
Data analysis, which guides decisions in a wide variety of domains, is a crucial part of statistics. Bayesian statistics have an intuitive and flexible framework, which distinguishes them from other statistical methodologies. Here’s a guide to Bayesian statistics for beginners, illuminating its foundational principles, practical applications, and inherent benefits. This article introduces the concept of Bayesian inference, which involves updating beliefs based on new evidence, to help readers understand its profound influence on decision-making. In this blog, we will demystify Bayesian statistics for beginners, and then show its relevance and utility in diverse real-world examples. Through clear explanations and illustrative examples, readers will gain a deeper appreciation for Bayesian methods and their significance in contemporary statistical practice.
Foundations Of Bayesian Statistics
In the realm of statistics, there exists a powerful framework that goes beyond mere numbers and p-values. With Bayesian statistics, probability is more than just a measure of frequency – it is a reflection of our beliefs and uncertainties. Bayesian statistics is based on the principles of priors, likelihoods, and posterior distributions, which will be explored in this blog post.
Bayesian statistics uses a different paradigm for analyzing probability data. Probability refers to our belief that an event is likely to occur, rather than its frequency. Three distributions make up Bayesian analysis: prior, likelihood, and posterior.
Bayes’ theorem is the cornerstone of Bayesian statistics, which guides the updating of our beliefs based on new evidence. With Bayes’ theorem, prior beliefs are combined with observed data to arrive at posterior probabilities. By formalizing inference, it refines our understanding of the world. This can be expressed mathematically as follows:
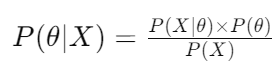
Bayesian theorem example from Wikipedia.
- P(θ∣X) is the posterior probability of the parameters given the observed data X
- P(X∣θ) is the likelihood of observing the data given the parametersθ.
- P(θ) is the prior probability of the parameters
- P(X) is the marginal likelihood, also known as the evidence
Key Concepts
- Prior Distribution: We begin by encapsulating our initial beliefs about the parameters of interest in a prior distribution before observing any data. Bayesian inference is based on this distribution and represents our uncertainty.
- Likelihood Function: This function calculates the likelihood that observed data and parameter values will be compatible. By comparing different parameter values with the observed outcomes, we can evaluate how well the model fits the data.
- Posterior Distribution: In order to obtain a posterior distribution, we apply Bayes’ theorem to our prior beliefs. The parameters in the distribution have been updated based on both prior knowledge and observations. Taking into account the available evidence, it encapsulates the uncertainty remaining.
Bayesian Inferences
Bayesian inference is a fundamental concept of Bayesian statistics, which is used to make predictions, draw conclusions, and update beliefs based on evidence. Bayesian inference differs from frequentist inference by incorporating prior knowledge into the posterior distribution, which represents updated beliefs, by incorporating observed data.
Based on both prior knowledge and observed data, Bayesian inference estimates the probability distribution of unknown parameters. Here are some examples of Bayesian inference in action:
- Medical Diagnosis: For example, suppose a patient exhibits symptoms of a rare disease. To update the probability of the patient having the disease, Bayesian inference combines prior knowledge about the prevalence of the disease with observed symptoms.
- Climate Modeling: Bayesian inference is used in climate modeling to estimate parameters and make predictions about future climate trends by combining prior knowledge of physical processes with observed climate data. Using this approach, scientists can quantify uncertainty and assess climate change’s impact.
- Drug Development: Bayesian inferences are used in pharmaceutical research to integrate preclinical and early clinical data with new experimental data to optimize drug development processes. As a result, researchers can make more efficient decisions regarding drug efficacy, safety, and dosage when developing new drugs.
- Genomics and Personalized Medicine: Genetic variants that are associated with diseases or traits are identified using Bayesian inference in genomics. Genetic mutations can be detected and treated more accurately using Bayesian methods when prior knowledge about genetic inheritance patterns and population genetics is incorporated.
- Particle Physics: Bayesian inference is used in particle physics experiments to analyze complex data from colliders and detectors. Researchers use Bayesian methods to distinguish signal events from background noise, estimate particle interaction parameters, and discover new particles and phenomena.
Prior And Posterior Distributions
In Bayesian statistics, prior and posterior distributions play a pivotal role in updating our beliefs about parameters of interest in light of observed data. Let’s delve deeper into these concepts:
Prior Distributions
Prior distributions describe what we knew about the parameters before we observed any data. In the absence of observational evidence, they serve as a mathematical representation of uncertainty. Inferences made based on prior distributions can have a significant effect on the results.
As we estimate parameters, we use the prior distribution to reflect our understanding, experience, or subjective beliefs regarding these parameters. As a result, it guides posterior inference as a regularization mechanism. Depending on the strength of prior beliefs, the data may have varying degrees of influence on the final conclusion.
