
En los últimos años, el aprendizaje automático se ha convertido en una poderosa herramienta en el campo de la ciencia, revolucionando la forma en que los investigadores exploran y analizan datos complejos. Con su capacidad para aprender automáticamente patrones, hacer predicciones y descubrir conocimientos ocultos, el aprendizaje automático ha abierto nuevas vías para la investigación científica. Este artículo tiene como objetivo destacar el papel crucial del aprendizaje automático en la ciencia explorando su amplia gama de aplicaciones, los avances logrados en este campo y el potencial que encierra para nuevos descubrimientos. Comprendiendo el funcionamiento del aprendizaje automático, los científicos están ampliando los límites del conocimiento, desentrañando fenómenos intrincados y allanando el camino para innovaciones revolucionarias.
¿Qué es el aprendizaje automático?
El aprendizaje automático es una rama de Inteligencia Artificial (IA) que se centra en el desarrollo de algoritmos y modelos que permiten a los ordenadores aprender de los datos y hacer predicciones o tomar decisiones sin estar explícitamente programados. Implica el estudio de técnicas estadísticas y computacionales que permiten a los ordenadores analizar e interpretar automáticamente patrones, relaciones y dependencias dentro de los datos, lo que conduce a la extracción de ideas y conocimientos valiosos.
Artículo relacionado: La inteligencia artificial en la ciencia
Aprendizaje automático en la ciencia
El aprendizaje automático se ha convertido en una poderosa herramienta en diversas disciplinas científicas, revolucionando la forma en que los investigadores analizan e interpretan conjuntos de datos complejos. En ciencia, las técnicas de aprendizaje automático se emplean para afrontar diversos retos, como predecir estructuras proteínicas, clasificar objetos astronómicos, modelizar patrones climáticos e identificar patrones en datos genéticos. Los científicos pueden entrenar algoritmos de aprendizaje automático para descubrir patrones ocultos, hacer predicciones precisas y comprender mejor fenómenos complejos utilizando grandes volúmenes de datos. El aprendizaje automático en la ciencia no sólo mejora la eficiencia y la precisión del análisis de datos, sino que también abre nuevas vías para el descubrimiento, lo que permite a los investigadores abordar cuestiones científicas complejas y acelerar los avances en sus respectivos campos.
Tipos de aprendizaje automático
Algunos tipos de aprendizaje automático abarcan una amplia gama de enfoques y técnicas, cada uno de ellos adecuado para diferentes dominios de problemas y características de los datos. Los investigadores y profesionales pueden elegir el enfoque más adecuado para sus tareas específicas y aprovechar la potencia del aprendizaje automático para extraer información y tomar decisiones fundamentadas. Estos son algunos de los tipos de aprendizaje automático:
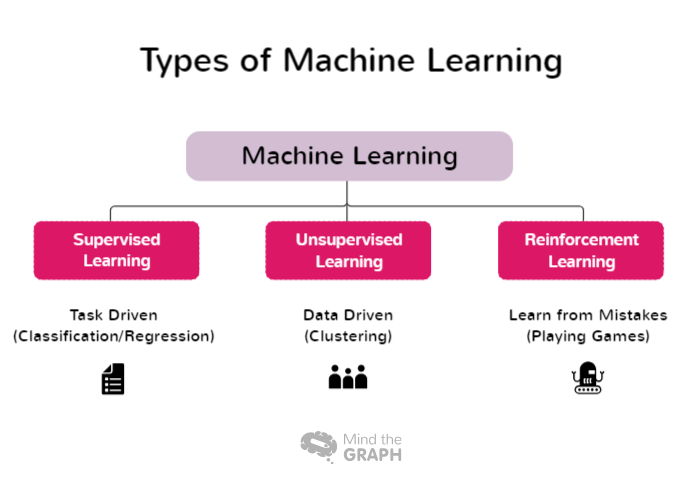
Aprendizaje supervisado
El aprendizaje supervisado es un enfoque fundamental del aprendizaje automático en el que el modelo se entrena utilizando conjuntos de datos etiquetados. En este contexto, los datos etiquetados se refieren a los datos de entrada que se emparejan con las etiquetas de salida u objetivo correspondientes. El objetivo del aprendizaje supervisado es permitir que el modelo aprenda patrones y relaciones entre las características de entrada y sus etiquetas correspondientes, lo que le permite hacer predicciones o clasificaciones precisas sobre datos nuevos y desconocidos.
