days
hours
minutes
seconds
Le blog scientifique Mind The Graph a pour but d'aider les scientifiques à apprendre à communiquer la science d'une manière simple.
Over the past few years, AI tools for researchers have become crucial, simplifying everything from literature discovery to manuscript writing and manuscript editing. The challenge lies in choosing the best AI tools for research that align with specific scholarly needs. Some focus on improving clarity and grammar, others on fact-checking and citation accuracy, while a few […]
Data visualization is the graphical representation of data and is used for understanding and communication, including common graphics such as pie charts and plots. Data visualization helps convey complex data relationships in an easy-to-understand manner, making it a critical part of research. For example, if numerical data in a table requires considerable effort to conceptualize a trend, plotting the data visually makes the trend immediately clear to the reader.
The way information is visually presented can influence human perception. Consider the pie chart, a visual representation designed to display how individual components contribute to a whole. It offers a simple way to organize data, allowing users to easily compare the size of each component with the others. Therefore, if a researcher needs to visualize proportions or relative contributions within a single category, a pie chart serves as a straightforward visualization tool.
Let’s explore how to make pie charts, common pie chart uses, pie chart examples, and more!
A simple pie chart definition is “a circular statistical graphic that is divided into radial slices to illustrate numerical proportion.” In this chart type, each categorical value corresponds to a single slice, and the size of that slice—measured by its area, arc length, and central angle—is designed to be proportional to the quantity it represents. Thus the main strength of the pie chart lies in how it helps convey data at a glance by instantly communicating the part-to-whole relationship.
Did you know that the pioneer of data visualization, Florence Nightingale, used an adaptation of the pie chart, the polar area diagram or rose diagram as early as in 1858? She used this diagram to illustrate seasonal sources of patient mortality in military hospitals during the Crimean War, demonstrating that deaths due to disease (represented by a large segment) far outweighed deaths caused by wounds or other factors.
Pie chart uses are limited to visualizing proportions where the primary objective is to show each group’s contribution relative to the total. Pie charts are especially useful when highlighting a particular slice whose proportion is close to a common fraction like 25% or 50%. They are highly effective in scenarios where simplicity and quick comprehension are paramount and where the chart needs to be compact. Note that pie charts are inappropriate for non-proportional data (data exceeding 100%) or when the goal is to compare groups to each other, rather than to the whole.
In modern social science, pie charts or effective alternatives are employed for data where the components must sum to 100%. Relevant pie chart examples include distribution of aggregate income, population demographics, and election results.
To handle complex data, researchers may turn to pie chart subtypes. For instance, treemaps can break down cumulative global CO2 emissions by country, and sunburst diagrams may be used for visualizing hierarchical data, such as an employee directory of a company divided by country and department, where the size of the segment represents the number of employees.
How to Calculate a Pie Chart Formula
To create a pie chart, you need to first know the pie chart formula. The steps to calculate it are as follows:
1. Add up the individual numbers to calculate the total number.
2. Divide 360 (the total number of degrees in the pie chart) by the total number. The resulting value will tell you the angle, in degrees, that each category equates to in terms of a pie chart.
3. Multiply each frequency by this angle value to get the angle for each segment of the pie chart. Remember, the segment angles should add up to 360°.
Put simply, to calculate the angle of each slice of a pie chart, the pie chart formula is as follows:
Segment angle = (360/total frequency) x category frequency
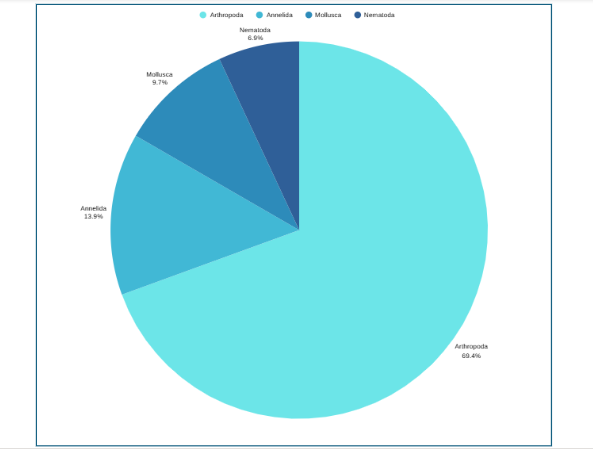
Now that you have understood how to calculate the pie chart formula, the next question is how to draw a pie chart? Suppose an ecologist has been tasked with understanding species distribution of various animal phyla in a forest understory. Here are the steps she will follow:
Étape 1 : Collect the data
Étape 2 : Tabulate the data:
| Animal phyla | Number of species |
| Arthropoda | 50 |
| Mollusca | 7 |
| Annelida | 10 |
| Nematoda | 5 |
The data above can be represented by a pie chart as following and by using the circle graph formula, i.e. the pie chart formula explained above.
Étape 3 : Add up the individual numbers to calculate the total number. In this case: 50 + 7 + 10 + 5 = 72.
Étape 4 : Divide 360 (the total number of degrees in the pie chart) by the total number. In this case: 360 ÷ 72 = 5, so each species is equal to 5° in the pie chart.
Étape 5 : Multiply each frequency by this angle value to get the angle for each segment of the pie chart:
| Animal phyla | Number of species | Angle |
| Arthropoda | 50 | 50 × 5° = 250° |
| Mollusca | 7 | 7 × 5° = 35° |
| Annelida | 10 | 10 × 5° = 50° |
| Nematoda | 5 | 5 × 5° = 25° |
Étape 6 : Draw a circle and use a protractor to measure the degree of each sector (see Figure 1). You can also use online pie chart makers as well.
Étape 7 : Label the sections and provide annotations and a legend.
Pie Chart Examples
Beyond the basic standard pie chart, there are several variants based on the circular concept, which are often used as alternatives for specific visualization needs.
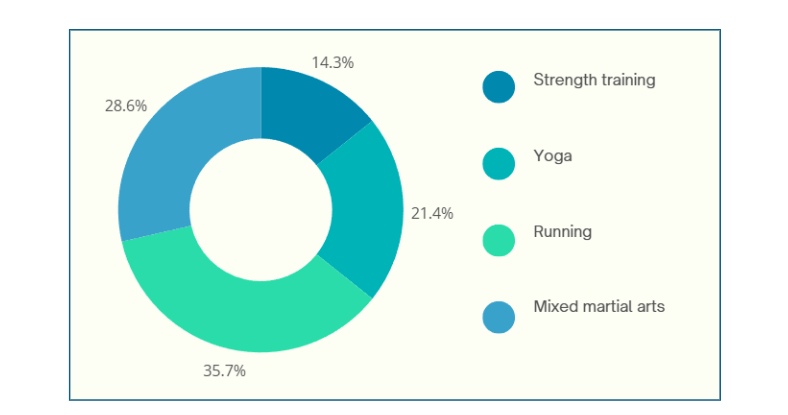
1. Donut chart: This is a variant of the pie chart with a hole in the center. Its primary purpose is to visualize data as a percentage of the whole (Figure 2).
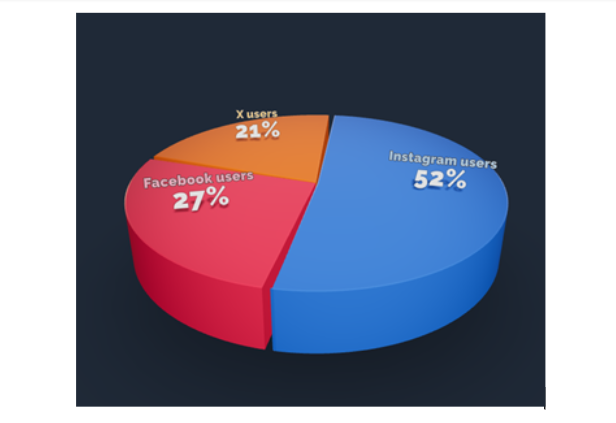
2. 3D Pie chart: This variant gives an aesthetic, three-dimensional look (see Figure 3). However, the use of perspective distorts the proportional encoding of the data, making these plots difficult to interpret accurately.
3. Exploded pie chart: This chart features one or more sectors “pulled out” from the rest of the disk to highlight a specific sector for emphasis.
4. Square chart (waffle chart): This chart uses color-coded squares, typically arranged in a 10 × 10 grid, where each cell represents 1%, instead of a circle, to represent proportions.
