
In today’s rapidly evolving research landscape, the integration of coding and programming has emerged as a powerful force, revolutionizing the way we approach scientific inquiry. With the exponential growth of data and the increasing complexity of research questions, coding has become an essential tool for researchers across a wide range of disciplines.
The synergy between coding and research extends beyond data analysis. Through simulation and modeling, researchers can use code to create virtual experiments and test hypotheses in silico. By emulating complex systems and scenarios, researchers gain valuable insights into the behavior of biological, physical, and social phenomena that may be difficult or impossible to observe directly. Such simulations enable researchers to make predictions, optimize processes, and design experiments with greater precision and efficiency.
This article explores the pivotal role that coding plays in research, highlighting its transformative impact on scientific practices and outcomes.

Introduction to Coding in Research
The history of coding and programming incorporation into research methodologies is rich and fascinating, punctuated by important milestones that influenced how the scientific community approaches data analysis, automation, and discovery.
Coding in research dates back to the middle of the 20th century, when advances in computing technology created new opportunities for the processing and analysis of data. In the beginning, coding was largely concerned with the design of low-level programming languages and algorithms to address mathematical issues. Programming languages like Fortran and COBOL were created during this time period, laying the foundation for further advancements in research coding.
A turning point was reached in the 1960s and 1970s when researchers realized how effective coding might be at managing massive amounts of data. The emergence of statistical computer languages like SAS and SPSS during this time period gave researchers the ability to analyze data sets more quickly and carry out sophisticated statistical calculations. Researchers in disciplines like social sciences, economics, and epidemiology now rely on their ability to code in order to find patterns in their data, test hypotheses, and derive valuable insights.
Personal computers increased and coding tools became more accessible during the 1980s and 1990s. Integrated development environments (IDEs) and graphical user interfaces (GUIs) have decreased entrance barriers and helped coding become a common research technique by making it more accessible to a larger spectrum of researchers. The development of scripting languages like Python and R also provided new opportunities for data analysis, visualization, and automation, further establishing coding’s role in research.
The fast development of technology at the turn of the 21st century drove the big data era and ushered in a new era of coding in academic research. In order to extract useful insights, researchers had to deal with enormous amounts of complicated and heterogeneous data, which called for advanced coding approaches.
Data science emerged as a result, merging coding expertise with statistical analysis, machine learning, and data visualization. With the introduction of open-source frameworks and libraries like TensorFlow, PyTorch, and sci-kit-learn, researchers now have access to powerful tools for tackling challenging research problems and maximizing the potential of machine learning algorithms.
Today, coding is a crucial component of research in a wide range of fields, from the natural sciences to the social sciences and beyond. It has evolved into a universal language that enables researchers to examine and analyze data, model and automate processes, and simulate complex systems. Coding is being used more and more when combined with cutting-edge technologies like artificial intelligence, cloud computing, and big data analytics to push the boundaries of research and help scientists solve difficult problems and discover novel insights.
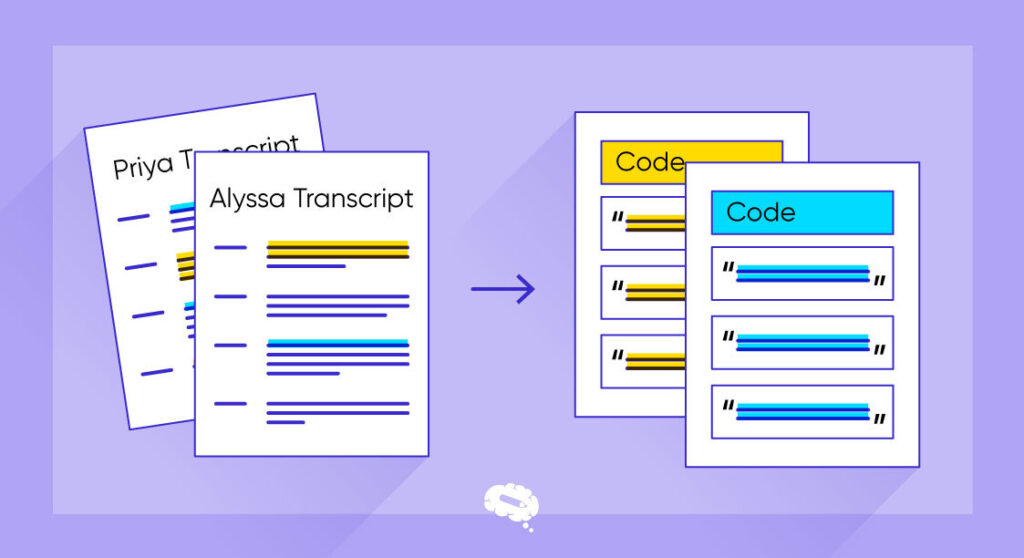
Types of Coding in Research
There are many different types and applications of coding used in research, and researchers use them to improve their studies. Here are a few of the main coding types that are employed in research:
Data Analysis Coding
Writing code to process, clean, and analyze sizable and complicated datasets is known as data analysis coding. Researchers can do statistical studies, visualize data, and identify patterns or trends by using coding languages like Python, R, MATLAB, or SQL to extract valuable insights.