Durante el proceso de entrenamiento, el modelo ajusta iterativamente sus parámetros basándose en los datos etiquetados proporcionados, esforzándose por minimizar la diferencia entre sus resultados predichos y las etiquetas verdaderas. De este modo, el modelo puede generalizar y realizar predicciones precisas sobre datos desconocidos. El aprendizaje supervisado se utiliza ampliamente en diversas aplicaciones, como el reconocimiento de imágenes, el reconocimiento del habla, el procesamiento del lenguaje natural y el análisis predictivo.
Aprendizaje no supervisado
El aprendizaje no supervisado es una rama del aprendizaje automático que se centra en analizar y agrupar conjuntos de datos no etiquetados sin utilizar etiquetas objetivo predefinidas. En el aprendizaje no supervisado, los algoritmos se diseñan para detectar automáticamente patrones, similitudes y diferencias en los datos. Al descubrir estas estructuras ocultas, el aprendizaje no supervisado permite a investigadores y organizaciones obtener información valiosa y tomar decisiones basadas en datos.
Este enfoque es especialmente útil en el análisis exploratorio de datos, donde el objetivo es comprender la estructura subyacente de los datos e identificar posibles patrones o relaciones. El aprendizaje no supervisado también encuentra aplicaciones en diversos ámbitos, como la segmentación de clientes, la detección de anomalías, los sistemas de recomendación y el reconocimiento de imágenes.
Aprendizaje por refuerzo
El aprendizaje por refuerzo (RL) es una rama del aprendizaje automático que se centra en cómo los agentes inteligentes pueden aprender a tomar decisiones óptimas en un entorno para maximizar las recompensas acumuladas. A diferencia del aprendizaje supervisado, que se basa en pares de entrada/salida etiquetados, o del aprendizaje no supervisado, que trata de descubrir patrones ocultos, el aprendizaje por refuerzo funciona aprendiendo de las interacciones con el entorno. La intención es encontrar un equilibrio entre la exploración, en la que el agente descubre nuevas estrategias, y la explotación, en la que el agente aprovecha sus conocimientos actuales para tomar decisiones informadas.
En el aprendizaje por refuerzo, el entorno suele describirse como un Proceso de decisión de Markov (MDP), lo que permite utilizar técnicas de programación dinámica. A diferencia de los métodos clásicos de programación dinámica, los algoritmos de RL no requieren un modelo matemático exacto del MDP y están diseñados para tratar problemas a gran escala en los que los métodos exactos resultan poco prácticos. Aplicando técnicas de aprendizaje por refuerzo, los agentes pueden adaptar y mejorar su capacidad de decisión a lo largo del tiempo, lo que lo convierte en un potente enfoque para tareas como la navegación autónoma, la robótica, los juegos y la gestión de recursos.
Algoritmos y técnicas de aprendizaje automático
Los algoritmos y técnicas de aprendizaje automático ofrecen diversas capacidades y se aplican en diversos ámbitos para resolver problemas complejos. Cada algoritmo tiene sus propios puntos fuertes y débiles, y conocer sus características puede ayudar a investigadores y profesionales a elegir el enfoque más adecuado para sus tareas específicas. Aprovechando estos algoritmos, los científicos pueden extraer información valiosa de los datos y tomar decisiones informadas en sus respectivos campos.
Bosques aleatorios
Los bosques aleatorios son un algoritmo popular en el aprendizaje automático que pertenece a la categoría de aprendizaje por conjuntos. Combina varios árboles de decisión para realizar predicciones o clasificar datos. Cada árbol de decisión del bosque aleatorio se entrena en un subconjunto diferente de datos, y la predicción final se determina sumando las predicciones de todos los árboles individuales. Los bosques aleatorios son conocidos por su capacidad para manejar conjuntos de datos complejos, proporcionar predicciones precisas y manejar valores perdidos. Se utilizan ampliamente en diversos campos, como las finanzas, la sanidad y el reconocimiento de imágenes.