5. Polar area diagram (Nightingale diagram/rose diagram): This chart is similar to a pie chart, but the sectors all have equal angles and differ in how far they extend from the center (radius).
6. Treemaps: This is a “square” version of the pie chart that uses a rectangular area divided into sections; the area of the sections is proportional to the corresponding value. Treemaps can handle hierarchies, and visualize many more categories than a traditional pie chart.
When designing pie charts, careful consideration must be given to their specific limitations to ensure accurate and effective communication of data.
Dos when creating a pie chart
Don’ts when creating a pie chart
Pie charts have a specific, narrow use case, which contributes both to their enduring popularity and the intense criticism from data visualization experts.
Pie chart advantages
Pie chart disadvantages
Pie charts are a simple yet powerful tool for visually representing how each component contributes to a whole, making them invaluable for part‑to‑whole comparisons in research papers. They excel in quick, intuitive communication of proportion and are most effective when used with a suitable pie chart maker and an accurate pie chart formula that ensures all segments sum to 100%. However, they are limited to scenarios where data segments represent parts of a single whole; therefore, researchers should use them sparingly, ideally with five or fewer categories, clear labels, and accessible annotations that align with recommended pie chart uses. While alternatives like donut charts, waffle charts, and treemaps can address specialized visualization needs and overcome several pie chart disadvantages, one should steer clear of pie charts when precise group comparisons, complex data structures, or large datasets are involved, where other visuals are more suitable. To maximize effectiveness and truly leverage pie chart advantages, researchers should avoid 3D distortions, unnecessary colors, and non‑proportional data; follow best practices for how to create a pie chart; and always prioritize clarity and accessibility in visual design.
Pie charts show how each part contributes to a whole, ideal for visualizing proportions, while bar charts are better for comparing different categories or values across groups.
A 3D pie chart presents data with a three-dimensional look, but it distorts proportions and should generally be avoided for accurate interpretation of research data.
Pie charts are most effective with five or fewer categories; more slices can make interpretation difficult and cluttered.
Popular pie chart makers include Google Sheets, Microsoft Excel, Flourish Studio, and Tableau.
Mind the Graph is an easy-to-use visualization platform for researchers and scientists that enables fast creation of precise publication-ready graphical abstracts, infographics, posters, and slides. With 75,000+ scientifically accurate illustrations made by experts and hundreds of templates across 80+ major research fields, you can produce polished visuals in minutes — no design skills required.
Completing a thesis is a major milestone, but turning it into a publishable research paper is a different challenge altogether. Many researchers struggle with condensing a long, descriptive thesis into a clear, concise manuscript that meets journal standards.
To help you bridge this gap, Mind the Graph along with Paperpal is thrilled to announce the next session in The AI Exchange Series – How to Transform your Thesis into a Research Paper
Date : Thursday, November 27, 2025
Time: 8:30 AM EDT | 1:30 PM GMT | 7:00 PM IST
Language: English
Duration: 1 hour
In this session, we’ll break down the thesis-to-paper conversion process with clear, practical guidance on:

Dr. Faheem Ullah
Assistant Professor and Academic Influencer
Dr. Faheem Ullah is an award-winning academic and consultant specializing in AI and research methodologies. He holds a PhD and Postdoc in Computer Science from the University of Adelaide and has earned multiple distinctions, including two Gold Medals and a Bronze Medal. With over 40 publications in leading journals and conferences and experience supervising more than 40 undergraduate, master’s, and PhD researchers, Dr. Faheem brings deep insight into academic writing and ethical AI use.
A respected voice in the global research community, he has attracted an audience of over 300,000 followers, sharing advice on research skills, publishing, and responsible AI.
Publishing from your thesis can feel overwhelming, but the right guidance makes the process faster and more structured. This webinar will help you identify what’s publishable, avoid common mistakes, and reshape your thesis into a clear, journal-ready manuscript. Whether you’re a master’s or PhD researcher, you’ll walk away with practical steps and more confidence in your path to publication.
Don’t miss this chance to learn how to turn your thesis into a clear, compelling manuscript and take the next big step in your research journey – Register for free today!
Mind the Graph is an easy-to-use visualization platform for researchers and scientists that enables fast creation of precise publication-ready graphical abstracts, infographics, posters, and slides. With 75,000+ scientifically accurate illustrations made by experts and hundreds of templates across 80+ major research fields, you can produce polished visuals in minutes — no design skills required.
AI has quietly become a co-author in modern research. From grammar checks to literature reviews, tools powered by artificial intelligence are helping academics write faster and smarter. But there’s a growing challenge — most researchers don’t disclose their use of AI, even when journals require it.
In fact, recent data shows that over 75% of authors using AI fail to mention it in their submissions. With journal policies tightening and transparency becoming a pillar of academic integrity, understanding how and when to disclose AI use has become essential.
To unpack this important topic, Mind the Graph along with Paperpal is hosting a free webinar as part of The AI Exchange Series.
Date : Monday, November 10, 2025
Time: 1:00 PM EDT | 5:00 PM GMT | 10:30 PM IST
Language: English
Duration: 1 hour
This session will help researchers and educators navigate the grey areas of AI use in academia. You’ll learn:
Plus, join the live Q&A with our expert to get answers to your own questions about ethical AI use in research.

Professor Tina Austin
University of Southern California
Professor Tina Austin is an AI ethics consultant, biomedical researcher, and educator who helps universities and organizations adopt AI responsibly. She has taught at UCLA, USC, CSU, and Caltech in subjects ranging from regenerative medicine and computational biology to AI ethics and communication.
Tina is also the founder of GAInable.ai, a platform that empowers educators to use generative AI ethically and creatively. Recognized among ASU+GSV’s Top Leading Women in AI and as a Microsoft Innovative Educator Expert, she advises the California Department of Education and the Los Angeles AI Taskforce on responsible and inclusive AI adoption in education.
If you’re a student, researcher, or educator exploring AI in your academic writing, this session is for you. Gain the clarity and confidence to use AI tools responsibly while ensuring your work meets the highest ethical and publication standards.
Don’t miss this chance to learn directly from a global AI ethics expert and strengthen your approach to AI use in academia – Register for free today!
Mind the Graph is an easy-to-use visualization platform for researchers and scientists that enables fast creation of precise publication-ready graphical abstracts, infographics, posters, and slides. With 75,000+ scientifically accurate illustrations made by experts and hundreds of templates across 80+ major research fields, you can produce polished visuals in minutes — no design skills required.
Choosing the right color palette is one of the most important steps in creating clear, accurate, and engaging research visuals. A thoughtful color palette for data visualization helps your audience distinguish patterns, spot trends, and interpret results effortlessly. Whether you’re selecting colors for graph elements, deciding on a color for pie chart, or curating a consistent chart colors palette, your choices directly affect how your findings are understood. Understanding how to pick a color palette ensures that every shade serves a purpose rather than distracting from your message.
In research graphics, your color palette for graph should enhance readability while maintaining aesthetic harmony. The pie chart color palette must balance contrast and consistency, while bar chart colors should remain distinct enough to compare values easily. By focusing on accessibility, consistency, and meaning, you can identify the best colors for graphs and build a cohesive color palette that strengthens your scientific storytelling.
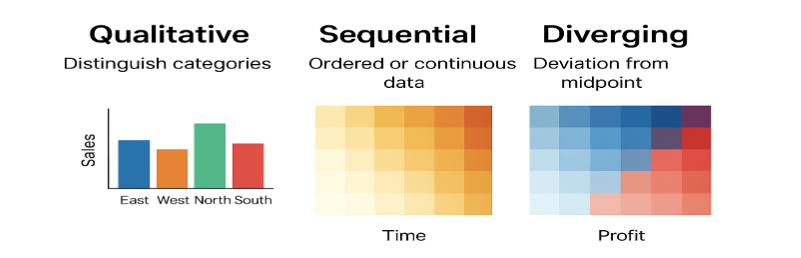
Choosing the right color palette ensures that your visualizations communicate meaning effectively. Each palette type conveys a different kind of data relationship — whether distinguishing categories, showing progression, or highlighting deviation. The table below summarizes the main types and includes example color sets.
| Palette Type | Use Case | Key Characteristics | Example Colors (Hex Codes) | Visual Example |
| Qualitatif | Distinct categories with no inherent order (e.g., departments, regions) | Multiple distinct hues; each category gets its own unique color. Limit to ~10 colors for clarity. | #1F77B4, #FF7F0E, #2CA02C, #D62728, #9467BD, #8C564B | 🟦 🟧 🟩 🟥 🟪 🟫 |
| Sequential | Ordered or numeric data showing magnitude or intensity (e.g., sales, temperature) | Gradient from light to dark or one hue to another; light = low, dark = high. | #FFF7EC, #FEE8C8, #FDBB84, #E34A33, #B30000 | ⚪️ 🟠 🟧 🟥 🔴 (light → dark red) |
| Diverging | Data centered around a critical midpoint (e.g., profit/loss, above/below average) | Two hues diverging from a neutral middle tone. Emphasizes deviation on both sides. | #1A9850, #66BD63, #F7F7F7, #F46D43, #D73027 | 🟢 🟩 ⚪️ 🟧 🔴 (green → neutral → red) |
Always keep accessibility in mind, ensuring adequate contrast and color-blind-friendly combinations. The right palette not only makes your data beautiful but also meaningful.
