
I dagens forskningslandskap, som er i rask utvikling, har integrering av koding og programmering blitt en kraftfull kraft som har revolusjonert måten vi tilnærmer oss vitenskapelige undersøkelser på. Med den eksponentielle veksten i datamengden og den økende kompleksiteten i forskningsspørsmålene har koding blitt et viktig verktøy for forskere på tvers av en lang rekke fagområder.
Synergien mellom koding og forskning strekker seg utover dataanalyse. Gjennom simulering og modellering kan forskere bruke kode til å lage virtuelle eksperimenter og teste hypoteser in silico. Ved å etterligne komplekse systemer og scenarier kan forskere få verdifull innsikt i biologiske, fysiske og sosiale fenomener som kan være vanskelige eller umulige å observere direkte. Slike simuleringer gjør forskerne i stand til å forutsi, optimalisere prosesser og designe eksperimenter med større presisjon og effektivitet.
Denne artikkelen utforsker den sentrale rollen koding spiller i forskning, og fremhever kodingens transformative innvirkning på vitenskapelig praksis og resultater.

Introduksjon til koding i forskning
Historien om koding og programmering som en del av forskningsmetodikken er rik og fascinerende, og er preget av viktige milepæler som har påvirket hvordan forskersamfunnet tilnærmer seg dataanalyse, automatisering og oppdagelser.
Koding i forskning går tilbake til midten av 1900-tallet, da fremskritt innen datateknologi skapte nye muligheter for behandling og analyse av data. I begynnelsen handlet koding i stor grad om å utvikle programmeringsspråk og algoritmer på lavt nivå for å løse matematiske problemer. Programmeringsspråk som Fortran og COBOL ble utviklet i denne perioden, og la grunnlaget for videre utvikling av forskningskoding.
Et vendepunkt ble nådd på 1960- og 1970-tallet da forskerne innså hvor effektivt koding kunne være for å håndtere store datamengder. Fremveksten av statistiske dataspråk som SAS og SPSS i denne perioden ga forskerne muligheten til å analysere datasett raskere og utføre avanserte statistiske beregninger. Forskere innen fagområder som samfunnsvitenskap, økonomi og epidemiologi er nå avhengige av å kunne kode for å finne mønstre i dataene, teste hypoteser og utlede verdifull innsikt.
I løpet av 1980- og 1990-årene ble det stadig flere personlige datamaskiner, og kodingsverktøyene ble mer tilgjengelige. Integrerte utviklingsmiljøer (IDE-er) og grafiske brukergrensesnitt (GUI-er) har senket inngangsbarrierene og bidratt til at koding har blitt en vanlig forskningsteknikk ved å gjøre den mer tilgjengelig for et større spekter av forskere. Utviklingen av skriptspråk som Python og R ga også nye muligheter for dataanalyse, visualisering og automatisering, noe som ytterligere befestet kodingens rolle i forskningen.
Den raske teknologiske utviklingen ved inngangen til det 21. århundret førte til stordata-æraen og innledet en ny æra for koding i akademisk forskning. For å få nyttig innsikt måtte forskerne håndtere enorme mengder kompliserte og heterogene data, noe som krevde avanserte kodingsmetoder.
Som et resultat av dette oppstod datavitenskapen, som kombinerer kodekompetanse med statistisk analyse, maskinlæring og datavisualisering. Med introduksjonen av rammeverk og biblioteker med åpen kildekode, som TensorFlow, PyTorch og sci-kit-learn, har forskere nå tilgang til kraftige verktøy for å løse utfordrende forskningsproblemer og maksimere potensialet i maskinlæringsalgoritmer.
I dag er koding en viktig del av forskningen på en rekke områder, fra naturvitenskap til samfunnsvitenskap og mer til. Det har utviklet seg til et universelt språk som gjør det mulig for forskere å undersøke og analysere data, modellere og automatisere prosesser og simulere komplekse systemer. Koding brukes i stadig større grad i kombinasjon med banebrytende teknologier som kunstig intelligens, cloud computing og stordataanalyse for å flytte grensene for forskning og hjelpe forskere med å løse vanskelige problemer og oppdage ny innsikt.
