
A análise de regressão é uma abordagem para identificar e analisar a conexão entre uma ou mais variáveis independentes e uma variável dependente. Esse método é amplamente utilizado em diversas disciplinas, incluindo saúde, ciências sociais, engenharia, economia e negócios. Você pode usar a análise de regressão para investigar as relações fundamentais nos dados e desenvolver modelos preditivos que o ajudarão a tomar decisões informadas.
Este artigo fornecerá uma visão geral abrangente da análise de regressão, incluindo como ela funciona, um exemplo fácil de entender e explicará como ela difere da análise de correlação.
O que é análise de regressão?
A análise de regressão é um método estatístico para identificar e quantificar a conexão entre uma variável dependente e uma ou mais variáveis independentes. Em poucas palavras, ela ajuda a compreender como as mudanças em uma ou mais variáveis independentes estão relacionadas às mudanças na variável dependente.
Para obter um entendimento completo da análise de regressão, você deve primeiro compreender os seguintes termos:
- Variável dependente: Essa é a variável que você está interessado em analisar ou prever. É a variável de resultado que você está tentando entender e explicar.
- Variáveis independentes: Essas são as variáveis que você acredita terem efeito sobre a variável dependente. Elas são frequentemente chamadas de variáveis preditoras, pois são usadas para prever ou explicar mudanças na variável dependente.
A análise de regressão pode ser usada em uma série de circunstâncias, incluindo a previsão de valores futuros da variável dependente, a compreensão do efeito de variáveis independentes sobre a variável dependente e a descoberta de valores discrepantes ou ocorrências incomuns na coleta de dados.
A análise de regressão pode ser classificada em vários tipos, incluindo regressão linear simples, regressão logística, regressão polinomial e regressão múltipla. O modelo de regressão adequado é determinado pela natureza dos dados e pelo tema da investigação em questão.
Como funciona a análise de regressão?
O objetivo da análise de regressão é identificar a linha ou curva de melhor ajuste que reflete a conexão entre as variáveis independentes e a variável dependente. Essa linha ou curva de melhor ajuste é gerada usando métodos estatísticos que reduzem as disparidades entre os valores esperados e reais na coleta de dados.
Aqui estão as fórmulas para os dois tipos mais comuns de análise de regressão:
Regressão linear simples
Na Regressão Linear Simples, você usa uma linha de melhor ajuste para mostrar a relação entre duas variáveis: a variável independente (x) e a variável dependente (y).
A linha de melhor ajuste pode ser representada pela equação: y = a + bx.
Aqui, a é a interceptação e b é a inclinação da linha. Para calcular a inclinação, você usa a fórmula: b = (nΣ(xy) - ΣxΣy) / (nΣ(x2) - (Σx)2), em que n é o número de observações, Σxy é a soma do produto de x e y, Σx e Σy são as somas de x e y, respectivamente, e Σ(x2) é a soma dos quadrados de x.
Para calcular o intercepto, use a fórmula: a = (Σy - bΣx) / n.
Regressão múltipla
Regressão linear múltipla:
A fórmula para a equação do modelo de regressão linear múltipla é:
y = b0 + b1x1 + b2x2 + ... + bnxn
em que y é a variável dependente, x1, x2, ..., xn são as variáveis independentes, e b0, b1, b2..., bn são os coeficientes das variáveis independentes.
A fórmula para estimar os coeficientes usando mínimos quadrados comuns é:
β = (X'X)(-1)X'y
em que β é um vetor de coluna de coeficientes, X é a matriz de projeto de variáveis independentes, X' é a transposição de X e y é o vetor de observações da variável dependente.
