
Viime vuosina koneoppiminen on noussut tehokkaaksi työkaluksi tieteen alalla ja mullistanut tutkijoiden tavan tutkia ja analysoida monimutkaisia tietoja. Koneoppiminen on avannut uusia väyliä tieteelliselle tutkimukselle, sillä se kykenee automaattisesti oppimaan malleja, tekemään ennusteita ja paljastamaan piilotettuja oivalluksia. Tämän artikkelin tavoitteena on korostaa koneoppimisen keskeistä roolia tieteessä tarkastelemalla sen laajaa sovellusvalikoimaa, alalla saavutettuja edistysaskeleita ja sen tarjoamia mahdollisuuksia uusille keksinnöille. Koneoppimisen toimintaa ymmärtävät tiedemiehet laajentavat tiedon rajoja, selvittävät monimutkaisia ilmiöitä ja tasoittavat tietä uraauurtaville innovaatioille.
Mitä on koneoppiminen?
Koneellinen oppiminen on Tekoäly (AI), jossa keskitytään kehittämään algoritmeja ja malleja, joiden avulla tietokoneet voivat oppia tiedoista ja tehdä ennusteita tai päätöksiä ilman nimenomaista ohjelmointia. Se käsittää sellaisten tilastollisten ja laskennallisten tekniikoiden tutkimisen, joiden avulla tietokoneet voivat automaattisesti analysoida ja tulkita datan sisältämiä kuvioita, suhteita ja riippuvuuksia, mikä johtaa arvokkaiden oivallusten ja tiedon hankkimiseen.
Aiheeseen liittyvä artikkeli: Tekoäly tieteessä
Koneoppiminen tieteessä
Koneellinen oppiminen on noussut tehokkaaksi työkaluksi eri tieteenaloilla ja mullistanut tutkijoiden tavan analysoida ja tulkita monimutkaisia tietokokonaisuuksia. Tieteessä koneoppimisen tekniikoita käytetään moniin erilaisiin haasteisiin, kuten proteiinirakenteiden ennustamiseen, tähtitieteellisten kohteiden luokitteluun, ilmastomallien mallintamiseen ja mallien tunnistamiseen geneettisestä datasta. Tutkijat voivat kouluttaa koneoppimisalgoritmeja, joiden avulla he voivat paljastaa piilotettuja kuvioita, tehdä tarkkoja ennusteita ja saada syvempää ymmärrystä monimutkaisista ilmiöistä hyödyntämällä suuria tietomääriä. Koneoppiminen tieteessä ei ainoastaan paranna data-analyysin tehokkuutta ja tarkkuutta, vaan myös avaa uusia tapoja tehdä löytöjä, joiden avulla tutkijat voivat käsitellä monimutkaisia tieteellisiä kysymyksiä ja nopeuttaa edistystä omilla aloillaan.
