
Nos últimos anos, o aprendizado de máquina surgiu como uma ferramenta poderosa no campo da ciência, revolucionando a maneira como os pesquisadores exploram e analisam dados complexos. Com sua capacidade de aprender padrões automaticamente, fazer previsões e descobrir percepções ocultas, o aprendizado de máquina abriu novos caminhos para a pesquisa científica. Este artigo tem o objetivo de destacar o papel crucial do aprendizado de máquina na ciência, explorando sua ampla gama de aplicações, os avanços feitos nesse campo e o potencial que ele tem para novas descobertas. Compreendendo a operação do aprendizado de máquina, os cientistas estão ampliando os limites do conhecimento, desvendando fenômenos intrincados e abrindo caminho para inovações revolucionárias.
O que é aprendizado de máquina?
A aprendizagem automática é um ramo da Inteligência Artificial (IA) que se concentra no desenvolvimento de algoritmos e modelos que permitem que os computadores aprendam com os dados e façam previsões ou tomem decisões sem serem explicitamente programados. Envolve o estudo de técnicas estatísticas e computacionais que permitem que os computadores analisem e interpretem automaticamente padrões, relacionamentos e dependências nos dados, levando à extração de percepções e conhecimentos valiosos.
Artigo relacionado: Inteligência Artificial na Ciência
Aprendizado de máquina na ciência
A aprendizagem automática surgiu como uma ferramenta poderosa em várias disciplinas científicas, revolucionando a maneira como os pesquisadores analisam e interpretam conjuntos de dados complexos. Na ciência, as técnicas de aprendizado de máquina são empregadas para enfrentar diversos desafios, como prever estruturas de proteínas, classificar objetos astronômicos, modelar padrões climáticos e identificar padrões em dados genéticos. Os cientistas podem treinar algoritmos de aprendizado de máquina para descobrir padrões ocultos, fazer previsões precisas e obter uma compreensão mais profunda de fenômenos complexos, utilizando grandes volumes de dados. A aprendizagem automática na ciência não apenas aumenta a eficiência e a precisão da análise de dados, mas também abre novos caminhos para a descoberta, permitindo que os pesquisadores abordem questões científicas complexas e acelerem os avanços em seus respectivos campos.
Tipos de aprendizado de máquina
Alguns tipos de aprendizado de máquina abrangem uma ampla gama de abordagens e técnicas, cada uma delas adequada a diferentes domínios de problemas e características de dados. Os pesquisadores e profissionais podem escolher a abordagem mais adequada para suas tarefas específicas e aproveitar o poder do aprendizado de máquina para extrair insights e tomar decisões informadas. Aqui estão alguns dos tipos de aprendizado de máquina:
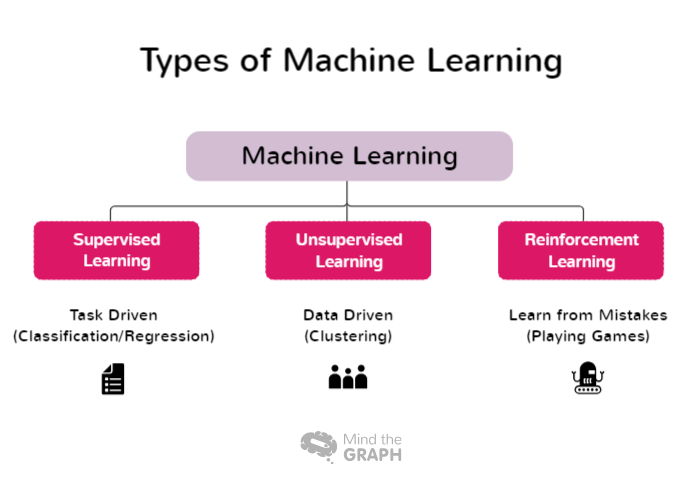
Aprendizagem supervisionada
O aprendizado supervisionado é uma abordagem fundamental no aprendizado de máquina em que o modelo é treinado usando conjuntos de dados rotulados. Nesse contexto, dados rotulados referem-se a dados de entrada que são emparelhados com rótulos de saída ou de destino correspondentes. O objetivo da aprendizagem supervisionada é permitir que o modelo aprenda padrões e relações entre os recursos de entrada e seus rótulos correspondentes, permitindo que ele faça previsões ou classificações precisas em dados novos e não vistos.
