-Reviews teilnehmen, zu Open-Source-Projekten beitragen und ihren Code und ihre Methodik teilen.
Methoden zur Kodierung qualitativer Daten
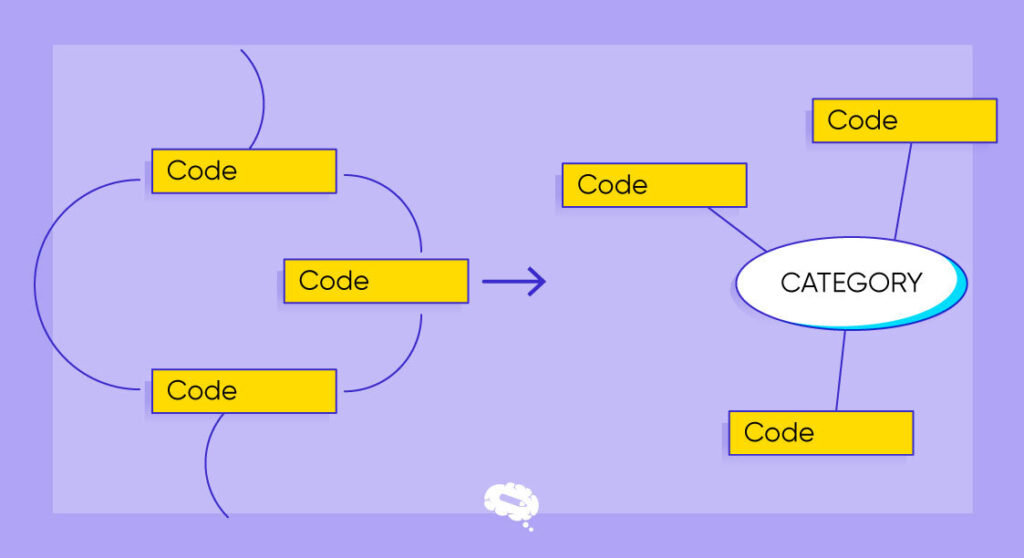
Bei der Kodierung qualitativer Daten verwenden Forscher eine Vielzahl von Techniken, um die gewonnenen Daten zu bewerten und ihnen einen Sinn zu geben. Im Folgenden werden einige gängige Methoden zur Kodierung qualitativer Daten vorgestellt:
- Thematische Kodierung: Forscher identifizieren wiederkehrende Themen oder Muster in den Daten, indem sie Textsegmenten, die bestimmte Themen repräsentieren, beschreibende Codes zuweisen, die die Organisation und Analyse qualitativer Informationen erleichtern.
- Deskriptive Kodierung: Sie ermöglicht die Erstellung eines ersten Überblicks und die Identifizierung verschiedener Aspekte oder Dimensionen des untersuchten Phänomens. Den Datensegmenten werden Codes zugewiesen, die auf dem Inhalt oder der Qualität der Informationen basieren.
- In-vivo-Codierung: Sie bewahrt die Authentizität und legt den Schwerpunkt auf gelebte Erfahrungen, indem sie die eigenen Worte oder Ausdrücke der Teilnehmer als Codes verwendet, um ihre Erfahrungen oder Perspektiven zu destillieren.
- Konzeptuelle Kodierung: Sie ermöglicht die Verwendung bereits bestehender Theorien und die Herstellung von Verbindungen zwischen qualitativen Daten und theoretischen Konstrukten. Die Daten werden auf der Grundlage von theoretischen Konzepten oder Rahmenwerken kodiert, die für die Forschung relevant sind.
- Vergleichende Kodierung: Systematische Vergleiche zwischen verschiedenen Situationen oder Personen werden durchgeführt, um Ähnlichkeiten und Unterschiede in den Daten aufzudecken. Diese Vergleiche werden dann durch Codes dargestellt. Dieser Ansatz verbessert das Verständnis von Abweichungen und Feinheiten im Datensatz.
- Kodierung von Mustern: In den qualitativen Daten werden wiederkehrende Muster oder Sequenzen von Vorkommnissen gefunden, denen Codes zugewiesen werden, um die Muster zu kennzeichnen. Indem zeitliche oder kausale Zusammenhänge aufgedeckt werden, gibt die Musterkodierung Aufschluss über die zugrunde liegende Dynamik oder den Prozess.
- Beziehungskodierung: Innerhalb der qualitativen Daten werden Verbindungen, Abhängigkeiten oder Verknüpfungen zwischen verschiedenen Konzepten oder Themen analysiert. Um die Wechselwirkungen und Verknüpfungen zwischen vielen verschiedenen Datenelementen zu verstehen, entwickeln die Forscher Codes, die diese Beziehungen beschreiben.