Koneoppimisen tyypit
Eräät koneoppimisen tyypit kattavat laajan valikoiman lähestymistapoja ja tekniikoita, jotka soveltuvat erilaisiin ongelma-alueisiin ja datan ominaisuuksiin. Tutkijat ja ammattilaiset voivat valita omiin tehtäviinsä sopivimman lähestymistavan ja hyödyntää koneoppimisen voimaa oivallusten hankkimiseen ja tietoon perustuvien päätösten tekemiseen. Seuraavassa on lueteltu joitakin koneoppimisen tyyppejä:
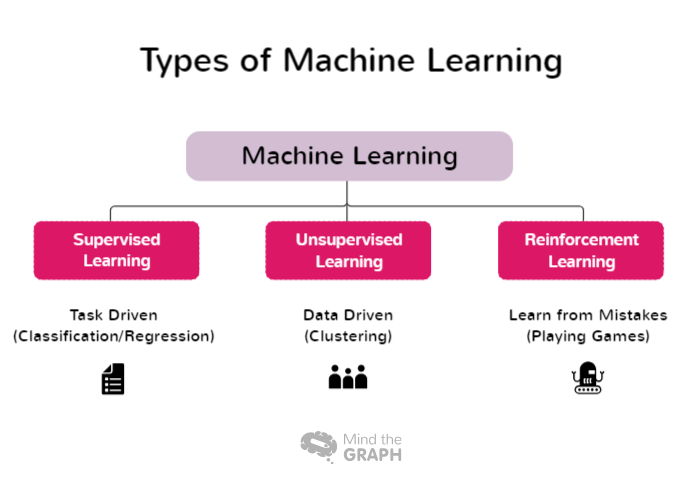
Valvottu oppiminen
Valvottu oppiminen on koneoppimisen peruslähestymistapa, jossa malli koulutetaan käyttäen merkittyjä tietokokonaisuuksia. Tässä yhteydessä merkityllä datalla tarkoitetaan syöttötietoa, joka on yhdistetty vastaaviin lähtö- tai tavoitetarroihin. Valvotun oppimisen tavoitteena on, että malli oppii malleja ja suhteita syötteen ominaisuuksien ja niitä vastaavien merkintöjen välillä, jolloin se voi tehdä tarkkoja ennusteita tai luokituksia uusista, tuntemattomista tiedoista.
Koulutusprosessin aikana malli säätää iteratiivisesti parametrejaan annettujen merkittyjen tietojen perusteella ja pyrkii minimoimaan ennustettujen tulosten ja todellisten merkintöjen välisen eron. Tämän ansiosta malli pystyy yleistämään ja tekemään tarkkoja ennusteita näkymättömästä datasta. Valvottua oppimista käytetään laajalti erilaisissa sovelluksissa, kuten kuvantunnistuksessa, puheentunnistuksessa, luonnollisen kielen käsittelyssä ja ennakoivassa analytiikassa.
Valvomaton oppiminen
Valvomaton oppiminen on koneoppimisen osa-alue, jossa keskitytään merkitsemättömien tietokokonaisuuksien analysointiin ja ryhmittelyyn ilman ennalta määriteltyjä tavoitetunnisteita. Valvomattomassa oppimisessa algoritmit on suunniteltu havaitsemaan automaattisesti kuvioita, samankaltaisuuksia ja eroja datan sisällä. Paljastamalla nämä piilossa olevat rakenteet valvomaton oppiminen antaa tutkijoille ja organisaatioille mahdollisuuden saada arvokkaita tietoja ja tehdä tietoon perustuvia päätöksiä.
Tämä lähestymistapa on erityisen hyödyllinen eksploratiivisessa data-analyysissä, jossa tavoitteena on ymmärtää datan taustalla oleva rakenne ja tunnistaa mahdolliset mallit tai suhteet. Valvomattomalla oppimisella on myös sovelluksia eri aloilla, kuten asiakassegmentoinnissa, poikkeamien havaitsemisessa, suosittelujärjestelmissä ja kuvantunnistuksessa.
Vahvistusoppiminen
Vahvistusoppiminen (Reinforcement Learning, RL) on koneoppimisen osa-alue, joka keskittyy siihen, miten älykkäät agentit voivat oppia tekemään optimaalisia päätöksiä ympäristössä maksimoidakseen kumulatiiviset palkkiot. Toisin kuin valvotussa oppimisessa, joka perustuu merkittyihin tulo/lähtö -pareihin, tai valvomattomassa oppimisessa, jossa pyritään löytämään piilotettuja kuvioita, vahvistusoppiminen toimii oppimalla vuorovaikutuksesta ympäristön kanssa. Tarkoituksena on löytää tasapaino etsinnän, jossa agentti löytää uusia strategioita, ja hyödyntämisen, jossa agentti hyödyntää nykyistä tietämystään tehdäkseen tietoon perustuvia päätöksiä, välillä.