Durante o processo de treinamento, o modelo ajusta iterativamente seus parâmetros com base nos dados rotulados fornecidos, buscando minimizar a diferença entre suas saídas previstas e os rótulos verdadeiros. Isso permite que o modelo generalize e faça previsões precisas sobre dados não vistos. O aprendizado supervisionado é amplamente utilizado em vários aplicativos, incluindo reconhecimento de imagens, reconhecimento de fala, processamento de linguagem natural e análise preditiva.
Aprendizado não supervisionado
O aprendizado não supervisionado é um ramo do aprendizado de máquina que se concentra na análise e no agrupamento de conjuntos de dados não rotulados sem o uso de rótulos de destino predefinidos. Na aprendizagem não supervisionada, os algoritmos são projetados para detectar automaticamente padrões, semelhanças e diferenças nos dados. Ao descobrir essas estruturas ocultas, a aprendizagem não supervisionada permite que pesquisadores e organizações obtenham percepções valiosas e tomem decisões orientadas por dados.
Essa abordagem é particularmente útil na análise exploratória de dados, em que o objetivo é entender a estrutura subjacente dos dados e identificar possíveis padrões ou relacionamentos. O aprendizado não supervisionado também encontra aplicações em vários domínios, como segmentação de clientes, detecção de anomalias, sistemas de recomendação e reconhecimento de imagens.
Aprendizagem por reforço
O aprendizado por reforço (RL) é um ramo do aprendizado de máquina que se concentra em como os agentes inteligentes podem aprender a tomar decisões ideais em um ambiente para maximizar as recompensas cumulativas. Diferentemente da aprendizagem supervisionada, que se baseia em pares de entrada/saída rotulados, ou da aprendizagem não supervisionada, que busca descobrir padrões ocultos, a aprendizagem por reforço opera aprendendo com as interações com o ambiente. A intenção é encontrar um equilíbrio entre a exploração, em que o agente descobre novas estratégias, e o aproveitamento, em que o agente aproveita seu conhecimento atual para tomar decisões informadas.
No aprendizado por reforço, o ambiente é normalmente descrito como um Processo de decisão de Markov (MDP), que permite o uso de técnicas de programação dinâmica. Diferentemente dos métodos clássicos de programação dinâmica, os algoritmos de RL não exigem um modelo matemático exato do MDP e são projetados para lidar com problemas de grande escala em que os métodos exatos são impraticáveis. Ao aplicar técnicas de aprendizagem por reforço, os agentes podem se adaptar e melhorar suas habilidades de tomada de decisão ao longo do tempo, o que torna essa abordagem poderosa para tarefas como navegação autônoma, robótica, jogos e gerenciamento de recursos.
Algoritmos e técnicas de aprendizado de máquina
Os algoritmos e as técnicas de aprendizado de máquina oferecem diversos recursos e são aplicados em vários domínios para resolver problemas complexos. Cada algoritmo tem seus próprios pontos fortes e fracos, e a compreensão de suas características pode ajudar os pesquisadores e profissionais a escolher a abordagem mais adequada para suas tarefas específicas. Ao aproveitar esses algoritmos, os cientistas podem obter insights valiosos dos dados e tomar decisões informadas em seus respectivos campos.
Florestas aleatórias
Random Forests é um algoritmo popular em aprendizado de máquina que se enquadra na categoria de aprendizado de conjunto. Ele combina várias árvores de decisão para fazer previsões ou classificar dados. Cada árvore de decisão na floresta aleatória é treinada em um subconjunto diferente dos dados, e a previsão final é determinada pela agregação das previsões de todas as árvores individuais. As Random Forests são conhecidas por sua capacidade de lidar com conjuntos de dados complexos, fornecer previsões precisas e lidar com valores ausentes. Elas são amplamente usadas em vários campos, incluindo finanças, saúde e reconhecimento de imagens.
