
皮尔逊相关性是一种基本的统计方法,用于了解两个连续变量之间的线性关系。通过量化这些关系的强度和方向,皮尔逊相关系数提供了广泛应用于各个领域的重要见解,包括研究、数据科学和日常决策。本文将解释皮尔逊相关性的基本原理,包括其定义、计算方法和实际应用。我们将探讨这一统计工具如何揭示数据中的模式、了解其局限性的重要性以及准确解释的最佳实践。
什么是皮尔逊相关性?
皮尔逊相关系数或皮尔逊 r 可以量化两个连续变量之间线性关系的强度和方向。范围从 -1至1该系数表示散点图中的数据点与直线的吻合程度。
- 数值为 1 意味着完全的正线性关系,即随着一个变量的增加,另一个变量也会持续增加。
- 值为 -1 表示 完美的负线性关系,其中一个变量增大,另一个变量减小。
- 值为 0 建议 无线性相关这意味着变量之间不存在线性关系。
皮尔逊相关性被广泛应用于科学、经济学和社会科学领域,以确定两个变量是否同时移动以及移动的程度。它有助于评估变量之间的关联程度,是数据分析和解释的重要工具。
如何计算皮尔逊相关系数
皮尔逊相关系数 (r) 用以下公式计算:
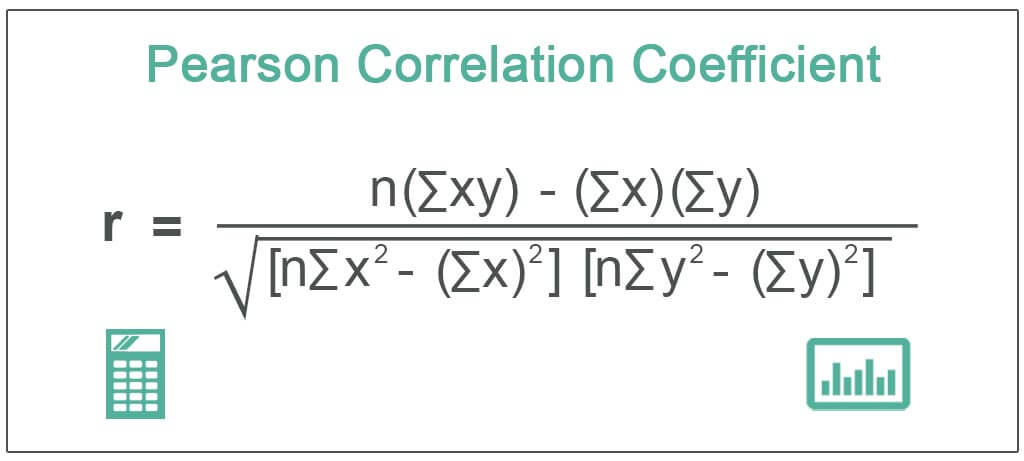
在哪里?
- x 和 y 是被比较的两个变量。
- n 是数据点的数量。
- ∑xy 的乘积之和。x 和 y).
- ∑x2 和 ∑y2 是每个变量的平方和。
逐步计算:
- 收集数据: 收集变量的配对值 x 和 y.
例子。
x=[1,2,3]
y=[4,5,6]
- 计算 x 和 y 的和:
∑x 是 x.
∑y 是 y.
例如
∑x=1+2+3=6
∑y=4+5+6=15
- 乘法 x 和 y 每对
将每对 x 值和 y 值相乘,求出 ∑xy.
xy=[1×4,2×5,3×6]=[4,10,18]
∑xy=4+10+18=32
- 每个 x 值和 y 值的平方:
求出每个 x 值和 y 值的平方,然后求和得出 ∑x2 和 ∑y2.
x2=[12,22,32]=[1,4,9]
∑x2=1+4+9=14
y2=[42,52,62]=[16,25,36]
∑y2=16+25+36=77
- 将数值输入皮尔逊公式: 现在,将这些值代入皮尔逊相关公式:
r = (n∑xy - ∑x∑y)/ √[(n∑x² - (∑x)²) * (n∑y² - (∑y)²)]
r = (3 × 32 - 6 × 15) / √[(3 × 14 - (6)²) × (3 × 77 - (15)²)]
r = (96 - 90) / √[(42 - 36) × (231 - 225)]
r = 6 / √[6 × 6]
r = 6 / 6 = 1
在这个例子中,皮尔逊相关系数为 1表明变量之间存在完美的正线性关系 x 和 y.