Vorteile der Kodierung in der qualitativen Forschung
Für die Datenverarbeitung hat die Kodierung in der qualitativen Forschung eine Reihe von Vorteilen. Erstens verleiht sie dem Analyseprozess Struktur und Ordnung und ermöglicht es den Forschern, qualitative Daten logisch zu kategorisieren und zu organisieren. Durch die Verringerung der Datenmenge ist es einfacher, wichtige Themen und Muster zu erkennen.
Die Kodierung ermöglicht außerdem eine gründliche Untersuchung der Daten, die den Kontext und verborgene Bedeutungen aufdeckt. Durch die Bereitstellung eines dokumentierten und wiederholbaren Prozesses wird auch die Transparenz und Strenge der Forschung verbessert.
Die Kodierung macht den Vergleich und die Synthese von Daten einfacher, hilft bei der Erstellung von Theorien und führt zu tieferen Einsichten für die Interpretation. Sie bietet Anpassungsfähigkeit, Flexibilität und die Möglichkeit der Gruppenanalyse, was den Konsens fördert und die Zuverlässigkeit der Ergebnisse stärkt.
Das Kodieren ermöglicht ein besseres Verständnis des Forschungsthemas durch die Kombination qualitativer Daten mit anderen Forschungsmethoden.
Generell verbessert die Kodierung in der qualitativen Forschung die Qualität, die Tiefe und die Interpretationsfähigkeit der Datenanalyse und ermöglicht es den Forschern, aufschlussreiche Erkenntnisse zu gewinnen und ihr Forschungsgebiet zu entwickeln.
Tipps zur Kodierung qualitativer Daten
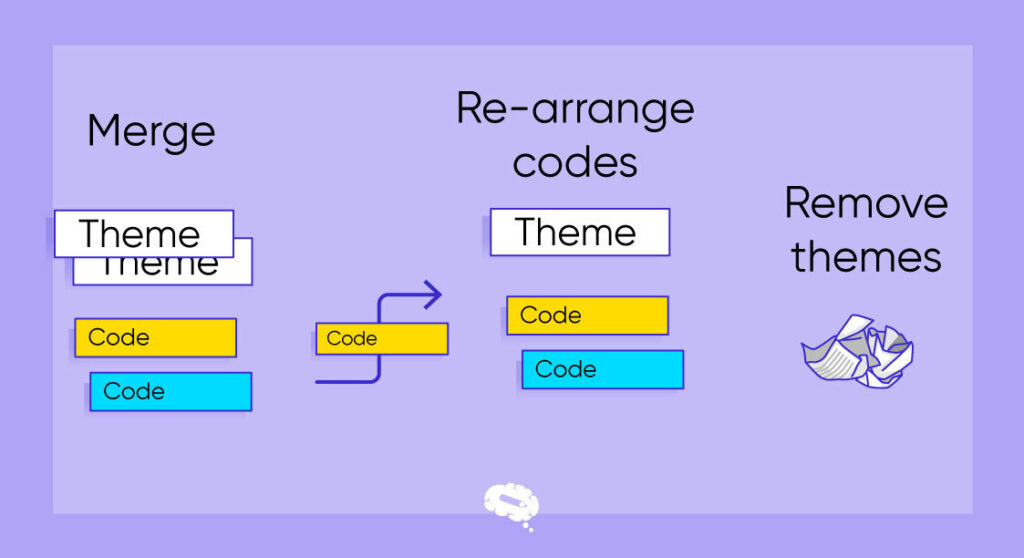
- Machen Sie sich mit den Daten vertraut: Bevor Sie mit dem Kodierungsprozess beginnen, sollten Sie den Inhalt und den Kontext der qualitativen Daten gründlich verstehen, indem Sie sie lesen und sich in sie vertiefen.
- Verwenden Sie ein Kodierungssystem: Egal, ob Sie deskriptive Codes, thematische Codes oder eine Kombination von Methoden verwenden, erstellen Sie ein klares und konsistentes Kodierungssystem. Beschreiben Sie Ihr Kodierungssystem schriftlich, um die Einheitlichkeit der gesamten Untersuchung zu gewährleisten.
- Induktiv und deduktiv kodieren: Erwägen Sie sowohl induktives als auch deduktives Kodieren, um ein breites Spektrum an Ideen zu erfassen. Beim induktiven Kodieren geht es um die Identifizierung von Themen, die sich aus den Daten ergeben; beim deduktiven Kodieren werden bereits vorhandene Theorien oder Konzepte verwendet.
- Verwenden Sie zunächst eine offene Kodierung: Beginnen Sie damit, verschiedenen Datensegmenten willkürlich Codes zuzuweisen, ohne vorgegebene Kategorien zu verwenden. Diese offene Kodierungsstrategie ermöglicht eine Exploration und die Entdeckung erster Muster und Themen.