Different priors can have profound effects on posterior distributions. Consider a simple coin toss experiment as an example of estimating success rates. Even with limited data suggesting otherwise, the posterior distribution may still remain close to 0.5 if we have strong prior beliefs that the coin is fair. Conversely, a skeptical prior favoring extreme values might result in a posterior distribution reflecting that skepticism, despite overwhelming contrary evidence.
Posterior Distributions
A posterior distribution represents our updated beliefs about a parameter after incorporating observed data. Based on Bayes’ theorem, the likelihood of the data given the parameters and their prior distribution are combined to compute them. A posterior distribution becomes increasingly dependent on the likelihood function as more data are observed, which quantifies how strongly different parameter values are supported by the data.
Hence, the posterior distribution reflects a synthesis of our prior beliefs and the observed data. The posterior distribution can then be used to make predictions about future events. It can also be used to compare different hypotheses and determine their likelihood of being true. The posterior distribution can also be used to make decisions and evaluate the consequences of different choices. It can also be used to allocate resources and optimize decisions.
Continuing with the coin toss example, we compute the posterior distribution of the coin’s bias based on a series of coin toss outcomes. In combination with our prior beliefs and the information provided by the observed data, this posterior distribution represents our updated belief about the coin’s bias.
Bayesian Models
Based on observed evidence, Bayesian models can be used to analyze data and make predictions by incorporating prior knowledge. As we proceed through this section, we will examine some key aspects of Bayesian modeling, including linear regression and hierarchical modeling. We will also discuss some applications of Bayesian models, such as causal inference and machine learning. Finally, we will discuss the strengths and weaknesses of Bayesian models.
Linear Regression In Bayesian Framework
In statistics, linear regression models the relationship between a dependent variable and an independent variable. The Bayesian framework extends linear regression by incorporating prior distributions over regression coefficients and errors. This allows for more accurate estimation of regression parameters and better handling of outliers. Additionally, Bayesian linear regression models can handle missing data and censored observations.
Key aspects of Bayesian linear regression include:
- Selection of appropriate prior distributions for regression coefficients and error terms.
- The posterior distribution of regression parameters is obtained by updating prior beliefs based on observed data.
- Using the posterior distribution to make predictions for new observations, accounting for uncertainty in the model parameters.
Bayesian linear regression offers several advantages, including:
- The ability to model complex relationships between variables with flexibility.
- Enhancing parameter estimation by incorporating prior knowledge.
- Prediction uncertainty can be quantified, which is essential for decision-making under uncertainty.
Hierarchical Modeling And Its Advantages
The hierarchy modeling approach is a Bayesian approach that allows the modeling of complex data structures which have multiple levels of variability in terms of the underlying variables. In this method, parameters are arranged in a hierarchy, so that higher-level parameters capture variation at the group level, and lower-level parameters capture variation at the individual level. This allows researchers to estimate the effects of higher-level parameters without having to examine the effects of lower-level parameters. It also allows researchers to more easily identify patterns in the data that are difficult to spot with other methods.
Advantages of hierarchical modeling include:
- Using information from multiple groups to improve parameter estimation: Pooling the information from multiple groups for better accuracy.
- Shrinkage is incorporated in estimations to reduce overfitting and improve generalization.
- Support for hierarchical or nested data structures, such as multilevel or longitudinal data.
- When data exhibit hierarchical structures and group-level effects, hierarchical modeling is particularly useful in education, healthcare, and social sciences.
By using Bayesian models such as linear regression and hierarchical modeling, researchers and practitioners can gain deeper insights while accounting effectively for uncertainty and prior knowledge.
Bayesian Model Comparison
Choosing the right Bayesian model for a dataset or problem is crucial when using Bayesian statistics. Based on observed data, Bayesian model comparison methodologies provide a rigorous framework for assessing the relative performance of competing models. In this section, we explore some of the key concepts involved in Bayesian model comparison.
Comparing Bayesian models involves evaluating the evidence provided by the data for each candidate model. By using probabilistic measures, Bayesian methods directly quantify the support for competing models, unlike frequentist approaches which often rely on hypothesis testing and p-values.
Bayes Factors And Model Selection
The concept of Bayes factors is at the heart of Bayesian model comparison. Bayes factors quantify the strength of evidence supporting one model over another, taking into account both the fit and complexity of the models. It represents the ratio of the marginal likelihoods of the two models under consideration. Evidence favoring the first model is indicated by a Bayes factor greater than 1, while evidence favoring the second model is indicated by a Bayes factor less than 1.
In Bayesian analysis, Bayes factors provide a principled approach to model selection. It is possible to identify the best model by comparing Bayes factors across different models, thus preventing overfitting and allowing robust inference to be made.
Cross-Validation And Its Role In Model Assessment
The cross-validation of Bayesian models is another effective tool for assessing their performance. A cross-validation process involves dividing the dataset into training and validation sets, fitting the model to the training data and then evaluating it on the validation data. Various subsets of data are used for training and validation, which allows for a more accurate estimation of the model’s accuracy.