A color palette should be chosen with both clarity and accessibility in mind. When deciding how to choose a color palette, focus on contrast, consistency, and context—your colors should clearly distinguish categories without overwhelming the viewer.1 Start by defining your data type: use qualitative palettes for categories, sequential ones for gradients, and diverging palettes for comparisons. A well-selected color palette enhances storytelling, making colors for graphs and bar charts both visually appealing and easy to interpret. Testing your color palette for color blindness and grayscale readability ensures that your visuals remain inclusive and scientifically sound.
| Step | Action | Purpose/Consideration |
| 1. Define the Data Type | Identify if your data represents categories (qualitative), ordered values (sequential), or deviations from a midpoint (diverging). | Ensures the palette structure fits the data type. |
| 2. Determine the Key Message | Ask what you want your audience to notice first — trends, extremes, or group differences. | Helps select colors that emphasize the story, not just decorate. |
| 3. Choose a Suitable Palette Type | Qualitative → distinct hues (e.g., species, regions) Sequential → light to dark shades (e.g., temperature, time) Diverging → two hues meeting at a midpoint (e.g., profit/loss) | Matches color variation to data meaning. |
| 4. Check Context and Background | Consider where the visualization will appear (screen, print, dark/light background). | Ensures visibility and color accuracy. |
| 5. Test for Accessibility | Simulate color vision deficiencies (e.g., using Color Oracle, Coblis) and verify readability. | Ensures inclusivity for all viewers. |
| 6. Use Established Color Tools | Tools like ColorBrewer, Coolors, or Adobe Color provide balanced and tested palettes. | Speeds up selection and improves harmony. |
| 7. Validate with Your Audience | Show the palette to a few test viewers to check interpretability and comfort. | Confirms practical usability and effectiveness. |
Creating an inclusive and visually effective color palette is essential for ensuring that all viewers can interpret your research graphics accurately. From selecting colors for graph clarity to optimizing your pie chart color palette for accessibility, thoughtful design choices make your visuals both professional and user-friendly.
| Dos | Why It Matters |
| Use color-blind-friendly palettes (e.g., ColorBrewer “Set2”, “Dark2”, “Viridis”). | Makes visualizations readable for those with color-vision deficiencies. |
| Maintain a minimum contrast ratio of 4.5:1 between text and background. | Ensures legibility for people with low vision. |
| Combine color with patterns, textures, or labels for data distinction. | Enables interpretation even when color perception is limited. |
| Use neutral or light backgrounds for charts and maps. | Provides good contrast and reduces visual fatigue. |
| Test your designs using accessibility tools (e.g., Coblis, Color Contrast Checker). | Helps verify accessibility before publishing. |
| Keep color meanings consistent across visualizations. | Improves clarity and user understanding. |
| A ne pas faire | Why It’s a Problem |
| Don’t rely only on color to convey meaning. | Users with color blindness may miss critical information. |
| Don’t use red–green or blue–yellow combinations for key contrasts. | These are the most commonly confused pairs for people with color blindness. |
| Don’t use low-contrast text or small color differences. | Reduces readability and accessibility. |
| Don’t use bright or neon colors excessively. | Can strain eyes and make charts harder to interpret. |
| Don’t mix too many hues in one visualization. | Overcomplicates interpretation and reduces accessibility. |
Designing with accessibility in mind transforms your color palette from a simple design choice into a strong scientific communication tool, helping your insights reach every viewer with equal impact.
Learn h Mind the Graph’s PowerEdit tool to apply and fine-tune those colors directly to your research figures. PowerEdit helps you customize shades, adjust contrast, and maintain color consistency across multiple visuals effortlessly.
Selecting the right colors for graph elements is key to making your data both beautiful and meaningful. A well-thought-out color palette enhances clarity, readability, and consistency across all your visual materials. Whether you’re designing a color palette for data visualization, building a chart colors palette, or selecting the best colors for graphs, the following best practices will help you make confident, research-driven choices.
Step 1: Understand Your Data
Step 2: Choose an Appropriate Palette
Step 3: Consider Contrast and Legibility
Step 4: Keep the Palette Simple
Step 5: Maintain Consistency
Step 6: Align Colors with Meaning
Step 7: Adapt for Medium and Accessibility
Step 8: Provide Guidance
A thoughtfully selected color palette ensures that every visual is not only appealing but also clear, consistent, and accessible.
A carefully chosen color palette for data visualization ensures that your graphs, charts, and figures communicate data clearly and inclusively. Your choice impacts how effectively your audience can interpret your research. Use the following dos and don’ts as a quick guide to create a consistent, accessible, and visually appealing chart colors palette.
| Aspect | Dos | A ne pas faire |
| Audience Understanding | Choose palettes that match your audience’s familiarity and reading context. | Don’t assume all viewers interpret colors the same way. |
| Data–Color Relationship | Use logical color progressions to represent meaningful data differences. | Don’t assign random colors to unrelated categories. |
| Consistency Across Visuals | Keep similar color logic across multiple graphs or figures. | Don’t change palette meaning between figures. |
| Sensibilité au contexte | Test your palette on different backgrounds (light/dark) to ensure readability. | Don’t pick colors that disappear or blend into the background. |
| Cultural Meaning | Be aware of color associations (e.g., red for loss, green for gain). | Don’t ignore cultural interpretations that may mislead readers. |
| Printing and Sharing | Use palettes that retain clarity in grayscale or when printed. | Don’t rely solely on saturated hues that lose contrast when printed. |
| Tool Compatibility | Use palettes supported by major visualization tools (e.g., matplotlib, ggplot, Power BI). | Don’t use palettes that are hard to reproduce across platforms. |
In summary, following these simple dos and don’ts will help you design a color palette for graphs and other visuals that are professional, inclusive, and easy to interpret. A cohesive color palette not only improves aesthetics but also strengthens your research storytelling by keeping your chart colors palette clear, consistent, and accessible to all.
What is the difference between qualitative and sequential palettes?
Qualitative palettes use distinct, unrelated colors to represent different categories or groups—ideal for comparing nominal data like species, regions, or departments. Sequential palettes, on the other hand, use variations in lightness or saturation of a single hue (or a gradient between hues) to represent ordered or continuous data, such as temperature or population density. In short, qualitative palettes highlight differences in category, while sequential palettes show differences in amount.
How many colors should I use in a qualitative palette?
When creating a qualitative color palette, it’s best to use between five and eight distinct colors. This range provides enough variety to differentiate categories without overwhelming the viewer or making colors too similar to distinguish. If you need to represent more groups, consider using variations in shape, pattern, or brightness to maintain clarity and visual balance.
Why is color blindness important in data visualization?
Color blindness is crucial to consider in data visualization because around one in twelve men and one in two hundred women experience some form of color vision deficiency.2 When visualizations rely solely on color differences—like red and green—to convey meaning, key insights can become invisible to part of the audience. Designing with accessible color palettes ensures that every viewer can accurately interpret patterns and relationships, making your data both clearer and more inclusive.
Mind the Graph is an easy-to-use visualization platform for researchers and scientists that enables fast creation of precise publication-ready graphical abstracts, infographics, posters, and slides. With 75,000+ scientifically accurate illustrations made by experts and hundreds of templates across 80+ major research fields, you can produce polished visuals in minutes — no design skills required.
Références
AI tools have revolutionized the way researchers work, making academic writing and scientific communication more efficient than ever. But with these advantages comes a new challenge: AI hallucinations — confidently presented but factually incorrect outputs.