这种循序渐进的方法可用于任何数据集,以手动计算皮尔逊相关性。不过,像 Excel 这样的软件工具也可以、 Python对于较大型的数据集,通常可以通过软件包或统计软件包自动完成这一过程。
为什么皮尔逊相关性在统计分析中很重要?
研究方面
ǞǞǞ 皮尔逊相关性 是一种重要的研究统计工具,用于识别和量化两个连续变量之间线性关系的强度和方向。它可以帮助研究人员了解两个变量之间是否存在关联以及关联的强度,从而深入了解数据集的模式和趋势。
皮尔逊相关性可以帮助研究人员确定变量之间的关系是否一致,是正相关还是负相关。例如,在一个测量学习时间和考试成绩的数据集中,如果存在很强的正相关性,则表明学习时间的增加与考试成绩的提高有关。反之,负相关则表明随着一个变量的增加,另一个变量则会下降。
在不同研究领域的应用实例:
心理学 皮尔逊相关性通常用于探讨压力水平和认知能力等变量之间的关系。研究人员可以评估压力的增加会如何影响记忆力或解决问题的能力。
经济学 经济学家利用皮尔逊相关性研究收入与消费或通货膨胀与失业等变量之间的关系,帮助他们了解经济因素如何相互影响。
医学。 在医学研究中,皮尔逊相关性可以确定不同健康指标之间的关系。例如,研究人员可以调查血压水平与心脏病风险之间的相关性,从而帮助制定早期检测和预防保健策略。
环境科学: 皮尔逊相关性有助于探索温度和作物产量等环境变量之间的关系,使科学家能够模拟气候变化对农业的影响。
总之,皮尔逊相关性是不同研究领域的重要工具,可用于发现有意义的关系,并指导未来的研究、干预或政策决策。
在日常生活中
理解 皮尔逊相关性 这对日常决策非常有用,因为它有助于识别影响我们日常工作和选择的不同变量之间的模式和关系。
实际应用和示例:
健身与健康: 皮尔逊相关性可用于评估锻炼频率和体重减轻等不同因素之间的关系。例如,对锻炼习惯和体重进行长期跟踪可能会发现,经常参加体育锻炼和体重减轻之间存在正相关关系。
个人理财: 在预算编制中,皮尔逊相关性可以帮助分析支出习惯和储蓄之间的关系。如果有人跟踪自己的月支出和储蓄率,他们可能会发现两者之间存在负相关关系,这表明随着支出的增加,储蓄会减少。
天气与心情 相关性的另一个日常应用是了解天气对情绪的影响。例如,晴天与情绪改善之间可能存在正相关,而阴雨天则可能与精力下降或悲伤有关。
时间管理: 通过比较花在特定任务上的时间(如学习时间)和生产率或绩效结果(如成绩或工作效率),皮尔逊相关性可以帮助个人了解时间分配如何影响结果。
在常见情况下了解相关性的好处:
改进决策: 了解变量之间的联系可以让个人做出明智的决定。例如,了解饮食与健康之间的相关性可以帮助人们养成更好的饮食习惯,促进身心健康。
优化成果: 人们可以利用相关性来优化自己的作息时间,比如发现睡眠时间与工作效率的相关性,并相应地调整睡眠时间,以最大限度地提高效率。
识别模式: 认识到日常活动的模式(如屏幕时间与眼睛疲劳之间的相关性)可以帮助个人改变行为,减少负面影响,提高整体生活质量。
在日常生活中应用皮尔逊相关性的概念,可以让人们深入了解日常活动的不同方面是如何相互作用的,从而使他们能够做出积极主动的选择,增进健康、财务和福祉。
解读皮尔逊相关性
价值和意义
ǞǞǞ 皮尔逊相关系数 (r) 从 -1至1每个值都能让人了解两个变量之间关系的性质和强度。了解这些值有助于解释相关性的方向和程度。
系数值:
1:值为 +1 表示 完美的正线性关系 即随着一个变量的增加,另一个变量也会完全成比例地增加。
-1:值为 -1 表示 完美的负线性关系随着一个变量的增大,另一个变量也会成正比地减小。
0:值为 0 建议 无线性关系 这意味着一个变量的变化并不能预测另一个变量的变化。
正相关、负相关和零相关:
正相关:何时 r 为正值 (例如 0.5),这意味着这两个变量趋于同方向移动。例如,随着气温的升高,冰淇淋的销量可能会增加,从而显示出正相关性。
负相关:何时 r 为负数 (例如,-0.7),则表明变量的运动方向相反。例如,运动频率与体脂百分比之间的关系是:随着运动量的增加,体脂趋于减少。
零相关性:一个 r of 0 这意味着 无明显线性关系 变量之间的线性相关。例如,鞋码与智力之间可能没有线性关系。
一般来说。
0.7 至 1 或 -0.7 至 -1 表示 坚强 相关性。
0.3 至 0.7 或 -0.3 至 -0.7 反映了 温和派 相关性。
0 至 0.3 或 -0.3 至 0 表示 孱弱 相关性。
了解了这些值,研究人员和个人就能确定两个变量之间的密切关系,以及这种关系是否重要到需要进一步关注或采取行动。
限制条件
虽然 皮尔逊相关性 是评估变量间线性关系的有力工具,但也有其局限性,并非适用于所有情况。
皮尔逊相关性可能不合适的情况:
非线性关系:皮尔逊相关性只测量 线性关系因此,在变量之间存在曲线或非线性关系的情况下,它可能无法准确反映关联的强度。例如,如果变量之间存在二次或指数关系,皮尔逊相关性可能会低估或无法反映真实的关系。
异常值:存在 异常值 (极端值)会严重扭曲皮尔逊相关性结果,误导变量之间的整体关系。一个离群值可能会人为地抬高或降低相关值。
非连续变量:皮尔逊相关法假定两个变量都是连续的正态分布。它可能不适合 专用 或 序数数据这些关系不一定是线性关系或数字关系。
异方差:当一个变量的变异性在另一个变量的变异性范围内不同时(即数据点的分布不恒定),皮尔逊相关性可能无法准确衡量两者之间的关系。这种情况称为 异方差因此,它可能会扭曲系数。
仅限于线性关系: 皮尔逊相关性具体衡量的是 "相关性 "和 "相关性 "的强度和方向。 线性关系.如果变量之间存在非线性关系,Pearson 相关性将无法检测到这一点。例如,如果一个变量相对于另一个变量的增长速度越来越快(如指数或对数关系),尽管存在很强的相关性,但皮尔逊相关性可能显示为弱相关性或零相关性。
为了解决这些局限性,研究人员可以使用其他方法,例如 斯皮尔曼等级相关性 或 非线性回归模型 以更好地捕捉复杂的关系。从本质上讲,虽然皮尔逊相关性对线性关系很有价值,但在应用时必须谨慎,确保数据符合准确解释所需的假设。
如何使用皮尔逊相关性
工具和软件
计算 皮尔逊相关性 可以手动完成,但使用统计工具和软件则更为高效实用。这些工具可以快速计算皮尔逊相关系数,处理大型数据集,并为综合分析提供额外的统计功能。有几种流行的软件和工具可用于计算皮尔逊相关性:
微软Excel:广泛使用的工具,具有计算皮尔逊相关性的内置功能,可用于基本的统计任务。
SPSS(社会科学统计软件包):这款功能强大的软件专为统计分析而设计,常用于社会科学和医学研究。
R 编程语言: R 是一种免费的开源编程语言,专门用于数据分析和统计。R 语言具有广泛的灵活性和可定制性。
Python(使用 Pandas 和 NumPy 等库):Python 是另一种功能强大的开源数据分析语言,其用户友好型库可简化皮尔逊相关性的计算。
GraphPad Prism:该软件在生物科学领域很受欢迎,提供直观的统计分析界面,包括皮尔逊相关性分析。
使用这些工具进行分析的基本指南:
Microsoft Excel:
- 将数据输入两列,每个变量一列。
- 使用内置函数 =CORREL(array1, array2) 计算两个数据集之间的皮尔逊相关性。
SPSS:
- 将数据导入 SPSS。
- 转到 分析 > 相关性 > 双变量并选择要分析的变量。
- 在相关系数选项下选择 "皮尔逊",然后点击 "确定"。
R 编程:
- 将数据以向量或数据帧的形式输入 R。