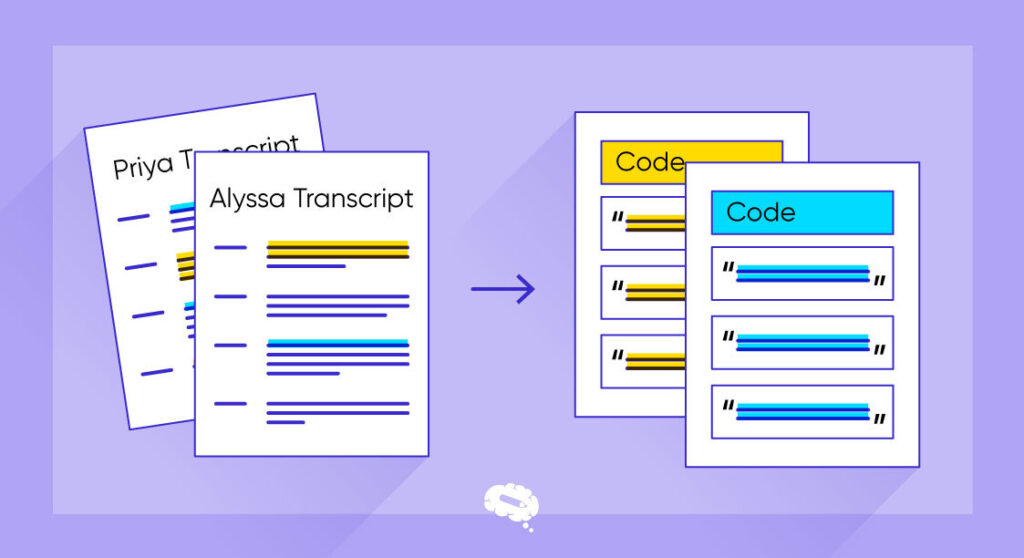
Typer av koding i forskning
Det finnes mange ulike typer koding og anvendelser av koding i forskning, og forskere bruker dem til å forbedre studiene sine. Her er noen av de viktigste kodingstypene som brukes i forskning:
Dataanalyse Koding
Å skrive kode for å behandle, rense og analysere store og kompliserte datasett kalles dataanalysekoding. Forskere kan utføre statistiske studier, visualisere data og identifisere mønstre eller trender ved hjelp av programmeringsspråk som Python, R, MATLAB eller SQL for å få verdifull innsikt.
Automatiseringskoding
Automatisering av repetitive oppgaver og arbeidsflyter i forskningsprosesser er temaet for automatiseringskoding. Forskere kan gjøre datainnsamling, dataforberedelse, eksperimentelle prosedyrer eller rapportgenerering raskere ved å skrive skript eller programmer. Dette sparer tid og sikrer konsistens mellom eksperimenter eller analyser.
Koding av simulering og modellering
For å utvikle databaserte simuleringer eller modeller som gjenskaper virkelige systemer eller fenomener, brukes simulering og modelleringskoding. Forskere kan teste hypoteser, undersøke oppførselen til komplekse systemer og undersøke scenarier som kan være utfordrende eller dyre å gjenskape i den virkelige verden ved hjelp av koding av simuleringer.
Maskinlæring og kunstig intelligens (AI)
Maskinlæring og AI-koding innebærer å lære algoritmer og modeller å analysere informasjon, identifisere trender, forutsi resultater eller utføre bestemte oppgaver. På områder som bildeanalyse, naturlig språkbehandling og prediktiv analyse bruker forskere kodingsteknikker til å forhåndsbehandle data, konstruere og finjustere modeller, evaluere ytelsen og bruke disse modellene til å løse forskningsutfordringer.
Webutvikling og datavisualisering
Koding av nettutvikling brukes i forskning for å produsere interaktive nettbaserte verktøy, dataoversikter eller nettbaserte spørreundersøkelser for å samle inn og vise data. Forskere kan også bruke koding til å lage plott, diagrammer eller interaktive visualiseringer for å forklare forskningsresultatene.
Utvikling av programvare og verktøy
Som et supplement til forskningen kan noen forskere lage spesifikke programvareverktøy eller applikasjoner. For å muliggjøre datahåndtering, analyse eller eksperimentell kontroll innebærer denne typen koding å bygge, utvikle og vedlikeholde programvareløsninger som er tilpasset bestemte forskningsmål.
Felles koding
Å jobbe med kodeprosjekter sammen med fagfeller eller kolleger er kjent som samarbeidskoding. For å øke åpenheten, reproduserbarheten og den kollektive vitenskapelige kunnskapen kan forskere delta i kodegjennomganger, bidra til prosjekter med åpen kildekode og dele kode og metoder.