Algoritmo de aprendizado profundo
A aprendizagem profunda é um subconjunto da aprendizagem automática que se concentra no treinamento de redes neurais artificiais com várias camadas para aprender representações de dados. Os algoritmos de aprendizagem profunda, como Redes neurais convolucionais (CNNs) e Redes neurais recorrentes (RNNs), obtiveram sucesso notável em tarefas como reconhecimento de imagem e fala, processamento de linguagem natural e sistemas de recomendação. Os algoritmos de aprendizagem profunda podem aprender automaticamente recursos hierárquicos a partir de dados brutos, o que lhes permite capturar padrões complexos e fazer previsões altamente precisas. No entanto, os algoritmos de aprendizagem profunda exigem grandes quantidades de dados rotulados e recursos computacionais substanciais para o treinamento. Para saber mais sobre a aprendizagem profunda, acesse o site Site da IBM.
Processos Gaussianos
Os processos gaussianos são uma técnica poderosa usada no aprendizado de máquina para modelar e fazer previsões com base em distribuições de probabilidade. Eles são particularmente úteis ao lidar com conjuntos de dados pequenos e ruidosos. Os processos gaussianos oferecem uma abordagem flexível e não paramétrica que pode modelar relações complexas entre variáveis sem fazer suposições rígidas sobre a distribuição de dados subjacente. Eles são comumente usados em problemas de regressão, em que o objetivo é estimar um resultado contínuo com base em recursos de entrada. Os Processos Gaussianos têm aplicações em áreas como geoestatística, finanças e otimização.
Aplicação do aprendizado de máquina na ciência
A aplicação do aprendizado de máquina na ciência abre novos caminhos para a pesquisa, permitindo que os cientistas resolvam problemas complexos, descubram padrões e façam previsões com base em conjuntos de dados grandes e diversificados. Ao aproveitar o poder do aprendizado de máquina, os cientistas podem obter insights mais profundos, acelerar a descoberta científica e avançar o conhecimento em vários domínios científicos.
Imagens médicas
O aprendizado de máquina fez contribuições significativas para a geração de imagens médicas, revolucionando os recursos de diagnóstico e prognóstico. Os algoritmos de aprendizado de máquina podem analisar imagens médicas, como raios X, ressonâncias magnéticas e tomografias computadorizadas, para ajudar na detecção e no diagnóstico de várias doenças e condições. Eles podem ajudar a identificar anomalias, segmentar órgãos ou tecidos e prever os resultados dos pacientes. Ao aproveitar o aprendizado de máquina na geração de imagens médicas, os profissionais da área de saúde podem aumentar a precisão e a eficiência de seus diagnósticos, o que leva a um melhor atendimento ao paciente e ao planejamento do tratamento.
Aprendizagem ativa
A aprendizagem ativa é uma técnica de aprendizagem de máquina que permite que o algoritmo consulte interativamente um ser humano ou um oráculo para obter dados rotulados. Na pesquisa científica, a aprendizagem ativa pode ser valiosa quando se trabalha com conjuntos de dados rotulados limitados ou quando o processo de anotação é demorado ou caro. Ao selecionar de forma inteligente as instâncias mais informativas para rotulagem, os algoritmos de aprendizagem ativa podem obter alta precisão com menos exemplos rotulados, reduzindo o ônus da anotação manual e acelerando a descoberta científica.