- 使用函数 cor(x, y, method = "pearson") 计算皮尔逊相关性。
Python (Pandas/NumPy):
- 使用 Pandas 加载数据
- 使用 df['variable1'].corr(df['variable2'])计算两列之间的皮尔逊相关性。
GraphPad Prism:
- 将数据输入软件
- 选择 "相关性 "分析选项,选择 "皮尔逊相关性",软件就会生成相关系数和可视散点图。
这些工具不仅能计算皮尔逊相关系数,还能提供图形输出、P 值和其他有助于解释数据的统计量。了解如何使用这些工具,就能进行高效、准确的相关分析,这对研究和数据驱动型决策至关重要。
使用皮尔逊相关性的实用技巧
计算相关性之前的数据准备和检查:
确保数据质量: 核实数据的准确性和完整性。检查并处理任何缺失值,因为它们可能会使结果出现偏差。不完整的数据可能会导致不正确的相关系数或误导性的解释。
检查线性度: 皮尔逊相关测量线性关系。计算前,请使用散点图绘制数据,以直观地评估变量之间是否存在线性关系。如果数据显示出非线性模式,请考虑使用其他方法,如斯皮尔曼秩相关或非线性回归。
验证正常性: 皮尔逊相关法假定每个变量的数据近似于正态分布。虽然它对正态性偏差有一定的稳健性,但显著偏差会影响结果的可靠性。使用直方图或正态性检验来检查数据的分布。
数据标准化: 如果变量的测量单位或尺度不同,应考虑将其标准化。尽管皮尔逊相关性本身与尺度无关,但这一步骤可确保比较不受测量尺度的影响。
解读结果时应避免的常见错误:
高估实力: 高皮尔逊相关系数并不意味着因果关系。相关性只能衡量线性关系的强度,而不能衡量一个变量是否会引起另一个变量的变化。避免仅根据相关性就得出因果关系的结论。
忽略异常值 异常值会不成比例地影响皮尔逊相关系数,从而导致误导性结果。识别并评估异常值对分析的影响。有时,移除或调整异常值可以更清晰地反映两者之间的关系。
误解零相关性: 皮尔逊相关性为零表示没有线性关系,但并不意味着完全没有关系。变量之间仍可能存在非线性关系,因此,如果怀疑存在非线性关联,请考虑使用其他统计方法。
混淆 "相关 "与 "因果": 请记住,相关性并不意味着因果关系。两个变量的相关可能是由于第三个未观测变量的影响。一定要考虑更广泛的背景,并使用其他方法来探索潜在的因果关系。
忽略样本的大小: 样本量过小会导致相关性估计值不稳定、不可靠。确保样本量足以提供可靠的相关性测量。较大的样本通常能提供更准确、更稳定的相关系数。
主要收获和考虑因素
皮尔逊相关是一种基本的统计工具,用于测量两个连续变量之间线性关系的强度和方向。它为从研究到日常生活的各个领域提供了宝贵的见解,有助于识别和量化数据中的关系。了解了如何正确计算和解释皮尔逊相关性,研究人员和个人就可以根据变量之间的关联强度做出明智的决策。
然而,认识到它的局限性,特别是它对线性关系的关注和对异常值的敏感性,是至关重要的。正确的数据准备和避免常见的误区(如混淆相关性和因果关系)对于准确分析至关重要。适当使用皮尔逊相关性并考虑其限制因素,可以让您有效地利用这一工具获得有意义的见解并做出更好的决策。
浏览 80 多个热门领域中 75,000 多幅科学准确的插图
Mind the Graph 是一款功能强大的工具,旨在帮助科学家直观地传达复杂的研究成果。通过访问 80 多个热门领域的 75,000 多幅科学准确的插图,研究人员可以轻松找到可增强其演示文稿、论文和报告效果的视觉元素。该平台的插图种类繁多,无论是生物学、化学、医学还是其他学科,都能确保科学家根据自己特定的研究领域创建清晰、引人入胜的视觉效果。这个庞大的图库不仅能节省时间,还能更有效地传播数据,让专家和普通大众都能获取和理解科学信息。


订阅我们的通讯
关于有效视觉的独家高质量内容
科学中的交流。