Vahvistusoppimisessa ympäristöä kuvataan tyypillisesti seuraavasti Markovin päätösprosessi (MDP), joka mahdollistaa dynaamisen ohjelmoinnin tekniikoiden käytön. Toisin kuin klassiset dynaamisen ohjelmoinnin menetelmät, RL-algoritmit eivät vaadi MDP:n tarkkaa matemaattista mallia, ja ne on suunniteltu käsittelemään laajoja ongelmia, joissa tarkat menetelmät ovat epäkäytännöllisiä. Soveltamalla vahvistusoppimistekniikoita agentit voivat mukautua ja parantaa päätöksentekokykyään ajan mittaan, mikä tekee siitä tehokkaan lähestymistavan esimerkiksi autonomisessa navigoinnissa, robotiikassa, pelaamisessa ja resurssien hallinnassa.
Koneoppimisen algoritmit ja tekniikat
Koneoppimisalgoritmit ja -tekniikat tarjoavat monipuolisia mahdollisuuksia, ja niitä sovelletaan eri aloilla monimutkaisten ongelmien ratkaisemiseen. Kullakin algoritmilla on omat vahvuutensa ja heikkoutensa, ja niiden ominaisuuksien ymmärtäminen voi auttaa tutkijoita ja ammattilaisia valitsemaan sopivimman lähestymistavan tiettyihin tehtäviin. Hyödyntämällä näitä algoritmeja tutkijat voivat avata datasta arvokkaita oivalluksia ja tehdä tietoon perustuvia päätöksiä omilla aloillaan.
Satunnaismetsät
Random Forests on suosittu algoritmi koneoppimisessa, joka kuuluu kokonaisvaltaisen oppimisen luokkaan. Se yhdistää useita päätöspuita ennusteiden tekemiseen tai tietojen luokitteluun. Jokainen satunnaismetsän päätöspuu koulutetaan eri osajoukolla dataa, ja lopullinen ennuste määritetään yhdistämällä kaikkien yksittäisten puiden ennusteet. Satunnaismetsät tunnetaan kyvystään käsitellä monimutkaisia tietokokonaisuuksia, antaa tarkkoja ennusteita ja käsitellä puuttuvia arvoja. Niitä käytetään laajalti eri aloilla, kuten rahoituksessa, terveydenhuollossa ja kuvantunnistuksessa.
Syväoppimisen algoritmi
Syväoppiminen on koneoppimisen osa-alue, jossa keskitytään kouluttamaan keinotekoisia neuroverkkoja, joissa on useita kerroksia, jotta ne oppisivat tietojen esityksiä. Syväoppimisen algoritmit, kuten Konvolutiiviset neuroverkot (CNN) ja Toistuvat neuroverkot (RNN) ovat saavuttaneet huomattavaa menestystä esimerkiksi kuvan- ja puheentunnistuksessa, luonnollisen kielen käsittelyssä ja suosittelujärjestelmissä. Syväoppimisalgoritmit pystyvät automaattisesti oppimaan hierarkkisia piirteitä raakadatasta, minkä ansiosta ne pystyvät tallentamaan monimutkaisia kuvioita ja tekemään erittäin tarkkoja ennusteita. Syväoppimisalgoritmit vaativat kuitenkin suuria määriä merkittyä dataa ja huomattavia laskentaresursseja harjoittelua varten. Jos haluat lisätietoja syväoppimisesta, käy osoitteessa IBM:n verkkosivusto.
Gaussin prosessit
Gaussin prosessit ovat tehokas tekniikka, jota käytetään koneoppimisessa todennäköisyysjakaumiin perustuvaan mallintamiseen ja ennusteiden tekemiseen. Ne ovat erityisen käyttökelpoisia, kun käsitellään pieniä, kohinaisia tietokokonaisuuksia. Gaussin prosessit tarjoavat joustavan ja ei-parametrisen lähestymistavan, jolla voidaan mallintaa monimutkaisia muuttujien välisiä suhteita ilman vahvoja oletuksia taustalla olevasta datajakaumasta. Niitä käytetään yleisesti regressio-ongelmissa, joissa tavoitteena on estimoida jatkuva tuloste syöttöominaisuuksien perusteella. Gaussin prosesseja käytetään esimerkiksi geostatistiikassa, rahoituksessa ja optimoinnissa.