Exemplo de análise de regressão
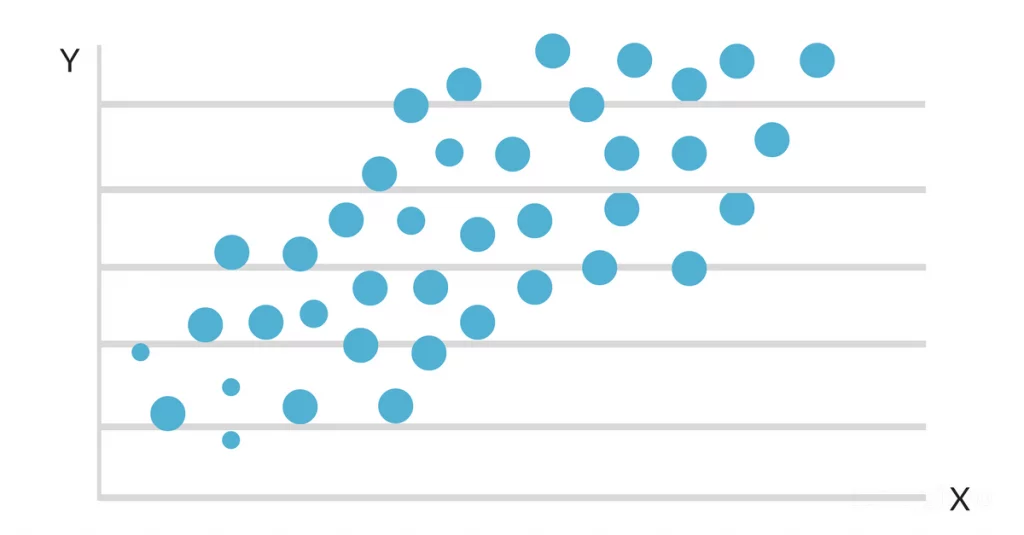
Suponha que você queira analisar a relação entre a média de notas (GPA) de um indivíduo e o número de horas que ele estuda por semana. Você coleta informações de um conjunto de alunos, incluindo o número de horas de estudo e a média de notas.
Em seguida, use a análise de regressão para ver se há uma conexão linear entre as duas variáveis e, em caso afirmativo, você pode criar um modelo que preveja o GPA de um aluno com base no número de horas que ele estuda por semana.

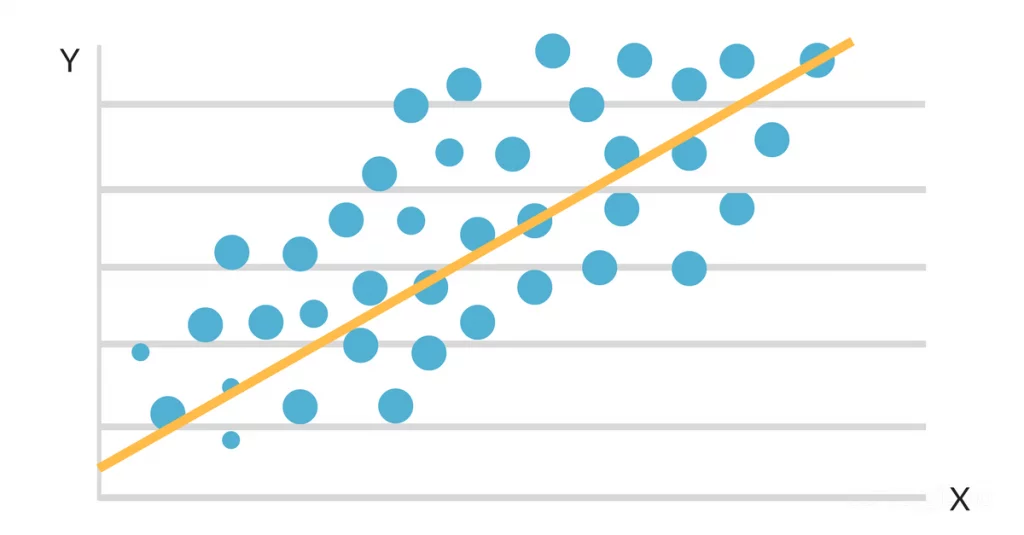
Quando os dados são plotados em um mapa de dispersão, parece que há uma conexão linear favorável entre as horas de estudo e o GPA. A inclinação e a interceptação da linha de melhor ajuste são então estimadas usando um modelo de regressão linear simples. A solução final poderia ter a seguinte aparência:
GPA = 2,0 + 0,3 (horas estudadas por semana)
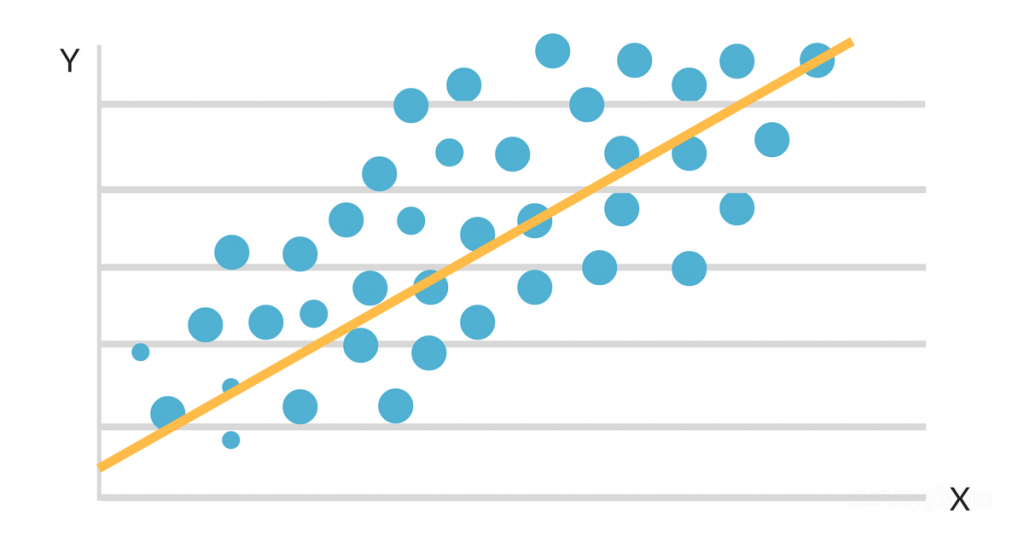
Essa equação afirma que, para cada hora extra de estudo por semana, o GPA do aluno aumentará em 0,3 ponto, mantendo-se tudo o mais equivalente. Esse algoritmo pode ser usado para prever o GPA de um aluno com base em quantas horas ele estuda por semana, bem como para identificar quais alunos correm o risco de ter um desempenho inferior com base em suas rotinas de estudo.
Usando os dados do exemplo, os valores para b e a são os seguintes:
n = 10 (o número de observações)
Σx = 30 (a soma das horas de estudo)
Σy = 25 (a soma dos GPAs)
Σxy = 149 (a soma do produto das horas de estudo e dos GPAs)
Σ(x)2 = 102 (a soma dos quadrados das horas de estudo)
Usando esses valores, calcule b como:
b = (nΣ(xy) - ΣxΣy) / (nΣ(x2) - (Σx)2)