Algoritmo de aprendizaje profundo
El aprendizaje profundo es un subconjunto del aprendizaje automático que se centra en el entrenamiento de redes neuronales artificiales con múltiples capas para aprender representaciones de datos. Los algoritmos de aprendizaje profundo, como Redes neuronales convolucionales (CNN) y Redes neuronales recurrentes (RNN), han logrado un éxito notable en tareas como el reconocimiento de imágenes y del habla, el procesamiento del lenguaje natural y los sistemas de recomendación. Los algoritmos de aprendizaje profundo pueden aprender automáticamente características jerárquicas a partir de datos brutos, lo que les permite captar patrones intrincados y hacer predicciones muy precisas. Sin embargo, los algoritmos de aprendizaje profundo requieren grandes cantidades de datos etiquetados y considerables recursos informáticos para su entrenamiento. Para saber más sobre el aprendizaje profundo, acceda a la Sitio web de IBM.
Procesos gaussianos
Los procesos gaussianos son una potente técnica utilizada en el aprendizaje automático para modelar y hacer predicciones basadas en distribuciones de probabilidad. Resultan especialmente útiles cuando se trabaja con conjuntos de datos pequeños y ruidosos. Los procesos gaussianos ofrecen un enfoque flexible y no paramétrico que permite modelizar relaciones complejas entre variables sin hacer grandes suposiciones sobre la distribución de datos subyacente. Suelen utilizarse en problemas de regresión, en los que el objetivo es estimar un resultado continuo a partir de características de entrada. Los procesos gaussianos tienen aplicaciones en campos como la geoestadística, las finanzas y la optimización.
Aplicación del aprendizaje automático a la ciencia
La aplicación del aprendizaje automático a la ciencia abre nuevas vías de investigación y permite a los científicos abordar problemas complejos, descubrir patrones y hacer predicciones a partir de conjuntos de datos amplios y diversos. Aprovechando el poder del aprendizaje automático, los científicos pueden obtener conocimientos más profundos, acelerar los descubrimientos científicos y hacer avanzar el conocimiento en diversos ámbitos científicos.
Imagen médica
El aprendizaje automático ha contribuido significativamente al diagnóstico por imagen, revolucionando las capacidades de diagnóstico y pronóstico. Los algoritmos de aprendizaje automático pueden analizar imágenes médicas como radiografías, resonancias magnéticas y tomografías computarizadas para ayudar a detectar y diagnosticar diversas enfermedades y afecciones. Pueden ayudar a identificar anomalías, segmentar órganos o tejidos y predecir los resultados de los pacientes. Al aprovechar el aprendizaje automático en el tratamiento de imágenes médicas, los profesionales sanitarios pueden mejorar la precisión y eficacia de sus diagnósticos, lo que se traduce en una mejor atención al paciente y una mejor planificación del tratamiento.
Aprendizaje activo
El aprendizaje activo es una técnica de aprendizaje automático que permite al algoritmo consultar interactivamente a un ser humano o a un oráculo para obtener datos etiquetados. En la investigación científica, el aprendizaje activo puede ser valioso cuando se trabaja con conjuntos de datos etiquetados limitados o cuando el proceso de anotación requiere mucho tiempo o es costoso. Al seleccionar de forma inteligente los casos más informativos para el etiquetado, los algoritmos de aprendizaje activo pueden lograr una gran precisión con menos ejemplos etiquetados, lo que reduce la carga de la anotación manual y acelera el descubrimiento científico.