Koneoppimisen soveltaminen tieteessä
Koneoppimisen soveltaminen tieteessä avaa uusia tutkimusväyliä, joiden avulla tutkijat voivat ratkaista monimutkaisia ongelmia, löytää kuvioita ja tehdä ennusteita suurten ja erilaisten tietokokonaisuuksien perusteella. Valjastamalla koneoppimisen voiman tutkijat voivat saada syvällisempiä oivalluksia, nopeuttaa tieteellisiä löytöjä ja edistää tietämystä eri tieteenaloilla.
Lääketieteellinen kuvantaminen
Koneoppiminen on edistänyt merkittävästi lääketieteellistä kuvantamista ja mullistanut diagnostiset ja ennustetekniset valmiudet. Koneoppimisalgoritmit voivat analysoida lääketieteellisiä kuvia, kuten röntgen-, magneetti- ja tietokonetomografiakuvia, ja auttaa siten erilaisten sairauksien ja tilojen havaitsemisessa ja diagnosoinnissa. Ne voivat auttaa tunnistamaan poikkeavuuksia, segmentoimaan elimiä tai kudoksia ja ennustamaan potilaiden tuloksia. Hyödyntämällä koneoppimista lääketieteellisessä kuvantamisessa terveydenhuollon ammattilaiset voivat parantaa diagnoosiensa tarkkuutta ja tehokkuutta, mikä johtaa parempaan potilaan hoitoon ja hoidon suunnitteluun.
Aktiivinen oppiminen
Aktiivinen oppiminen on koneoppimistekniikka, jonka avulla algoritmi voi vuorovaikutteisesti kysyä ihmiseltä tai oraakkelilta merkittyjä tietoja. Tieteellisessä tutkimuksessa aktiivinen oppiminen voi olla arvokasta silloin, kun käytetään rajallisia merkittyjä tietokokonaisuuksia tai kun merkintäprosessi on aikaa vievä tai kallis. Valitsemalla älykkäästi informatiivisimmat tapaukset merkitsemistä varten aktiivisen oppimisen algoritmit voivat saavuttaa korkean tarkkuuden vähemmillä merkityillä esimerkeillä, mikä vähentää manuaalisen merkitsemisen taakkaa ja nopeuttaa tieteellisiä löytöjä.
Tieteelliset sovellukset
Koneellista oppimista sovelletaan laajalti eri tieteenaloilla. Genomiikassa koneoppimisalgoritmit voivat analysoida DNA- ja RNA-sekvenssejä geneettisten variaatioiden tunnistamiseksi, proteiinien rakenteiden ennustamiseksi ja geenien toimintojen ymmärtämiseksi. Materiaalitieteessä koneoppimista käytetään uusien, halutuilla ominaisuuksilla varustettujen materiaalien suunnitteluun, materiaalien löytämisen nopeuttamiseen ja valmistusprosessien optimointiin. Koneoppimistekniikoita käytetään myös ympäristötieteissä saastetasojen ennustamiseen ja seurantaan, sääennusteisiin ja ilmastotietojen analysointiin. Lisäksi se on ratkaisevassa asemassa fysiikassa, kemiassa, tähtitieteessä ja monilla muilla tieteenaloilla mahdollistamalla tietoon perustuvan mallintamisen, simuloinnin ja analysoinnin.
Koneoppimisen hyödyt tieteessä
Koneoppimisen hyödyt tieteessä ovat lukuisat ja vaikuttavat. Seuraavassa on joitakin keskeisiä etuja:
Tehostettu ennakoiva mallinnus: Koneoppimisalgoritmeilla voidaan analysoida suuria ja monimutkaisia tietokokonaisuuksia ja tunnistaa malleja, trendejä ja suhteita, joita ei ehkä ole helppo tunnistaa perinteisillä tilastollisilla menetelmillä. Näin tutkijat voivat kehittää tarkkoja ennustemalleja erilaisille tieteellisille ilmiöille ja tuloksille, mikä johtaa tarkempiin ennusteisiin ja parempaan päätöksentekoon.