= (10 * 149 – 30 * 25) / (10 * 102 – 302)
= 0.3
E calcular a como:
a = (Σy - bΣx) / n
= (25 – 0.3 * 30) / 10
= 2.0
Portanto, a equação da linha de melhor ajuste é:
GPA = 2,0 + 0,3 (horas estudadas por semana)
Qual é a diferença entre correlação e regressão?
Tanto a correlação quanto a regressão são métodos estatísticos para examinar a conexão entre duas variáveis. Eles têm finalidades diferentes e fornecem tipos diferentes de informações.
A correlação é uma medida da força e do curso de uma conexão entre duas variáveis. Ela varia de -1 a +1, sendo que -1 representa uma correlação negativa perfeita, 0 representa nenhuma correlação e +1 representa uma correlação positiva perfeita. A correlação indica o grau em que duas variáveis estão conectadas, mas não indica causa ou previsibilidade.
A regressão, por outro lado, é um método para modelar a conexão entre duas variáveis, geralmente para prever ou explicar uma variável com base na outra. A análise de regressão pode fornecer estimativas do tamanho e da direção da relação, bem como testes de significância estatística, intervalos de confiança e previsões de resultados futuros.
Suas criações, prontas em minutos
Mind the Graph é uma plataforma on-line que oferece uma ampla biblioteca de ilustrações científicas e designs de infográficos que podem ser simplesmente modificados para atender às suas necessidades específicas. Crie gráficos, pôsteres e resumos gráficos com aparência profissional em minutos, usando uma interface de arrastar e soltar e uma ampla variedade de ferramentas e recursos.



{kind=link}
{kind=link}

Assine nossa newsletter
Conteúdo exclusivo de alta qualidade sobre visual eficaz
comunicação na ciência.