
L'analyse de régression est une approche permettant d'identifier et d'analyser le lien entre une ou plusieurs variables indépendantes et une variable dépendante. Cette méthode est largement utilisée dans diverses disciplines, notamment les soins de santé, les sciences sociales, l'ingénierie, l'économie et les affaires. Vous pouvez utiliser l'analyse de régression pour étudier les relations fondamentales dans les données et développer des modèles prédictifs qui vous aideront à prendre des décisions éclairées.
Cet article présente une vue d'ensemble de l'analyse de régression, y compris son fonctionnement, un exemple facile à comprendre et explique en quoi elle diffère de l'analyse de corrélation.
Qu'est-ce que l'analyse de régression ?
L'analyse de régression est une méthode statistique permettant d'identifier et de quantifier le lien entre une variable dépendante et une ou plusieurs variables indépendantes. En bref, elle vous aide à comprendre comment les changements d'une ou plusieurs variables indépendantes sont liés aux changements de la variable dépendante.
Pour bien comprendre l'analyse de régression, il faut d'abord comprendre les termes suivants :
- Variable dépendante : Il s'agit de la variable que vous souhaitez analyser ou prédire. C'est la variable de résultat que vous essayez de comprendre et d'expliquer.
- Variables indépendantes : Il s'agit des variables qui, selon vous, ont un effet sur la variable dépendante. Elles sont souvent appelées variables prédictives, car elles sont utilisées pour prédire ou expliquer les changements de la variable dépendante.
L'analyse de régression peut être utilisée dans toute une série de circonstances, notamment pour prédire les valeurs futures de la variable dépendante, comprendre l'effet des variables indépendantes sur la variable dépendante et trouver des valeurs aberrantes ou des occurrences inhabituelles dans la collecte de données.
L'analyse de régression peut être classée en plusieurs types, notamment la régression linéaire simple, la régression logistique, la régression polynomiale et la régression multiple. Le modèle de régression approprié est déterminé par la nature des données et l'objet de l'enquête.
Comment fonctionne l'analyse de régression ?
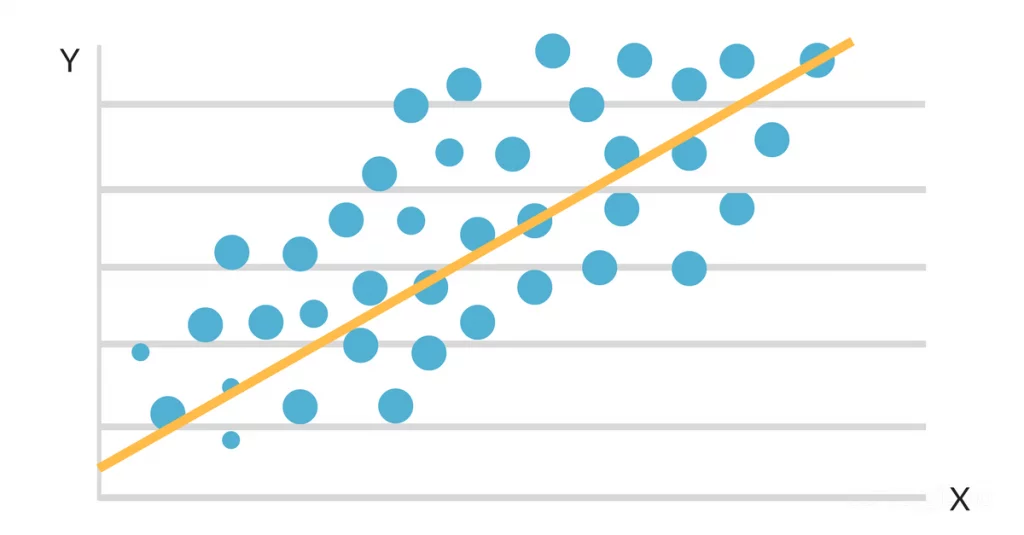
L'objectif de l'analyse de régression est d'identifier la ligne ou la courbe la mieux ajustée qui reflète le lien entre les variables indépendantes et la variable dépendante. Cette ligne ou courbe de meilleur ajustement est générée à l'aide de méthodes statistiques qui réduisent les disparités entre les valeurs attendues et les valeurs réelles dans la collecte de données.
Voici les formules des deux types d'analyse de régression les plus courants :
Régression linéaire simple
Dans la régression linéaire simple, vous utilisez une droite de meilleur ajustement pour montrer la relation entre deux variables : la variable indépendante (x) et la variable dépendante (y).