Metoder for koding av kvalitative data
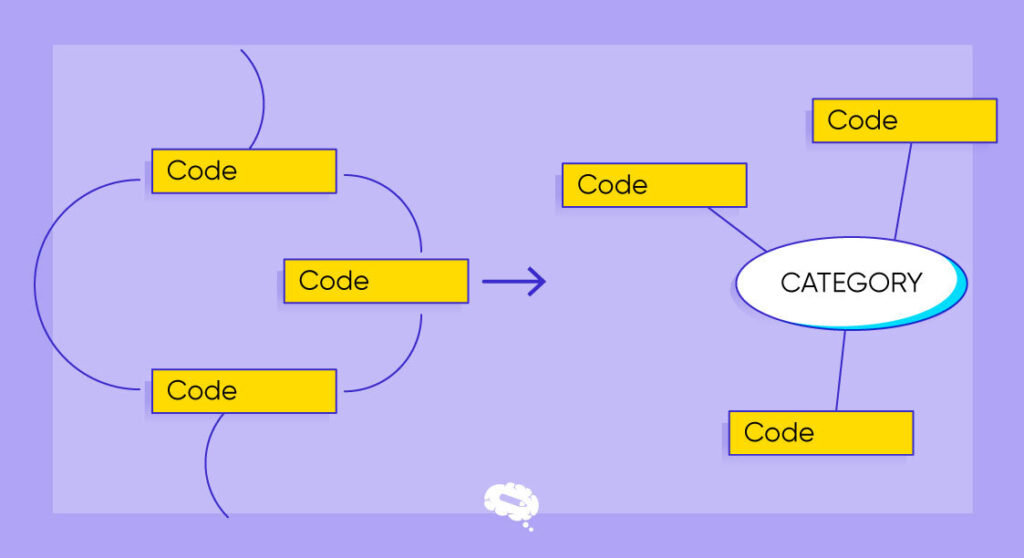
Forskere bruker en rekke ulike teknikker når de skal kode kvalitative data for å vurdere og forstå dataene de har samlet inn. Nedenfor følger noen vanlige metoder for koding av kvalitative data:
- Tematisk koding: Forskere identifiserer tilbakevendende temaer eller mønstre i dataene ved å tildele deskriptive koder til tekstsegmenter som representerer spesifikke temaer, noe som gjør det lettere å organisere og analysere kvalitativ informasjon.
- Deskriptiv koding: Det gjør det mulig å skape en første oversikt og identifisere ulike aspekter eller dimensjoner ved fenomenet som undersøkes. Koder tildeles datasegmenter basert på informasjonens innhold eller kvaliteter.
- In vivo-koding: Den bevarer autentisitet og legger vekt på levde erfaringer ved å bruke deltakernes egne ord eller setninger som koder for å destillere deres erfaringer eller perspektiver.
- Konseptuell koding: Det gjør det mulig å bruke eksisterende teorier og etablere forbindelser mellom kvalitative data og teoretiske konstruksjoner. Dataene kodes basert på teoretiske begreper eller rammeverk som er relevante for forskningen.
- Sammenlignende koding: Systematiske sammenligninger mellom ulike situasjoner eller individer gjennomføres for å avdekke likheter og forskjeller i dataene. Disse sammenligningene representeres deretter ved hjelp av koder. Denne tilnærmingen forbedrer forståelsen av variasjoner og nyanser i datasettet.
- Mønsterkoding: I de kvalitative dataene finner man mønstre eller sekvenser av hendelser som går igjen, og tilordner dem koder for å indikere mønstrene. Ved å avdekke tidsmessige eller kausale sammenhenger kaster mønsterkoding lys over underliggende dynamikk eller prosesser.
- Koding av relasjoner: I kvalitative data analyseres sammenhenger, avhengigheter eller koblinger mellom ulike begreper eller temaer. For å forstå samspillet og koblingene mellom mange ulike dataelementer utvikler forskerne koder som beskriver disse sammenhengene.
Fordeler med koding av kvalitativ forskning
Når det gjelder databehandling, har koding av kvalitativ forskning en rekke fordeler. For det første gir koding den analytiske prosessen struktur og orden, slik at forskerne kan kategorisere og organisere kvalitative data på en logisk måte. Ved å redusere datamengden blir det lettere å identifisere viktige temaer og mønstre.
Koding gjør det i tillegg mulig å utforske dataene grundig og avdekke kontekst og skjulte betydninger. Ved å tilby en dokumentert og repeterbar prosess forbedrer den også forskningens transparens og stringens.
Koding gjør sammenligning og syntese av data enklere, bidrar til å skape teorier og gir dypere innsikt for tolkning. Det gir tilpasningsdyktighet, fleksibilitet og mulighet for gruppeanalyse, noe som fremmer konsensus og styrker funnenes pålitelighet.
Koding gir en bedre forståelse av forskningstemaet ved å kombinere kvalitative data med andre forskningsmetoder.
Generelt sett forbedrer koding av kvalitativ forskning kvaliteten, dybden og tolkningskapasiteten i dataanalysen, noe som gjør det mulig for forskere å få innsiktsfull kunnskap og utvikle sine forskningsfelt.
Tips for koding av kvalitative data
- Bli kjent med dataene: Før du starter kodingsprosessen, må du sette deg grundig inn i innholdet og konteksten til de kvalitative dataene ved å lese og fordype deg i dem.