Automation Coding
Automating repetitive tasks and workflows in research processes is the subject of automation coding. Researchers can speed up data collecting, data preparation, experimental procedures, or report generation by writing scripts or programs. This saves time and ensures consistency between experiments or analyses.
Simulation and Modeling Coding
To develop computer-based simulations or models that replicate real-world systems or phenomena, simulation, and modeling coding are utilized. Researchers can test hypotheses, examine the behavior of complex systems, and investigate scenarios that could be challenging or expensive to recreate in the real world by employing coding simulations.
Machine Learning and Artificial Intelligence (AI)
Machine learning and AI coding entail teaching algorithms and models to analyze information, identify trends, forecast outcomes, or carry out certain tasks. In fields like image analysis, natural language processing, or predictive analytics, researchers use coding techniques to preprocess data, construct and fine-tune models, evaluate performance, and use these models to solve research challenges.
Web Development and Data Visualization
Web development coding is used in research to produce interactive web-based tools, data dashboards, or online surveys to gather and display data. To successfully explain the results of research, researchers may also use coding to create plots, charts, or interactive visualizations.
Software Development and Tool Creation
To complement their research, some researchers may create specific software tools or applications. To enable data management, analysis, or experimental control, this type of coding entails building, developing, and maintaining software solutions adapted to particular research aims.
Collaborative Coding
Working on coding projects with peers or colleagues is known as collaborative coding. To increase transparency, reproducibility, and collective scientific knowledge, researchers can participate in code reviews, contribute to open-source projects, and share their code and methodology.
Methods of Coding Qualitative Data
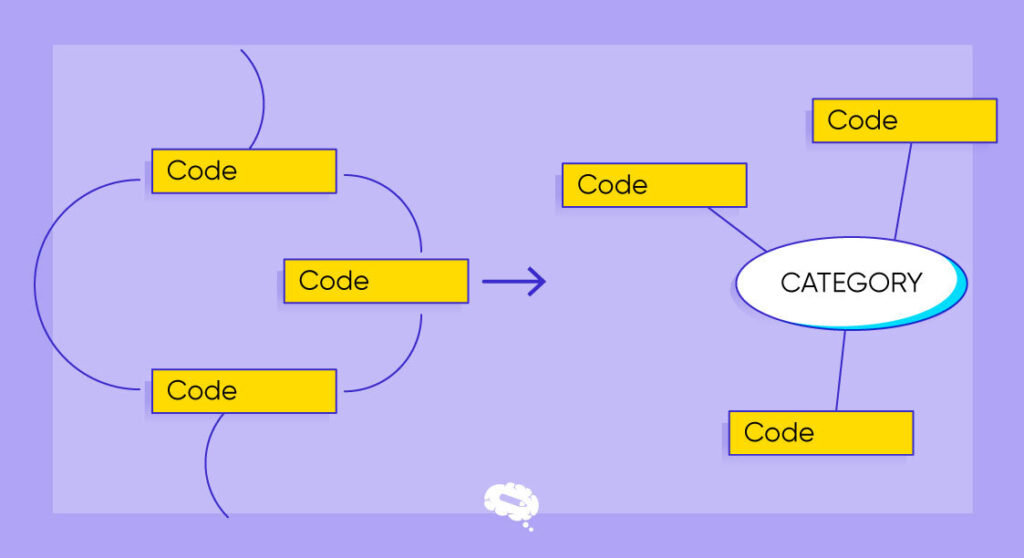
Researchers use a variety of techniques when it comes to coding qualitative data to assess and make sense of the data they have acquired. Following are some common methods for coding qualitative data:
- Thematic Coding: Researchers identify recurring themes or patterns in the data by assigning descriptive codes to segments of text that represent specific themes, facilitating organization and analysis of qualitative information.
- Descriptive Coding: It allows for the creation of an initial overview and the identification of different aspects or dimensions of the phenomenon under research. Codes are allocated to data segments based on the content or qualities of the information.
- In Vivo Coding: It preserves authenticity and puts an emphasis on lived experiences by using participants’ own words or phrases as codes to distill their experiences or perspectives.
- Conceptual Coding: It allows for the use of pre-existing theories and the establishment of connections between qualitative data and theoretical constructs. Data are coded based on theoretical concepts or frameworks pertinent to the research.