Our 2025 Paperpal survey revealed that 63% of academics using AI in their research workflows are concerned about accuracy. This growing anxiety around the reliability of AI-generated content isn’t unfounded. AI hallucinations can jeopardize the integrity of research, lead to unintentional plagiarism, and create credibility risks for authors.
To help you navigate this critical challenge, we’re excited to announce our upcoming webinar as part of The AI Exchange Series, where we’ll dive deep into understanding, recognizing, and avoiding AI hallucinations in both academic writing and research visuals with Paperpal et Mind the Graph.
Date : Thursday, October 30, 2025
Time: 1:00 PM EDT | 5:00 PM GMT | 10:30 PM IST
Language: English
Duration: 1 hour
This exclusive session will help you understand what AI hallucinations really are, why they happen, and how they can affect the credibility of your research. You’ll also learn practical strategies to identify and avoid them before they impact your writing or visuals.
Here’s what to expect:
Plus, you’ll have a chance to interact with our expert during a live Q&A and walk away with actionable insights to enhance your writing and communication workflow.

Emmanuel Tsekleves
Professor, Lancaster University
Emmanuel is a globally recognized academic with 130+ published research articles and extensive expertise in research excellence and academic integrity. A former Director of the Future Cities Research Institute, he advocates for responsible AI use in academia and guides researchers worldwide on ethical AI integration. His work has inspired over 220,000 researchers, and he serves on the Executive Board of the Design Research Society. He has supervised 14 PhDs and brings rich experience in research supervision and academic writing standards.
This webinar is designed for students, researchers, and educators who use AI in their research writing. By joining, you’ll gain a clear understanding of how to use AI tools responsibly and ensure that your work reflects the highest standards of academic integrity.
Don’t miss this opportunity to hear directly from a leading academic and walk away with a practical framework for reliable and ethical AI-assisted writing.
Don’t miss this chance to gain the clarity you need to navigate the grey areas and leverage AI responsibly in your research and writing – Register for free today!
Mind the Graph is an easy-to-use visualization platform for researchers and scientists that enables fast creation of precise publication-ready graphical abstracts, infographics, posters, and slides. With 75,000+ scientifically accurate illustrations made by experts and hundreds of templates across 80+ major research fields, you can produce polished visuals in minutes — no design skills required.
In a world where attention spans are shrinking, visual learning is no longer a “nice-to-have” — it’s essential. Research papers, journal articles, and presentations are often packed with dense text that only a few readers fully digest. Icons and visuals can cut through that clutter, making research communication clear and memorable. Tools like Mind the Graph empower scientists and scholars to transform complex data into intuitive visuals, whether that’s through scientific icons, infographics for research, or full-blown visual abstracts.
Why do visuals stick with us while text often fades away? The answer lies in the psychology of visual learning. Our brains are naturally wired to process images quickly and remember them for longer periods.
A recent study by Social Media Today revealed that posts using visuals receive 37% higher interaction than those with only text. Similarly, research cited by EmailAudience suggests the human brain can process images approximately 6–600 times faster than words. This proves why infographics for research and visual abstracts are such powerful tools — they capture attention instantly and convey meaning with clarity.
Selon Dual Coding Theory, when we combine words with images, our brain encodes information through two channels, doubling the chances of recall. Meanwhile, working memory has strict limits. Too much text can overwhelm, but a single scientific icon or infographic for research reduces that cognitive load dramatically.
This is why visual abstracts are gaining momentum in journals — they help readers absorb key findings in seconds. As highlighted in our article on Graphical Abstracts and Science Communication, researchers worldwide are embracing visuals not just as decoration, but as vital tools to convey science with speed and clarity.
When it comes to research communication, simplicity always wins. That’s where icons in research truly shine. Unlike text, icons transcend language barriers — a DNA helix or a microscope icon is instantly understood by scientists worldwide, regardless of the communication language.
Icons also strip away the unnecessary noise. A well-designed scientific icon communicates the essence of an idea without demanding readers parse long descriptions. This speed of comprehension leads to stronger retention, making icons one of the most efficient forms of visual storytelling in research.
Tools like Mind The Graph empowers researchers with thousands of professional icons specifically designed for science. Instead of spending hours creating visuals, scientists can focus on what truly matters: presenting their data in ways that capture attention and drive understanding.
The true power of visual learning lies in how it transforms real-world research communication. Here are some practical ways researchers are already applying visuals:
Visuals don’t replace text; they enhance it. In the context of research communication, they ensure faster comprehension, higher retention, and wider reach. By appealing to both logic and emotion, visuals make science more accessible and impactful.
Des plateformes comme Mind the Graph are democratizing this process by equipping researchers with intuitive tools for visual storytelling in research. In an era of information overload, those who master the art of visuals will stand out — their work not just read, but remembered.
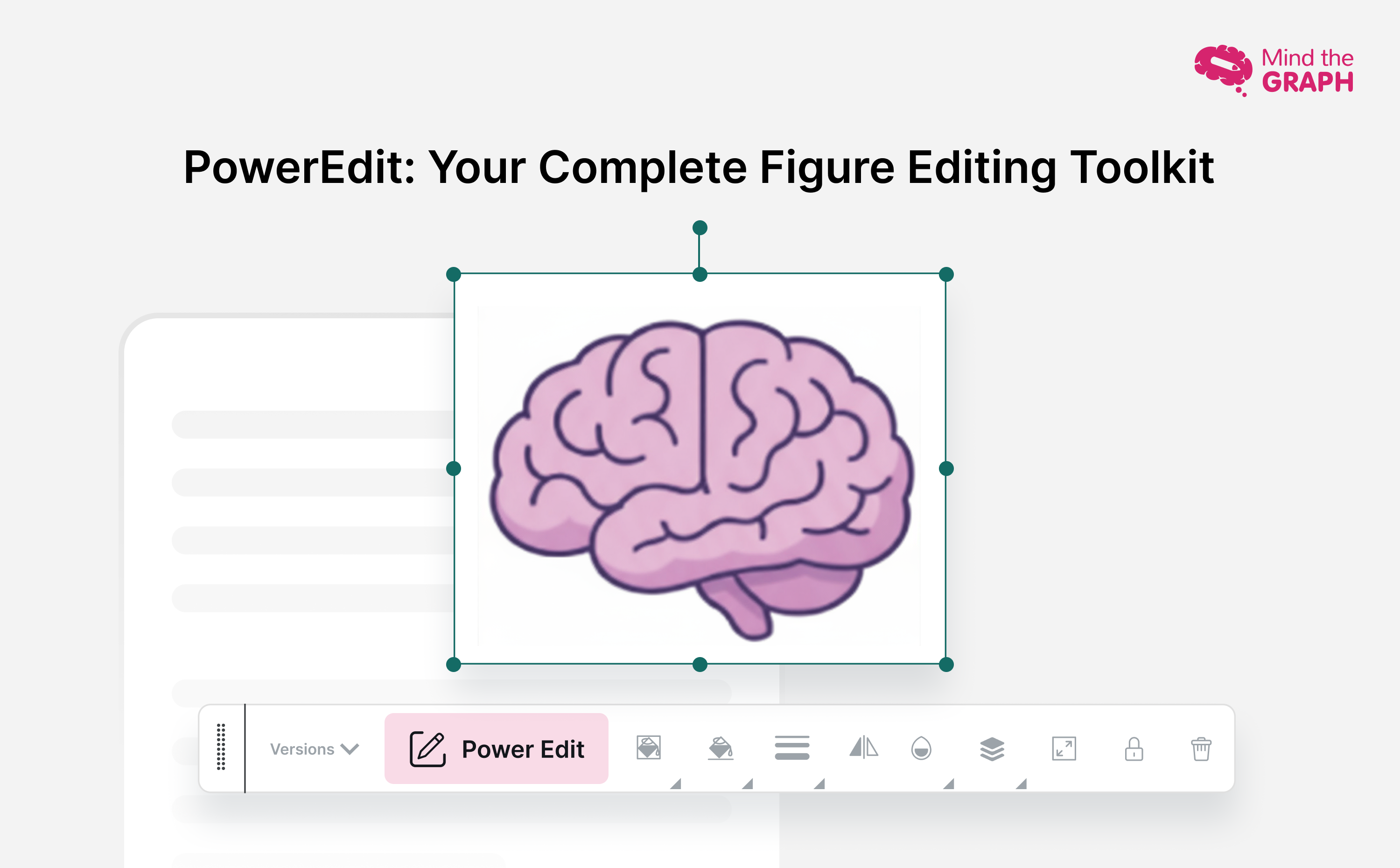
Great academics know that powerful visuals can transform research—but not all tools give you that creative freedom. That’s why we’re proud to unveil PowerEdit, our breakthrough figure editing tool for Mind the Graph. Now, you can craft publication-ready visuals that are as precise and compelling as your science.