Aplicaciones científicas
El aprendizaje automático encuentra amplias aplicaciones en diversas disciplinas científicas. En genómica, los algoritmos de aprendizaje automático pueden analizar secuencias de ADN y ARN para identificar variaciones genéticas, predecir estructuras de proteínas y comprender las funciones de los genes. En la ciencia de los materiales, el aprendizaje automático se emplea para diseñar nuevos materiales con las propiedades deseadas, acelerar el descubrimiento de materiales y optimizar los procesos de fabricación. Las técnicas de aprendizaje automático también se utilizan en las ciencias medioambientales para predecir y controlar los niveles de contaminación, predecir el tiempo y analizar los datos climáticos. Además, desempeña un papel crucial en la física, la química, la astronomía y muchos otros campos científicos al permitir el modelado, la simulación y el análisis basados en datos.
Ventajas del aprendizaje automático en la ciencia
Las ventajas del aprendizaje automático en la ciencia son numerosas e impactantes. He aquí algunas ventajas clave:
Modelización predictiva mejorada: Los algoritmos de aprendizaje automático pueden analizar conjuntos de datos grandes y complejos para identificar patrones, tendencias y relaciones que pueden no ser fácilmente reconocibles mediante métodos estadísticos tradicionales. Esto permite a los científicos desarrollar modelos predictivos precisos para diversos fenómenos y resultados científicos, lo que conduce a predicciones más precisas y a una mejor toma de decisiones.
Mayor eficiencia y automatización: Las técnicas de aprendizaje automático automatizan tareas repetitivas y laboriosas, lo que permite a los científicos centrar sus esfuerzos en aspectos más complejos y creativos de la investigación. Los algoritmos de aprendizaje automático pueden manejar grandes cantidades de datos, realizar análisis rápidos y generar ideas y conclusiones de forma eficiente. Esto aumenta la productividad y acelera el ritmo de los descubrimientos científicos.
Mejora del análisis y la interpretación de datos: Los algoritmos de aprendizaje automático destacan en el análisis de datos, lo que permite a los científicos extraer información valiosa de conjuntos de datos grandes y heterogéneos. Pueden identificar patrones ocultos, correlaciones y anomalías que pueden no ser evidentes de inmediato para los investigadores humanos. Las técnicas de aprendizaje automático también ayudan a interpretar los datos proporcionando explicaciones, visualizaciones y resúmenes que facilitan una comprensión más profunda de fenómenos científicos complejos.
Apoyo facilitado a la toma de decisiones: Los modelos de aprendizaje automático pueden servir a los científicos como herramientas de apoyo a la toma de decisiones. Mediante el análisis de datos históricos e información en tiempo real, los algoritmos de aprendizaje automático pueden ayudar en los procesos de toma de decisiones, como la selección de las vías de investigación más prometedoras, la optimización de parámetros experimentales o la identificación de riesgos o retos potenciales en proyectos científicos. Esto ayuda a los científicos a tomar decisiones con conocimiento de causa y aumenta las posibilidades de obtener resultados satisfactorios.
Aceleración del descubrimiento científico: El aprendizaje automático acelera el descubrimiento científico al permitir a los investigadores explorar grandes cantidades de datos, generar hipótesis y validar teorías de forma más eficiente. Al aprovechar los algoritmos de aprendizaje automático, los científicos pueden establecer nuevas conexiones, descubrir nuevos conocimientos e identificar líneas de investigación que de otro modo podrían haberse pasado por alto. Esto conduce a grandes avances en diversos campos científicos y fomenta la innovación.
Comunicar la ciencia visualmente con el poder del mejor creador de infografías gratuito
Mind the Graph es un valioso recurso que ayuda a los científicos a comunicar visualmente sus investigaciones. Con el poder del mejor creador de infografías gratuito, esta plataforma permite a los científicos crear infografías atractivas e informativas que representan visualmente conceptos y datos científicos complejos. Ya se trate de presentar los resultados de la investigación, explicar los procesos científicos o visualizar las tendencias de los datos, la plataforma Mind the Graph proporciona a los científicos los medios para comunicar visualmente su ciencia de forma clara y convincente. Regístrate gratis y empieza a crear un diseño ahora.





Suscríbase a nuestro boletín de noticias
Contenidos exclusivos de alta calidad sobre la eficacia visual
comunicación en la ciencia.