La droite de meilleur ajustement peut être représentée par l'équation : y = a + bx.
Ici, a est l'ordonnée à l'origine, b est la pente de la droite. Pour calculer la pente, on utilise la formule : b = (nΣ(xy) - ΣxΣy) / (nΣ(x2) - (Σx)2), où n est le nombre d'observations, Σxy est la somme du produit de x et y, Σx et Σy sont les sommes de x et y respectivement, et Σ(x2) est la somme des carrés de x.
Pour calculer l'ordonnée à l'origine, on utilise la formule suivante : a = (Σy - bΣx) / n.
Régression multiple
Régression linéaire multiple :
La formule de l'équation du modèle de régression linéaire multiple est la suivante :
y = b0 + b1x1 + b2x2 + ... + bnxn
où y est la variable dépendante, x1, x2, ..., xn sont les variables indépendantes, et b0, b1, b2..., bn sont les coefficients des variables indépendantes.
La formule d'estimation des coefficients par la méthode des moindres carrés ordinaires est la suivante :
β = (X'X)(-1)X'y
où β est un vecteur colonne de coefficients, X est la matrice de conception des variables indépendantes, X' est la transposée de X, et y est le vecteur d'observations de la variable dépendante.
Exemple d'analyse de régression
Supposons que vous souhaitiez étudier le lien entre la moyenne générale d'un individu et le nombre d'heures d'étude par semaine. Vous recueillez des informations auprès d'un ensemble d'étudiants, y compris leur nombre d'heures d'étude et leur moyenne générale.
Ensuite, utilisez l'analyse de régression pour voir s'il existe un lien linéaire entre les deux variables et, si c'est le cas, vous pouvez construire un modèle qui prédit la moyenne générale d'un étudiant en fonction du nombre d'heures qu'il consacre à ses études par semaine.

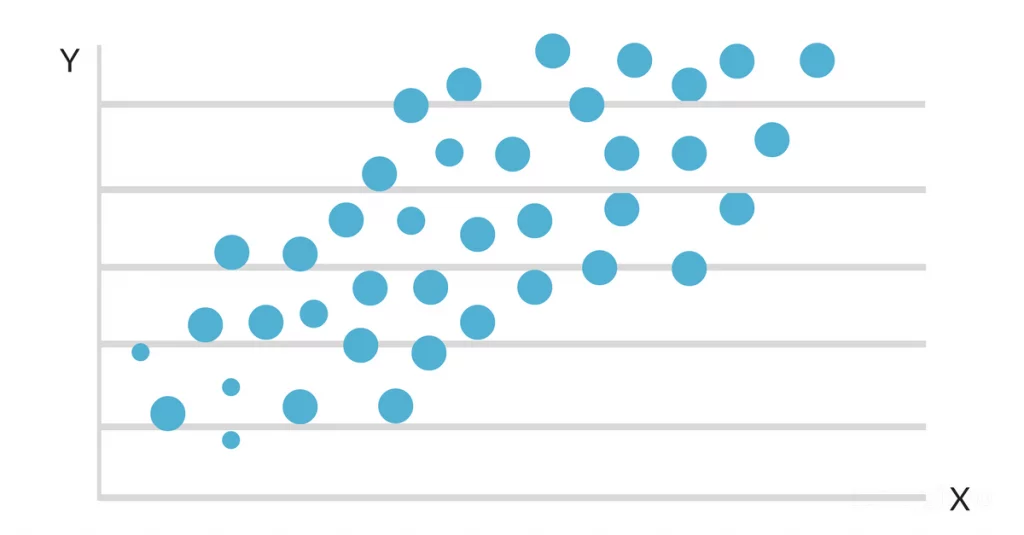
Lorsque les données sont reportées sur un diagramme de dispersion, il apparaît qu'il existe une relation linéaire favorable entre les heures d'étude et la moyenne générale. La pente et l'ordonnée à l'origine de la ligne de meilleur ajustement sont alors estimées à l'aide d'un modèle de régression linéaire simple. La solution finale pourrait ressembler à ceci :
GPA = 2,0 + 0,3 (heures d'études par semaine)
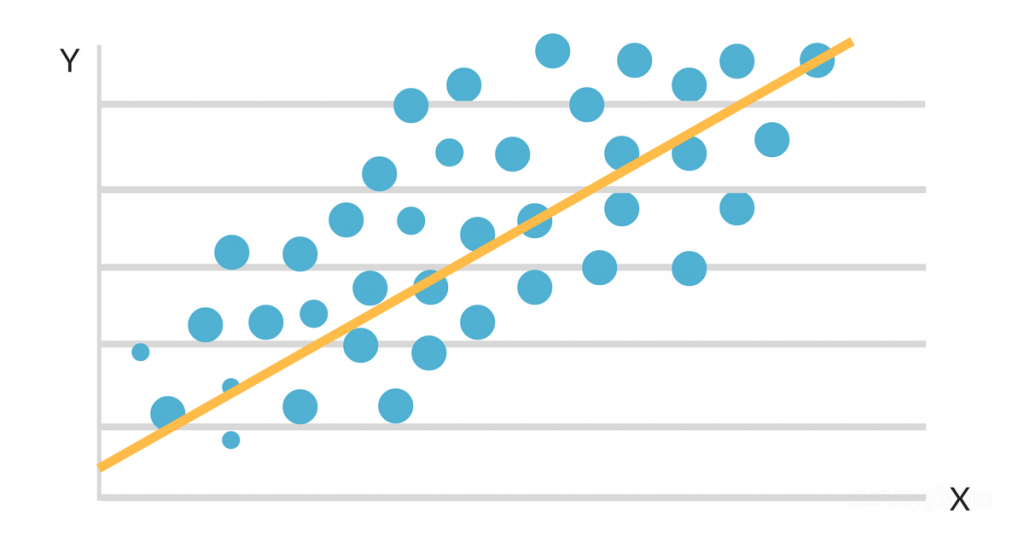
Cette équation indique que pour chaque heure d'étude supplémentaire par semaine, la moyenne générale d'un étudiant augmentera de 0,3 point, toutes choses étant égales par ailleurs. Cet algorithme peut être utilisé pour prévoir la moyenne générale d'un étudiant en fonction du nombre d'heures d'étude par semaine, ainsi que pour identifier les étudiants qui risquent d'obtenir de mauvais résultats en fonction de leurs habitudes d'étude.