Clear, professionally designed research figures boost reader engagement, improve comprehensibility, and even influence citation rates. D'après le MDPI, well-crafted visuals help research papers stand out and resonate more with audiences. Separate recherche shows that high-quality figures are also likely to increase the chance of acceptance in scientific journals—because clarity signals academic rigor.
Creating publication-ready visuals is not just about presentation; it’s about revealing the unseen patterns, insights, and trends in complex datasets that text alone can’t properly convey. This makes creating powerful and accurate scientific illustrations that convey your research story an essential skill for academics to master.
Yet academics looking to create research figures are frequently left struggling with rigid templates, inaccessible diagram elements, or generic visualization tools that are unable to adapt to scientific complexity. That’s the gap Mind the Graph’s new PowerEdit figure editing tool fills.
With PowerEdit, you can transform any Mind the Graph illustration into a powerful research figure that reflects your work, your voice:
When you add an illustration to your canvas on Mind the Graph, you’ll see a toolbar appear above it. In this toolbar, look for the PowerEdit button to edit your research figures.
With PowerEdit, you get complete control to customize research figures and illustrations and make them perfectly match your scientific story.
See PowerEdit in Action
▶️ Watch the demo to see how effortlessly PowerEdit turns standard illustrations into publication-ready visuals.
Mind the Graph’s PowerEdit feature is more than a convenience—it’s a productivity multiplier and clarity enhancer pour votre travail.
This isn’t just another feature, it’s the creative leverage researchers have been waiting for!
Try PowerEdit now and bring precision, agility, and professionalism to every research figure.
We value your input. Let us know how PowerEdit improves your visual workflow or share examples of its impact in your latest papers. If you have any questions or ideas on how we can make Mind the Graph even better for you, write to us at contact@mindthegraph.com. We’d love to hear from you!
Mind the Graph is an easy-to-use visualization platform for researchers and scientists that enables fast creation of precise publication-ready graphical abstracts, infographics, posters, and slides. With 75,000+ scientifically accurate illustrations made by experts and hundreds of templates across 80+ major research fields, you can produce polished visuals in minutes — no design skills required.
A scientific poster is an important and widely used format for sharing research in academic settings, particularly at conferences, workshops, and symposia. Unlike journal articles or oral presentations, a poster is a highly visual medium for summarizing complex ideas in a concise, accessible way. It allows researchers to communicate their work beyond words by integrating text, figures, charts, and images into a single, engaging layout.
Effective visualization is central to research communication. Visual elements help audiences process information faster and remember it longer. Well‑designed visuals can make otherwise dense data approachable. What is more, engaging visualizations spark discussions and invite useful feedback.
A scientific poster condenses months or years of investigation into a format that foregrounds clarity and creativity, while encouraging direct interaction between researcher and audience. An engaging and dynamic conference poster presentation has the power to infuse life into static information, transforming your work into a conversation starter or even a networking tool!
In this article, you will learn how to make a poster presentation, see actual research poster examples, and get to know about scientific poster software.
Simply put, a poster is a visual summary of a research project designed to communicate seminal findings, methods, and insights in an attractive and accessible way. During poster sessions, researchers stand by their displays to interact directly with attendees and answer questions, turning the poster into both an informational tool and a springboard for dialog and networking.
Although academic conferences can be traced back to 1860, with the first international scientific conference held in Germany, poster sessions did not emerge until a century later. The conference poster presentation concept appears to have begun in Europe before making its way across the Atlantic to North America at the 1974 Biochemistry/Biophysics Meeting in Minneapolis. The American Chemical Society adopted poster sessions for their fall national conference in Chicago in 1975.
Scientific and research posters are visual representations of research or scientific work presented at scholarly conferences or symposiums. They are a handy and powerful means for knowledge dissemination and research networking within academic communities.
Both scientific and research posters incorporate a mix of brief text with tables, graphs, figures, infographics, charts, and images to convey major findings, data, and the significance of the research. Figures and tables are often the main focus, as they can describe research in detail with minimal text. Further, both scientific and research posters are organized to present research as a logical, coherent story. Common sections include a title, authors, abstract, introduction, materials and methods, results, discussion, conclusions, citations, and acknowledgements.
While both types of posters serve as communication tools, a scientific poster is usually focused on the visual presentation of scientific research or experiments, often with standardized sections and an emphasis on data visualization. Research posters, more broadly, may summarize studies across various fields and sometimes include theoretical or review work.
Let’s look at how to create a scientific poster that really stands out. A great scientific poster is visually engaging and clear, effectively communicating salient findings to a diverse audience. Think of it as a hybrid between a published paper and an oral presentation. Here are some ways to take a poster from good to great:
Now, let’s get down to the design essentials of how to create a scientific poster.
Mise en page
A scientific poster has an organized and simple design with a consistent layout. Content should fall into logical sections that flow clearly from one to the next, creating a visual path for the reader. Direction of reading is typically top to bottom and left to right. A poster might therefore even have a visual shaped like an “M.” Place your content strategically, while utilizing symmetry and white space smartly. Using a grid can help structure your layout evenly. In this way, text and images can be aligned properly.
Standard sizes
The standard size of a scientific poster is 36 × 48 inches, typically in portrait orientation. The poster should use easy-to-read fonts, with sans serif fonts preferred. Use varying font sizes (24–48 pt) to differentiate between the title, body text, headings, and highlights. The title should be readable from about 10 feet away (at least 40 pt), section headings 30–40 pt, and body text/captions 24–30 pt. Avoid font sizes smaller than 20 pt for most sections, except for references and acknowledgements
Color schemes
Your poster should follow a visually appealing and easy-to-read color scheme, with high-contrast colors to highlight important information. A cohesive color scheme, perhaps inspired by a key image, can reduce clutter. Use clear, white, or pastel backgrounds.
High-quality visuals
Figures and tables should be the main focus, serving as informative visuals that help tell the story. For photographs or illustrations, use high-quality, high-resolution images (ideally 300 DPI, saved in PNG or TIFF formats). Avoid using blown-up photos as poster backgrounds.
Common sections in a scientific poster are as follows:
An additional, optional part of scientific posters might be a resource link or QR code to access additional materials.
Compelling scientific posters have the power to grab the attention of academic stalwarts and industry leaders, leading to collaboration opportunities and career progression. “Best Poster Awards” often carry cash prizes too!
With a plethora of tools and resources available today, you can amp up the quality and impact of your posters. For example, a university research lab used Mind the Graph (MTG) to create eye-catching conference posters that effectively presented complex data and drew significant attention. In another case, independent researchers used the platform’s scientific illustrations for a science fair poster that successfully communicated their findings to audiences ranging from scientists to the general public, ultimately winning the Best Poster Award.
Let’s look at some scientific poster examples (templates and layouts) that might inspire your next poster!

Browse ici for more research poster examples.
Wondering how to make a scientific poster or where to get started? Here’s a handy checklist with key steps:
1. Plan and brainstorm
Spend time narrowing your focus down to the main message and main findings of your research. Think of the pertinent data, stories, or visuals that will make your poster engaging.
2. Put your data and information together
Organize all your research outputs (figures, tables, methods, results, and conclusions) and ensure that visuals and summaries are complete before outlining the final.
3. Outline the content
Draft a logical structure: group related information and plan which elements will be visual versus narrative.
4. Put it all together
Start designing your scientific poster on your chosen software or template. You can use tools like Mind the Graph, which offer numerous template options and galleries with professional and customizable illustrations. Insert the content into well-defined blocks, add figures/tables, and use coherent color schemes, fonts, and layouts.
5. Review and feedback
Share your draft with colleagues or mentors for input on clarity, flow, and impact. Collect suggestions for improving scientific accuracy, accessibility, and aesthetics, and edit your draft accordingly.
6. Test print
Do a trial print (at a reduced size) to check if all elements are legible and well formatted. Assess color quality, scaling, and possible layout issues.