- Comparative coding: Systematic comparisons between different situations or individuals are undertaken to uncover similarities and differences in the data. These comparisons are then represented by codes. This approach improves comprehension of variances and subtleties in the data set.
- Pattern coding: In the qualitative data, recurring patterns or sequences of occurrences are found, and codes are assigned to them to indicate the patterns. By revealing temporal or causal connections, pattern coding sheds light on underlying dynamics or processes.
- Relationship Coding: Within the qualitative data, connections, dependencies, or linkages between different concepts or themes are analyzed. In order to understand the interactions and linkages between many different data items, researchers develop codes that describe these relationships.
Advantages of Qualitative Research Coding
For data processing, qualitative research coding has a number of advantages. Firstly, it gives the analytic process structure and order, enabling researchers to logically categorize and organize qualitative data. By reducing the amount of data, it is easier to identify important themes and patterns.
Coding additionally makes it possible to thoroughly explore the data, revealing context and hidden meanings. By offering a documented and repeatable process, it also improves the research’s transparency and rigor.
Coding makes data comparison and synthesis more straightforward, aids in the creation of theories, and produces deep insights for interpretation. It provides adaptability, flexibility, and the capacity for group analysis, which promotes consensus and strengthens the reliability of findings.
Coding enables an improved understanding of the research topic by combining qualitative data with other research methods.
In general, qualitative research coding improves the quality, depth, and interpretive capacity of data analysis, allowing researchers to gain insightful knowledge and develop their fields of study.
Tips for Coding Qualitative Data
- Become familiar with the data: Before starting the coding process, thoroughly understand the content and context of the qualitative data by reading and immersing yourself in it.
- Utilize a coding system: Whether utilizing descriptive codes, thematic codes, or a combination of methods, create a clear and consistent coding system. To ensure uniformity throughout the research, describe your coding system in writing.
- Code inductively and deductively: Consider using both inductive and deductive coding to capture a wide range of ideas. Inductive coding involves identifying themes that emerge from the data; deductive coding involves using theories or concepts that already exist.
- Use open coding initially: Start by arbitrarily assigning codes to different data segments without using predetermined categories. This open coding strategy enables exploration and the discovery of early patterns and themes.
- Review and refine codes: As you move through the analysis, regularly examine and make adjustments to the codes. Clarify definitions, combine similar codes, and make sure that codes appropriately reflect the content to which they are assigned.
- Establish an audit trail: Record your coding decisions, rationales, and thought processes in great detail. This audit trail serves as a reference for upcoming analysis or discussions and helps to maintain transparency and reproducibility.
Ethical Considerations in Coding
When coding qualitative data, ethics must come first. Prioritizing informed consent can help researchers ensure that participants have given their approval for data usage, including coding and analysis. In order to protect participants’ names and personal information during the coding process, anonymity and confidentiality are essential.
To ensure impartiality and fairness, researchers must be reflective about personal biases and their influence on coding decisions. It is important to respect the opinions and experiences of participants and to refrain from exploiting or misrepresenting them.
The ability to recognize and convey different points of view with proper cultural awareness is indispensable, as well as treating participants with respect and upholding any agreements made.
By addressing these ethical considerations, researchers uphold integrity, protect participants’ rights, and contribute to responsible qualitative research practices.
Common Mistakes to Avoid in Coding in Research
When coding in research, it’s important to be aware of common mistakes that can impact the quality and accuracy of your analysis. Here are some mistakes to avoid:
- Lack of precise code instructions: To preserve consistency, make sure there are explicit coding instructions.
- Overcoding or undercoding: Strike a balance between gathering important details and avoiding overly thorough analysis.
- Ignoring or dismissing deviant cases: Acknowledge and code outliers for comprehensive insights.
- Failure to maintain consistency: Consistently apply coding rules and review codes for reliability.
- Lack of intercoder reliability: Establish consensus among team members to address discrepancies.
- Not documenting coding decisions: Maintain a detailed audit trail for transparency and future reference.
- Bias and assumptions: Stay aware of biases and strive for objectivity in coding.
- Insufficient training or familiarity with data: Invest time in understanding the data and seek guidance if needed.
- Lack of data exploration: Thoroughly analyze the data to capture its richness and depth.
- Failure to review and validate codes: Regularly review and seek input to refine the coding scheme.
Unleash the Power of Infographics with Mind the Graph
By giving academics the means to produce engaging and eye-catching infographics, Mind the Graph revolutionizes scientific communication. The platform enables scientists to overcome conventional communication barriers and engage wider audiences by successfully explaining data, streamlining complicated concepts, boosting presentations, encouraging cooperation, and allowing customization. Embrace the power of infographics with Mind the Graph and unlock new avenues for impactful scientific communication.








Subscribe to our newsletter
Exclusive high quality content about effective visual
communication in science.