Tehokkuuden ja automaation lisääminen: Koneoppimistekniikat automatisoivat toistuvia ja aikaa vieviä tehtäviä, jolloin tutkijat voivat keskittyä tutkimuksen monimutkaisempiin ja luovempiin osa-alueisiin. Koneoppimisalgoritmit voivat käsitellä valtavia tietomääriä, suorittaa nopean analyysin ja tuottaa oivalluksia ja johtopäätöksiä tehokkaasti. Tämä lisää tuottavuutta ja nopeuttaa tieteellistä keksintötyötä.
Parempi tietojen analysointi ja tulkinta: Koneoppimisalgoritmit ovat erinomaisia tietojen analysoinnissa, ja niiden avulla tutkijat voivat poimia arvokkaita oivalluksia suurista ja heterogeenisistä tietokokonaisuuksista. Ne voivat tunnistaa piilotettuja kuvioita, korrelaatioita ja poikkeavuuksia, jotka eivät välttämättä ole välittömästi ihmisten havaittavissa. Koneoppimistekniikat auttavat myös tietojen tulkinnassa tarjoamalla selityksiä, visualisointeja ja yhteenvetoja, jotka helpottavat monimutkaisten tieteellisten ilmiöiden syvempää ymmärtämistä.
Helpotettu päätöksenteon tuki: Koneoppimismallit voivat toimia tutkijoiden päätöksenteon tukena. Analysoimalla historiallista dataa ja reaaliaikaista tietoa koneoppimisalgoritmit voivat auttaa päätöksentekoprosesseissa, kuten lupaavimpien tutkimusvaihtoehtojen valinnassa, kokeellisten parametrien optimoinnissa tai tieteellisten hankkeiden mahdollisten riskien tai haasteiden tunnistamisessa. Tämä auttaa tutkijoita tekemään tietoon perustuvia päätöksiä ja lisää mahdollisuuksia saavuttaa onnistuneita tuloksia.
Tieteellisten löytöjen nopeuttaminen: Koneoppiminen nopeuttaa tieteellistä keksintöä, sillä sen avulla tutkijat voivat tutkia valtavia tietomääriä, luoda hypoteeseja ja validoida teorioita tehokkaammin. Hyödyntämällä koneoppimisen algoritmeja tutkijat voivat luoda uusia yhteyksiä, löytää uusia oivalluksia ja tunnistaa tutkimussuuntia, jotka olisivat muuten saattaneet jäädä huomaamatta. Tämä johtaa läpimurtoihin eri tieteenaloilla ja edistää innovointia.
Kommunikoi tieteestä visuaalisesti parhaan ja ilmaisen Infographic Makerin voimin.
Mind the Graph on arvokas resurssi, joka auttaa tutkijoita viestimään tutkimuksestaan tehokkaasti visuaalisesti. Parhaan ja ilmaisen infografiikkasovelluksen avulla tämä alusta antaa tutkijoille mahdollisuuden luoda mukaansatempaavia ja informatiivisia infografiikoita, jotka kuvaavat visuaalisesti monimutkaisia tieteellisiä käsitteitä ja tietoja. Olipa kyse sitten tutkimustulosten esittelystä, tieteellisten prosessien selittämisestä tai datan trendien visualisoinnista, Mind the Graph-alusta tarjoaa tutkijoille välineet, joiden avulla he voivat viestiä tieteestään visuaalisesti selkeästi ja vakuuttavasti. Rekisteröidy ilmaiseksi ja aloita suunnittelun luominen nyt.





Tilaa uutiskirjeemme
Eksklusiivista korkealaatuista sisältöä tehokkaasta visuaalisesta
tiedeviestintä.