7. Proofread!
Scrutinize every part of your poster for typos, grammatical errors, and factual inconsistencies. Double-check names, affiliations, and reference formatting for professional presentation.
8. Final print
After final adjustments, print the poster at full scale following the conference specifications for size and format. Use high-resolution files and quality printing materials for a polished result.
Here are some important tips academics should keep in mind when creating posters:
Did you know that many conferences have “Best Poster Awards”? Now, wouldn’t you like your research poster to win a prize? Here are some practical tips that will make your poster shine!
1. Balance visuals with text: Aim for a visually engaging poster by maintaining generous white space and balancing striking images or graphics with concise, supporting text. Avoid dense blocks of writing.
2. Avoid excessive jargon: Limit technical jargon or acronyms to ensure your work is accessible to both specialists and non-specialists.
3. Use tables and charts smartly: Charts are preferred for conveying numeric patterns, relative sizes, comparative outcomes, or trends, reducing the need for extensive text. Provide charts with clear, large titles and succinct annotations explaining patterns. Simplified tables can replace large, detailed statistical tables.
4. Use high-resolution images: All images, diagrams, and icons should be crisp and high-resolution (at least 300 DPI) to prevent pixelation or blurriness on large posters.
5. Avoid clutter: Use margins and padding between sections. Eliminate redundant text, unnecessary logos, or decorative elements that do not support your main message.
6. Get creative: Consider experimenting with design elements and layouts and adding interactive elements.
You can choose from a wide and ever-growing list of tools to create a scientific poster: Mind the Graph (suitable for scholarly posters), Microsoft PowerPoint, Google Slides (often free), Adobe Illustrator (for high-quality graphics), Canva (user-friendly web-based), LaTeX (for scientific publications), Mac Pages, and Inkscape (free vector design).
Let’s break down the pros and cons of some of these scientific poster software:
Pour
Cons
Pour
Cons
Pour
Cons
Pour
Cons
We have carefully deciphered all the dos and don’ts of scientific poster making. But acing poster-making is not enough. You also need to know how to make a poster presentation impressive and memorable.
You should be prepared to verbally explain your work with a brief oral synopsis of your objectives, main findings, and implications. You could even prepare a few questions to ask viewers to encourage dialog. A good practice is to provide handouts with additional technical details, full results, and contact information.
Your scientific poster might be your first presentation or publication. And so, it could well be the first step into the academic spotlight. Make the most of the opportunity to leave a lasting impression!
Q. What are the different types of scientific posters?
A. Scientific posters generally fall into two main formats: physical posters (printed and pinned at events) and e-posters (digital versions displayed on screens). Both can be static (single-page or slides) or dynamic (including animations and videos). Within posters, common styles include traditional research posters and infographic-style posters for outreach.
Q. How to make a poster presentation for conferences?
A. For your conference poster presentation, (i) focus on clarity; (ii) highlight major findings; (iii) prepare your verbal summary (practice a 3–5-minute overview for conversation and questions); and (iv) stand by your poster, invite questions, and remain enthusiastic about your research.
Q. How to decide the layout of your poster scientifique?
A. When deciding the layout of your poster, ensure logical flow (use columns and group information into sections—title, authors, introduction, methods, results, and conclusion), maintain visual hierarchy (keep important findings prominent, and maintain white space for readability), while maintaining consistency and adhering to the conference guidelines.
Mind the Graph is an easy-to-use visualization platform for researchers and scientists that enables fast creation of precise publication-ready graphical abstracts, infographics, posters, and slides. With 75,000+ scientifically accurate illustrations made by experts and hundreds of templates across 80+ major research fields, you can produce polished visuals in minutes — no design skills required.
Creating compelling scientific illustrations shouldn’t require a PhD in graphic design or drain your research budget. Yet, here you are, staring at complex data that needs to become a clear, publication-ready figure by tomorrow’s deadline.
Sound familiar?
Whether you’re preparing a manuscript, grant proposal, or conference presentation, the right scientific illustration tool can transform hours of frustration into minutes of creative flow. In this article, we’ll explore the capabilities of two popular scientific illustration tools Mind the Graph vs BioRender and pit them against each other.
| Feature | Mind the Graph | BioRender |
| Illustration Library | 75,000+ across all sciences | 40,000+ specific to life sciences |
| Templates | 300+ templates | 5,000+ templates |
| Scientific Fields Covered | 80+ scientific fields | 30+ life science specialties |
| Custom Illustration Requests | 7-day turnaround time (with paid plans) | 25-30 business days turnaround time |
| Drag-and-Drop Editor | Easy to use for beginners without any design knowledge | Science-specific canvas with bio-brushes |
| Image Downloads | Download quality up to 1200 DPI with unlimited zoom option | Download quality up to 600 DPI |
| Editable SVGs | Dissect SVG icons within the editor and change icons, colors, background/foreground layers, and adjust styles within the editor | SVG icons on BioRender need to be exported to Adobe Illustrator to edit |
| Version History | Full tracking with version history and undo-redo options | Full tracking with undo-redo options |
| Real-time Collaboration | Multi-user access with commenting | Multi-user access with commenting; allows for simultaneous changes |
| Brand Kits | Available | Available |
| Pricing | $15/month or $72/year | $35/month or $420/year |
BioRender is a comprehensive scientific illustration platform that helps researchers and scientists create professional, publication-quality figures without needing artistic skills.
BioRender’s scientific illustration library hosts over 40,000 icons and illustrations, and 5,000 templates specifically designed for diverse life science fields, including molecular biology, neuroscience, microbiology, immunology, and clinical research. Extending its capabilities to data visualizations, graph integration, and AI-powered features, BioRender has established itself as the premium choice for biological illustrations.
Here’s an overview of BioRender’s core capabilities:
While BioRender is a great scientific illustration tool, many scientists and researchers are seeking alternatives to BioRender because its restrictive copyright policies create barriers in academic publishing and collaboration.
| Comparison Factor | Mind the Graph | BioRender |
| Content Ownership | Free users: CC BY-SA license Prime users: Full ownership and authorship rights | BioRender retains copyright of all icons/templates; users only own “scientific story” |
| Attribution Requirements | No attribution needed for Prime users | Mandatory “Created with BioRender.com” attribution required for ALL users regardless of subscription |
| Watermark Policy | Watermark-free exports for prime users | Users cannot remove watermarks/logos from BioRender content |
| Commercial Usage Rights | Free users: Commercial use allowed under CC BY-SA Prime users: Unrestricted commercial rights | Requires Premium subscription for commercial use |
| Content Modification & Redistribution | Free users: Can adapt, remix, redistribute assets under same license Prime users: Full modification rights | Limited rights to modify; cannot redistribute BioRender assets |
| Open Access Compliance | CC BY-SA license fully compatible with open access publishing standards | Licensing conflicts with CC-BY journals and open access requirements |
| Collaboration & Sharing | Collaboration under CC license and unrestricted sharing for prime users | Restricted sharing due to BioRender’s copyright retention |
| Third-Party Publisher Rights | Prime users can transfer authorial rights directly to publishers | Complex licensing negotiations required |
| Long-term Use Guarantee | CC license provides permanent usage rights even if service discontinues | Dependent on BioRender’s continued service and policy changes |
These constraints have driven researchers to seek BioRender alternatives that offer more flexible licensing, full ownership rights, or open-source solutions that better align with academic publishing standards and collaborative research practices.
Mind the Graph stands out as the leading BioRender alternative, as the “Canva for Scientists and Researchers” with an extensive library of over 75,000 scientific illustrations spanning 80+ specialized fields.
With Mind the Graph, researchers can access and customize everything from quantum mechanics and geological processes to cellular pathways and neuroscience illustrations without needing any design expertise.
The platform’s intuitive drag-and-drop editor allows you to create professional-quality scientific visuals effortlessly, while its advanced editing capabilities let you modify even the smallest SVG elements, adjusting layers, colors, and styles directly within the platform. This eliminates the need to export illustrations to edit on Adobe Illustrator or be forced to manage multiple tools.
With transparent licensing and clear usage rights, this BioRender alternative provides researchers with a hassle-free, all-in-one solution for scientific illustrations that delivers both the quantity of resources and the precision needed for academic publications, presentations, and educational materials across any scientific discipline.
Let’s talk about what you can achieve with Mind the Graph:
BioRender and Mind the Graph both offer unique capabilities to design scientific illustrations, but Mind the Graph is a far more affordable alternative to BioRender.