Aplicações científicas
O aprendizado de máquina encontra ampla aplicação em várias disciplinas científicas. Na genômica, os algoritmos de aprendizado de máquina podem analisar sequências de DNA e RNA para identificar variações genéticas, prever estruturas de proteínas e entender as funções dos genes. Na ciência dos materiais, o aprendizado de máquina é empregado para projetar novos materiais com as propriedades desejadas, acelerar a descoberta de materiais e otimizar os processos de fabricação. As técnicas de aprendizado de máquina também são usadas na ciência ambiental para prever e monitorar os níveis de poluição, fazer previsões meteorológicas e analisar dados climáticos. Além disso, ela desempenha um papel fundamental na física, na química, na astronomia e em muitos outros campos científicos, permitindo a modelagem, a simulação e a análise orientadas por dados.
Benefícios do aprendizado de máquina na ciência
Os benefícios do aprendizado de máquina na ciência são numerosos e impactantes. Aqui estão algumas das principais vantagens:
Modelagem preditiva aprimorada: Os algoritmos de aprendizado de máquina podem analisar conjuntos de dados grandes e complexos para identificar padrões, tendências e relações que podem não ser facilmente reconhecíveis por meio de métodos estatísticos tradicionais. Isso permite que os cientistas desenvolvam modelos preditivos precisos para vários fenômenos e resultados científicos, o que leva a previsões mais precisas e a uma melhor tomada de decisões.
Aumento da eficiência e da automação: As técnicas de aprendizado de máquina automatizam tarefas repetitivas e demoradas, permitindo que os cientistas concentrem seus esforços em aspectos mais complexos e criativos da pesquisa. Os algoritmos de aprendizado de máquina podem lidar com grandes quantidades de dados, realizar análises rápidas e gerar percepções e conclusões com eficiência. Isso leva ao aumento da produtividade e acelera o ritmo das descobertas científicas.
Análise e interpretação de dados aprimoradas: Os algoritmos de aprendizado de máquina são excelentes na análise de dados, permitindo que os cientistas extraiam insights valiosos de conjuntos de dados grandes e heterogêneos. Eles podem identificar padrões ocultos, correlações e anomalias que podem não ser imediatamente aparentes para os pesquisadores humanos. As técnicas de aprendizado de máquina também ajudam na interpretação de dados, fornecendo explicações, visualizações e resumos, facilitando uma compreensão mais profunda de fenômenos científicos complexos.
Suporte facilitado à decisão: Os modelos de aprendizado de máquina podem servir como ferramentas de apoio à decisão para cientistas. Ao analisar dados históricos e informações em tempo real, os algoritmos de aprendizado de máquina podem ajudar nos processos de tomada de decisão, como selecionar os caminhos de pesquisa mais promissores, otimizar parâmetros experimentais ou identificar possíveis riscos ou desafios em projetos científicos. Isso ajuda os cientistas a tomar decisões informadas e aumenta as chances de obter resultados bem-sucedidos.
Descoberta científica acelerada: O aprendizado de máquina acelera a descoberta científica ao permitir que os pesquisadores explorem grandes quantidades de dados, gerem hipóteses e validem teorias com mais eficiência. Ao aproveitar os algoritmos de aprendizado de máquina, os cientistas podem fazer novas conexões, descobrir novos insights e identificar direções de pesquisa que, de outra forma, poderiam ter sido ignoradas. Isso leva a avanços em vários campos científicos e promove a inovação.
Comunique a ciência visualmente com o poder do melhor e mais gratuito criador de infográficos
Mind the Graph é um recurso valioso que ajuda os cientistas a comunicar visualmente suas pesquisas de forma eficaz. Com o poder do melhor e mais gratuito criador de infográficos, essa plataforma permite que os cientistas criem infográficos envolventes e informativos que retratam visualmente conceitos e dados científicos complexos. Seja para apresentar resultados de pesquisas, explicar processos científicos ou visualizar tendências de dados, a plataforma Mind the Graph fornece aos cientistas os meios para comunicar visualmente sua ciência de forma clara e convincente. Registre-se gratuitamente e comece a criar um design agora mesmo.





Assine nossa newsletter
Conteúdo exclusivo de alta qualidade sobre visual eficaz
comunicação na ciência.