- Bruk et kodesystem: Enten du bruker deskriptive koder, tematiske koder eller en kombinasjon av metoder, må du lage et tydelig og konsekvent kodesystem. Beskriv kodesystemet skriftlig for å sikre ensartethet i hele undersøkelsen.
- Kode induktivt og deduktivt: Vurder å bruke både induktiv og deduktiv koding for å fange opp et bredt spekter av ideer. Induktiv koding innebærer å identifisere temaer som dukker opp fra dataene, mens deduktiv koding innebærer å bruke teorier eller begreper som allerede finnes.
- Bruk åpen koding til å begynne med: Begynn med å tilordne koder til ulike datasegmenter uten å bruke forhåndsbestemte kategorier. Denne åpne kodingsstrategien gjør det mulig å utforske og oppdage tidlige mønstre og temaer.
- Gjennomgå og forbedre kodene: Etter hvert som du går gjennom analysen, bør du jevnlig undersøke og justere kodene. Klargjør definisjoner, slå sammen lignende koder og sørg for at kodene gjenspeiler innholdet de er knyttet til.
- Opprett et revisjonsspor: Registrer kodingsbeslutninger, begrunnelser og tankeprosesser i detalj. Dette fungerer som en referanse for kommende analyser og diskusjoner, og bidrar til å sikre transparens og reproduserbarhet.
Etiske hensyn ved koding
Når man koder kvalitative data, må etikken komme først. Ved å prioritere informert samtykke kan forskere sikre at deltakerne har gitt sitt samtykke til bruk av data, inkludert koding og analyse. For å beskytte deltakernes navn og personlige opplysninger under kodingsprosessen er anonymitet og konfidensialitet avgjørende.
For å sikre upartiskhet og rettferdighet må forskerne reflektere over personlige fordommer og hvordan de påvirker kodingsbeslutningene. Det er viktig å respektere deltakernes meninger og erfaringer og avstå fra å utnytte eller gi en feilaktig fremstilling av dem.
Evnen til å gjenkjenne og formidle ulike synspunkter med riktig kulturell bevissthet er uunnværlig, i tillegg til å behandle deltakerne med respekt og overholde inngåtte avtaler.
Ved å ta disse etiske hensynene ivaretar forskerne integriteten, beskytter deltakernes rettigheter og bidrar til en ansvarlig kvalitativ forskningspraksis.
Vanlige feil som bør unngås ved koding i forskningen
Når du koder i forskning, er det viktig å være oppmerksom på vanlige feil som kan påvirke kvaliteten og nøyaktigheten av analysen din. Her er noen feil du bør unngå:
- Mangel på presise kodeinstruksjoner: For å bevare konsistensen må du sørge for at det finnes eksplisitte kodingsinstruksjoner.
- Over- eller underkoding: Finn en balanse mellom å samle inn viktige detaljer og å unngå altfor grundige analyser.
- Ignorering eller avvisning av avvikende tilfeller: Anerkjenn og kod ekstremverdier for å få omfattende innsikt.
- Manglende konsistens: Bruk kodingsreglene konsekvent og gjennomgå kodene med tanke på pålitelighet.
- Manglende reliabilitet mellom koderne: Etabler konsensus blant teammedlemmene for å løse uoverensstemmelser.
- Manglende dokumentasjon av kodingsbeslutninger: Oppretthold et detaljert revisjonsspor for åpenhet og fremtidig referanse.
- Fordommer og antakelser: Vær oppmerksom på fordommer og etterstreb objektivitet i kodingen.
- Utilstrekkelig opplæring eller kjennskap til data: Invester tid i å forstå dataene, og søk veiledning ved behov.
- Mangel på utforskning av data: Analyser dataene grundig for å fange opp deres rikdom og dybde.
- Manglende gjennomgang og validering av koder: Gjennomgå kodeverket regelmessig og be om innspill for å forbedre det.
Frigjør kraften i infografikk med Mind the Graph
Ved å gi akademikere muligheten til å produsere engasjerende og iøynefallende infografikk revolusjonerer Mind the Graph vitenskapelig kommunikasjon. Plattformen gjør det mulig for forskere å overvinne konvensjonelle kommunikasjonsbarrierer og engasjere et bredere publikum ved å forklare data, strømlinjeforme kompliserte konsepter, forbedre presentasjoner, oppmuntre til samarbeid og tillate tilpasning. Ta i bruk kraften i infografikk med Mind the Graph og åpne nye veier for effektiv forskningskommunikasjon.








Abonner på nyhetsbrevet vårt
Eksklusivt innhold av høy kvalitet om effektiv visuell
kommunikasjon innen vitenskap.