Mind the Graph: $72/year
BioRender : $420/year
Mind the Graph stands out as the ideal BioRender alternative, helping academics create accurate scientific illustrations without requiring exceptional design skills or following an extensive learning curve. The platform’s scientific illustrations come with Creative Commons licensing that seamlessly supports open access publishing, eliminating the compliance issues that plague BioRender users.
With Mind the Graph’s Researcher or Prime subscription plan, academics gain complete ownership of all visual assets with zero attribution requirements, providing true freedom to use, share, or modify your illustrations however needed. You can unlock Mind the Graph’s full capabilities at an unbeatable price of just $15/month or $72/year—making professional scientific visualization accessible to every researcher.
Create Scientific Illustrations Faster, without any hassle. Get Mind the Graph Prime aujourd'hui !
Still unsure which scientific illustration tool to choose? Here’s a quick guide tailored to your specific needs to help you decide between Mind the Graph and BioRender:
Choose Mind the Graph when:
Choose BioRender when:
Stop letting limited libraries and restrictive usage terms hold back your visual communication. Join the 75,000+ researchers who’ve discovered that professional scientific illustration doesn’t require a premium budget.
Create your first 4 illustrations at no cost. Start with a free Mind the Graph account today! Create Your Free Account and start illustrating your science in minutes, not hours.
Research design is the backbone of any successful study—it’s the structured plan that guides how you collect, analyze, and interpret data. Think of it as the blueprint of your project: without it, your research risks becoming unfocused or unreliable. Whether you’re a student working on a dissertation, a professional conducting a survey, or a researcher designing a clinical trial, choosing the right research design ensures your study stays on track and produces meaningful results.
A good research design doesn’t just tell you what methods to use—it shapes the entire process, from defining your research question to analyzing the data. It helps you avoid common errors, reduces bias, and improves reliability and validity.1 In other words, it ensures that the findings you present are trustworthy and can be applied with confidence in real-world situations.
This article covers everything you need to know about research design: its definition, key steps in creating a design, different types of research design, and the benefits of choosing the right one. We’ll also look at the differences between qualitative and quantitative research design, complete with examples to make things easy to understand.
Research design is the structured framework that outlines how a study will be conducted, guiding everything from formulating the research question to collecting and analyzing data. It acts as a blueprint, ensuring that the research process is logical, systematic, and aligned with the study’s objectives.1,2 Without it, research can become unfocused, unreliable, or even invalid.
A good research design clearly defines whether a study will use a qualitative approach (to explore experiences and meanings), a quantitative approach (to measure variables and test hypotheses), or a mixed-methods approach that combines both. It also determines important elements such as the target population, sampling methods, data collection tools, and analysis techniques.
What makes research design essential is its role in ensuring reliability, validity, and accuracy. By setting a clear structure, it reduces bias, minimizes errors, and increases the credibility of findings. For example, in clinical trials or social research, a strong design is what makes the results trustworthy and applicable to real-world contexts.
In short, research design is more than just planning—it’s the foundation that connects research questions to meaningful, actionable conclusions.
Getting research design right is not optional—it’s the foundation of any successful study. A strong design shapes every stage of research, ensuring that the process is efficient, focused, and trustworthy. Let’s look at the core reasons why it matters so much:
In essence, good research design doesn’t just support the process—it drives research success by transforming ideas into actionable knowledge.
Beyond planning and execution, it’s equally important to present your research effectively. Mind the Graph enables researchers to create professional, visually appealing graphics that make complex results easy to understand.
A good research design goes beyond just structuring a study—it ensures that research instruments, methods, and processes all work together to produce reliable and meaningful results. When done right, it not only enhances the credibility of findings but also makes the research process smoother and more efficient.
Here are the key characteristics of good research design that every researcher should aim for:
In essence, the characteristics of good research design act as guiding principles that transform a study from just “collecting data” into producing knowledge that is trustworthy, impactful, and actionable.
Think of research design as the blueprint that shapes your study—it tells you what to focus on, how to collect data, and how to analyze it. Without a clear design, even the best ideas can lose direction.
Here are the key elements every strong research design should include:
When designing a study, one key decision is whether to adopt a qualitative or quantitative research design. Both have unique strengths and suit different research questions.2
| Aspect | Qualitative Research Design | Quantitative Research Design |
| Objectif | Explores meanings, experiences, and perspectives. | Measures variables, tests hypotheses, and finds patterns. |
| Research Questions | Focuses on “how” and “why.” | Focuses on “what,” “how many,” or “to what extent.” |
| Collecte de données | Interviews, focus groups, observations, open-ended questions. | Surveys, experiments, questionnaires, structured tools. |
| Data Type | Non-numerical, descriptive, and rich in detail. | Numerical, statistical, and measurable. |
| Analyse | Thematic, interpretive, and narrative analysis. | Statistical tests, correlations, and mathematical models. |
| Outcome | Provides deep insights, context, and new ideas. | Produces generalizable, reliable, and measurable results. |
| Exemple | Exploring student experiences with online learning. | Testing whether online learning improves exam scores. |
In practice, researchers often combine both in a mixed-methods research design to capture the best of both worlds—deep insights from qualitative data and measurable evidence from quantitative analysis.
Research design is not one-size-fits-all. Depending on the goals of your research—whether it’s to explore new ideas, describe trends, or establish cause-and-effect relationships—different designs are more suitable than others.
Here are the main types of research design, summarized in a clear comparison table.
| Research Design Type | Purpose / Description | Methods Used | Exemple |
| Exploratoire | Investigates new or unclear problems to gain insights and define research questions. | Interviews, focus groups, literature reviews. | A researcher conducts focus groups to explore how Gen Z perceives the rise of AI-generated content on TikTok. |
| Descriptive | Describes characteristics, behaviors, or phenomena in detail. Answers what, where, when, and how. | Surveys, case studies, observational research. | A survey measures how often users aged 18–30 post stories on Instagram each week. |
| Correlational | Examines relationships between two or more variables without proving causation. | Statistical analysis of patterns and associations. | A study analyzes the relationship between time spent on Twitter (X) and levels of political engagement. |
| Causal / Experimental | Tests cause-and-effect by manipulating independent variables under controlled conditions. | Randomized controlled trials, lab experiments. | Researchers run an experiment where some participants are exposed to positive social media content and others to negative content, then measure mood changes. |
| Quasi-experimental | Explores causal relationships without full experimental control (e.g., no random assignment). | Pretest–posttest studies, natural experiments. | A platform introduces a new “dislike” button for certain users; researchers compare engagement before and after. |
| Méthodes mixtes | Combines qualitative and quantitative approaches to provide both depth and breadth. | Sequential studies, convergent parallel designs. | A study uses surveys to quantify how often people use Instagram for news, followed by interviews to explore pourquoi they prefer it over traditional media. |
Each type of research design serves a unique purpose. Exploratory research is best for uncovering new insights, descriptive designs help map out details of a phenomenon, correlational studies reveal patterns, while causal and quasi-experimental designs test cause-and-effect. Mixed methods, on the other hand, bring together the strengths of both qualitative and quantitative approaches. By understanding these options, researchers can choose the design that best matches their objectives and ensures reliable, meaningful results.
Crafting the right research design ensures your research question, methods, and analysis all align to produce meaningful and reliable results. Here’s a step-by-step guide to get it right:
With these steps, your research design becomes a structured roadmap that keeps your study organized, minimizes bias, and leads to results that are credible and impactful.
With the right research design in place, researchers can unlock several key benefits that make their studies more effective and impactful—here are some of the most important benefits.
1. Keeps you organized: Think of research design as your roadmap—it lays out the steps from start to finish so you don’t get lost along the way. For example, if you’re studying the effects of social media on student productivity, a clear design will tell you whether to run surveys, experiments, or interviews, instead of trying random methods that don’t connect.
2. Helps answer your research question: A good design makes sure your methods align with your goals. If your question is “Does daily exercise improve focus?”, then an experimental design with a control and test group will help you actually measure the impact—rather than just asking people what they think.
3. Reduces mistakes and bias: Without a solid design, it’s easy to fall into traps like sampling the wrong group or asking leading questions. For instance, interviewing only your friends about social media habits could skew results. A well-thought-out design ensures your participants and questions stay fair and representative.
4. Boosts reliability and validity: Strong research design makes your results more accurate and trustworthy. If you repeat the same study with different groups and still get similar results, that shows reliability. Validity means you’re measuring what you set out to measure—like testing focus with actual tasks instead of just self-reported feelings.