En utilisant les données de l'exemple, les valeurs de b et a sont les suivants :
n = 10 (le nombre d'observations)
Σx = 30 (la somme des heures d'étude)
Σy = 25 (la somme des moyennes générales)
Σxy = 149 (la somme du produit des heures d'études et des GPA)
Σ(x)2 = 102 (somme des carrés des heures d'études)
En utilisant ces valeurs, calculez b comme :
b = (nΣ(xy) - ΣxΣy) / (nΣ(x2) - (Σx)2)
= (10 * 149 – 30 * 25) / (10 * 102 – 302)
= 0.3
Et calculer a comme :
a = (Σy - bΣx) / n
= (25 – 0.3 * 30) / 10
= 2.0
Par conséquent, l'équation de la ligne de meilleur ajustement est :
GPA = 2,0 + 0,3 (heures d'études par semaine)
Quelle est la différence entre corrélation et régression ?
La corrélation et la régression sont toutes deux des méthodes statistiques permettant d'examiner le lien entre deux variables. Elles ont des objectifs différents et fournissent des types d'informations différents.
La corrélation est une mesure de la force et de l'évolution du lien entre deux variables. Elle va de -1 à +1, -1 représentant une corrélation négative parfaite, 0 représentant l'absence de corrélation et +1 représentant une corrélation positive parfaite. La corrélation indique le degré de connexion entre deux variables, mais n'indique pas la cause ou la prévisibilité.
La régression, quant à elle, est une méthode de modélisation du lien entre deux variables, généralement dans le but de prévoir ou d'expliquer une variable en fonction de l'autre. L'analyse de régression peut fournir des estimations de la taille et de la direction de la relation, ainsi que des tests de signification statistique, des intervalles de confiance et des prévisions de résultats futurs.
Vos créations, prêtes en quelques minutes
Mind the Graph est une plateforme en ligne qui vous offre une vaste bibliothèque d'illustrations scientifiques et de conceptions infographiques qui peuvent être simplement modifiées pour répondre à vos besoins uniques. Créez des tableaux, des affiches et des résumés graphiques d'aspect professionnel en quelques minutes grâce à une interface de type "glisser-déposer" et à un large éventail d'outils et de fonctionnalités.



{kind=link}
{kind=link}

S'abonner à notre newsletter
Contenu exclusif de haute qualité sur le visuel efficace
la communication dans les sciences.