A variety of cross-validation techniques can be used to assess model accuracy and generalization ability, including Bayesian cross-validation, LOO-CV, and K-fold cross-validation. These methods provide complementary information to Bayes factors by evaluating how well the models can make predictions on new, unseen data. These techniques also provide an estimation of how sensitive the model is to changes in the data, which can help to identify potential sources of bias.
By balancing model complexity and predictive performance with Bayesian factors and cross-validation methods, researchers can make informed decisions about model selection.
Advantages Of Using Bayesian Statistics
Bayesian statistics is a powerful and flexible framework for statistical inference and modeling, with advantages ranging from the ability to incorporate prior information to its robustness in handling uncertainty. Here are some advantages:
- The incorporation of prior knowledge or beliefs: Bayesian statistics has the advantage of incorporating prior knowledge or beliefs about parameters being estimated. Especially in situations where historical data or expert opinions are available, this allows for a more flexible and intuitive way of making inferences.
- Quantification of Uncertainty: The posterior distribution in Bayesian statistics is a natural way to quantify uncertainty associated with parameter estimates. Practitioners can then assess the likelihood of all plausible values and their associated probabilities for a parameter, not just the most likely one.
- Handling of Small Sample Sizes: Bayesian methods provide a coherent way to combine prior knowledge with observed data when dealing with small sample sizes. When frequentist methods fail to provide meaningful results, this method often leads to more stable and reliable estimates.
- Flexibility in Model Building: Bayesian statistics can accommodate complex data structures and relationships with a wide range of modeling techniques. The use of hierarchical models is particularly useful in fields like epidemiology, ecology, and finance because they can be used to model dependencies between parameters at different levels.
- Model Comparison and Selection: Based on the data, Bayesian statistics can be used to compare competing models and select the most appropriate one. Practitioners can assess relative evidence for different models using Bayes factors and posterior model probabilities that take both goodness of fit and complexity into account.
- Prediction and Decision Making: Using Bayesian statistics for predictive inference and decision making is natural because it explicitly models uncertainty in predictions and outcomes. Practitioners can make optimal decisions by considering the costs and benefits of different actions through decision-theoretic approaches like Bayesian decision theory.
- Adaptability to outliers and extreme values: As Bayesian methods employ prior information to help stabilize parameter estimates, they tend to be more robust to outliers and extreme values. Especially in fields with variable data quality or frequent extreme observations, this can be beneficial.
Challenges And Limitations
There are many advantages and limitations to Bayesian statistics, but they can be helpful when inferring and making decisions. For practitioners to apply Bayesian methods effectively, they must understand these aspects. Consider these key factors:
Common Challenges In Bayesian Statistics
- Bayesian analysis is often computationally complex, especially when dealing with high-dimensional data or intricate models. Markov Chain Monte Carlo (MCMC) methods can help solve these computational challenges.
- It can be subjective to choose appropriate prior distributions, which can have an impact on the posterior inference. Bringing informative and non-informative priors together while incorporating domain knowledge can be challenging.
- An important step in Bayesian analysis is specifying the model structure and assumptions. Model misspecification can result in biased inferences and erroneous conclusions, emphasizing the importance of model diagnostics and sensitivity analysis.
Addressing Misconceptions And Pitfalls
- The assumption that Bayesian analysis is completely subjective due to prior beliefs is a common misconception. Using Bayesian methods, prior knowledge and observation data are combined with probabilistic principles to generate objective posterior estimates.
- Another pitfall is overreliance on priors, which can result in biased results. Inference can be mitigated by sensitivity analyses, robustness checks, and hierarchical models.
Limitations Of Bayesian Methods And Potential Areas For Improvement
- It is still computationally demanding to perform Bayesian analysis, especially with large datasets and complex models, despite advances in computational techniques such as MCMC. Parallel computing methods and scalable algorithms are ongoing research topics.
- Nonlinear and non-Gaussian models may limit Bayesian methods’ applicability in certain domains. In order to address this limitation, alternative model formulations and approximate inference techniques can be explored.
- In deep learning applications, where traditional Bayesian methods may not scale efficiently, integrating Bayesian approaches with machine learning algorithms remains a challenge. Bringing Bayesian statistics and machine learning together is an exciting research area in the future.
The Bayesian approach offers numerous advantages, but its implementation presents numerous challenges and limitations. Bayesian methods in various domains can be fully harnessed by practitioners who understand these aspects and apply appropriate strategies.
Using A Free Infographic Maker, You Can Create Easy-To-Understand Infographics About Your Discoveries
With this game-changer in academia, research and dissertations will be more straightforward. You can easily integrate visuals into your drafts using Mind the Graph‘s powerful tools, enhancing clarity and resulting in more citations. By involving your audience visually in your research, you can increase the impact and accessibility of your work. Mind the Graph is a powerful tool for creating compelling infographics which can be used to enhance your scientific communication. Visit our website for more information.








Subscribe to our newsletter
Exclusive high quality content about effective visual
communication in science.