5. Saves time and resources: A clear plan prevents wasted effort. Imagine starting interviews only to realize later that a simple survey could have answered your question faster. Good design avoids backtracking and helps you use your time, budget, and participants wisely.
6. Improves impact: When your research is well-structured, the findings are meaningful and applicable. For example, a study on study techniques that’s designed properly could give schools actionable insights to improve teaching methods—rather than vague results that don’t change anything.
In short, good research design is your secret weapon—it keeps your project focused, reliable, and impactful, while making the process smoother and more efficient.
A strong research design acts as the framework of a study, ensuring clarity, consistency, and credibility from start to finish. By carefully aligning your research questions with the right methodology—whether qualitative, quantitative, or mixed-methods—you can choose the most suitable research design, such as experimental, survey, case study, or ethnographic, to guide sampling, data collection, and analysis. Selecting the right design minimizes bias, strengthens validity and reliability, and ultimately makes findings more meaningful.1 A well-planned design provides structure and ensures that every stage—from formulating objectives to interpreting results—works in harmony to produce impactful research.
Remember, how you communicate findings is as important as how you design your study. With Mind the Graph, you can create clear, professional visuals that make your research more engaging and accessible.
Choosing the right research design shapes everything from defining your research questions and choosing methods, to collecting data, analyzing findings, and interpreting results. It provides structure and ensures that each step supports your objectives, and helps you align your tools and approach to what you’re actually trying to discover. The chosen design sets the tone for every phase of the process. It is the logical plan that ensures consistency and coherence across all stages, from defining aims to drawing final conclusions.
Even the most well-intentioned studies can stumble into common pitfalls—from sampling and selection errors, where unrepresentative or self-selected participants skew findings, to measurement issues like ambiguous questions or inconsistent scales that confuse respondents. Response biases—such as social desirability or acquiescence—can nudge participants toward answers they think are expected, rather than what they truly believe. Meanwhile, observer or confirmation biases may lead researchers to unintentionally favor data that aligns with their expectations. To prevent these issues, clearly define your population and use representative sampling, craft neutral and unambiguous questions (ideally pre-tested), ensure consistent measurement scales, anonymize responses where appropriate, and employ strategies like blinding or structured protocols to counteract researcher expectations.
Choosing the right research design starts with clarifying your research question and whether you need a qualitative, quantitative, or mixed-methods approach. From there, select a design—such as experimental, survey, case study, or ethnographic—that aligns with your goals, resources, and ethical considerations. It’s also critical to define your target population, sampling method, and data collection strategy while ensuring reliability and validity to strengthen your findings and ensure your design matches your research objectives.
Références
Generative AI tools are transforming how researchers and students write, yet many still face uncertainty about what’s ethical, what’s allowed, and how to avoid unintentional mistakes. Paperpal’s recent survey of 1,400+ academics revealed that while over 80% use AI tools for their research and writing, 44% of the respondents were unclear on institutional policies and AI disclosure requirements.
AI is quickly reshaping academia but where do the boundaries lie? As part of The AI Exchange initiative by Paperpal, this exclusive panel discussion will deliver clear answers on AI detection, disclosures, and responsible use. Mind the Graph and Paperpal, interconnected tools that help researchers communicate their work more effectively—one through visuals and the other through writing—come together here to extend this important conversation.
Join us for an exclusive panel discussion with top academic experts!
AI for Academic Writing: Separating Fact from Fiction
Date : Thursday, August 28, 2025
Time: 9:00 AM EDT | 1:00 PM GMT | 6:30 PM IST
Duration: 60 minutes
Registration is FREE – Click here to block your spot now!
What You Will Get
In this interactive 60-minute session, our expert panel will:
You’ll also have the opportunity to engage directly with the speakers during a live Q&A. It’s your chance to clear the air on some of academia’s most debated topics.
Sign up now for FREE – Click here to block your spot now!
Why This Session Matters
The debate around AI in academia is often filled with fear and misinformation. Paperpal’s latest survey uncovered some eye-opening insights into how academics perceive AI, revealing just how widespread the uncertainty still is:
Be a part of the conversation. Seats are limited, so take a minute now – Register for FREE!
Meet Our Speakers

Christopher Ostro
Assistant Teaching Professor and AI Strategist, CU Boulder
Chris is an experienced educator with 7+ years in teaching, writing consulting, and curriculum development across traditional, hybrid, and online formats. He mentors new and experienced teachers, helping them enhance accessibility, adapt content for diverse learners, and innovate course design to meet the evolving needs of students.

Joris van Rossum
Program Director, STM Integrity Hub
Joris van Rossum leads initiatives at STM Solutions focusing on research integrity and the application of AI in scholarly publishing. His work aims to enhance the reliability and trustworthiness of scientific literature.

Dr. Hong Zhou
Senior Director of AI Products Management, Wiley
Hong Zhou brings a strong track record of four years in AI research and 16 years of experience in technology, product, and business development. Passionate about digital transformation, he designs innovative products using emerging technologies and strategic approaches to enhance business performance and improve people’s lives. His expertise lies in defining effective processes and business models that drive growth in the digital era.
Don’t miss this chance to gain the clarity you need to navigate the grey areas and leverage AI responsibly in your research and writing – Register for free today!
As social media grows noisier, infographics in social media have become one of the most powerful ways to captivate audiences. Science communication infographics have become crucial for students and researchers aiming to break through the digital clutter and get their work seen and recognized.
A recent study by Social Media Today found that posts using visuals received 37% higher interaction than those with only text. Another interesting article by EmailAudience showed that the human brain processes images approximately 6 – 600 times faster than words. This underscores the effectiveness of social media infographics as a tool for capturing attention and delivering information instantly.
In this blog article, we’ll explore how to create impactful visuals for scientific illustrations for social media, cover which platforms work best for different types of content, and offer practical tips to get you started.
Science is complex. And while that may be necessary for publishing in journals, it’s a barrier on social media. Scientific insights are often wrapped in layers of technical language, equations, or dense datasets. The goal of science communication infographics or designing infographics for social media is to make these findings more digestible without losing the meaning.
To visualize your research effectively, start by replacing technical jargon with simple relatable metaphors. Instead of long blocks of text, convert data and tables into well-designed charts and flow diagrams using recognizable icons. When designing infographics for social media, remember that the aim is to help your audience understand “Why it matters” more than just focusing on “What it is.”
Focus on conveying your findings in digestible chunks by organizing information into smaller sections, which make it easier to read and retain. When designing infographics for social media:
Mind the Graph est un really great tool to use here. This accurate scientific illustration tool boasts of the largest library of visuals and templates across top subject areas. With detailed templates designed by experts and a simple drag-and-drop functionality, it helps you create scientific illustrations, graphical abstracts, infographics, posters, and more in minutes. Whether you’re building a CRISPR explainer or presenting climate data and trends, Mind the Graph can help you blend storytelling with powerful visuals that communicate your research effectively.
Not all platforms are created equal. To drive engagement and ensure clarity on social platforms, it’s important to be aware of their respective design formats. Here’s what you need to know when designing visuals for the top three social media for science and research.
Pro tip: Mind the Graph provides editable templates, accurate illustrations, and drag-and-drop elements making it easy to craft powerful scientific infographics. You can then quickly adjust layouts, aspect ratios, and visual emphasis as needed for different platforms, without starting from scratch.
Once your content is simplified, the next step is to present it beautifully. A strong visual aesthetic increases shareability and ensures your scientific infographic works for everyone. Consistency, clarity, and inclusivity is what differentiates a good infographic from one that actually stands out in cluttered feeds with visuals and infographics in social media.
Even the most well-structured infographic can fall flat if you make these critical blunders. The most common slip-up? Trying to say too much, too fast. Here are some mistakes to watch out for when creating science communication infographics:
Designing infographics for social media isn’t just a creative task anymore, it’s a crucial science communication skill every academic should master. Whether you’re a student showcasing their findings or a scientist presenting their work at a conference, you can amplify your message and make your work more accessible with the right visuals.
Social media for scientists is not about dumbing down concepts — it’s about making your work more visible, relatable, and understood. And with tools like Mind the Graph, which provides pre-designed templates, scientific icons, and social-media-ready formats, it’s easier and faster than ever to convey your research and boost your engagement through accurately designed scientific illustrations.