- Überprüfung und Verfeinerung der Codes: Überprüfen Sie im Laufe der Analyse regelmäßig die Codes und nehmen Sie Anpassungen vor. Klären Sie die Definitionen, kombinieren Sie ähnliche Codes und stellen Sie sicher, dass die Codes den Inhalt, dem sie zugeordnet sind, angemessen widerspiegeln.
- Erstellen Sie einen Prüfpfad: Halten Sie Ihre Kodierungsentscheidungen, Begründungen und Gedankengänge sehr detailliert fest. Dieser Prüfpfad dient als Referenz für anstehende Analysen oder Diskussionen und hilft, Transparenz und Reproduzierbarkeit zu wahren.
Ethische Erwägungen bei der Kodierung
Bei der Kodierung qualitativer Daten muss die Ethik an erster Stelle stehen. Indem sie der informierten Zustimmung Vorrang einräumen, können Forscher sicherstellen, dass die Teilnehmer ihr Einverständnis zur Datennutzung, einschließlich Kodierung und Analyse, gegeben haben. Um die Namen und persönlichen Daten der Teilnehmer während des Kodierungsprozesses zu schützen, sind Anonymität und Vertraulichkeit unerlässlich.
Um Unparteilichkeit und Fairness zu gewährleisten, müssen die Forscher über persönliche Voreingenommenheit und deren Einfluss auf Kodierungsentscheidungen nachdenken. Es ist wichtig, die Meinungen und Erfahrungen der Teilnehmer zu respektieren und sie nicht auszunutzen oder falsch darzustellen.
Die Fähigkeit, unterschiedliche Standpunkte zu erkennen und zu vermitteln, ist ebenso unverzichtbar wie der respektvolle Umgang mit den Teilnehmern und die Einhaltung der getroffenen Vereinbarungen.
Durch die Berücksichtigung dieser ethischen Überlegungen wahren die Forscher die Integrität, schützen die Rechte der Teilnehmer und tragen zu einer verantwortungsvollen qualitativen Forschungspraxis bei.
Häufig zu vermeidende Fehler bei der Kodierung in der Forschung
Bei der Kodierung in der Forschung ist es wichtig, sich über häufige Fehler im Klaren zu sein, die die Qualität und Genauigkeit Ihrer Analyse beeinträchtigen können. Hier sind einige Fehler, die Sie vermeiden sollten:
- Mangel an präzisen Code-Anweisungen: Um die Kohärenz zu wahren, sollten explizite Kodierungsanweisungen gegeben werden.
- Überkodierung oder Unterkodierung: Finden Sie ein Gleichgewicht zwischen dem Sammeln wichtiger Details und dem Vermeiden einer zu gründlichen Analyse.
- Ignorieren oder Abweisen von abweichenden Fällen: Erkennen und kodieren Sie Ausreißer für umfassende Einblicke.
- Mangelnde Kohärenz: Konsistente Anwendung der Kodierungsregeln und Überprüfung der Kodes auf Zuverlässigkeit.
- Mangelnde Intercoder-Reliabilität: Stellen Sie einen Konsens zwischen den Teammitgliedern her, um Unstimmigkeiten zu beseitigen.
- Nicht dokumentierte Kodierungsentscheidungen: Führen Sie einen detaillierten Prüfpfad für Transparenz und zukünftige Referenzen.
- Vorurteile und Annahmen: Seien Sie sich Ihrer Vorurteile bewusst und bemühen Sie sich um Objektivität bei der Kodierung.
- Unzureichende Ausbildung oder Vertrautheit mit den Daten: Nehmen Sie sich Zeit, um die Daten zu verstehen, und lassen Sie sich bei Bedarf beraten.
- Fehlende Datenexploration: Analysieren Sie die Daten gründlich, um ihre Reichhaltigkeit und Tiefe zu erfassen.
- Versäumnis, Codes zu überprüfen und zu validieren: Regelmäßige Überprüfung und Einholung von Beiträgen zur Verfeinerung des Kodierungsschemas.
Entfesseln Sie die Macht der Infografik mit Mind the Graph
Mind the Graph revolutioniert die wissenschaftliche Kommunikation, indem es Wissenschaftlern die Möglichkeit gibt, ansprechende und auffällige Infografiken zu erstellen. Die Plattform ermöglicht es Wissenschaftlern, herkömmliche Kommunikationsbarrieren zu überwinden und ein breiteres Publikum anzusprechen, indem sie Daten erfolgreich erklärt, komplizierte Konzepte vereinfacht, Präsentationen verbessert, die Zusammenarbeit fördert und Anpassungen ermöglicht. Nutzen Sie die Macht der Infografik mit Mind the Graph und erschließen Sie neue Wege für eine wirkungsvolle wissenschaftliche Kommunikation.








Abonnieren Sie unseren Newsletter
Exklusive, qualitativ hochwertige Inhalte über effektive visuelle
Kommunikation in der Wissenschaft.