
Urvalstekniker är viktiga inom forskning för att välja representativa delmängder från populationer, vilket möjliggör korrekta slutsatser och tillförlitliga insikter. Den här guiden utforskar olika urvalstekniker och belyser deras processer, fördelar och bästa användningsfall för forskare. Urvalstekniker säkerställer att de insamlade uppgifterna på ett korrekt sätt återspeglar den bredare gruppens egenskaper och mångfald, vilket möjliggör giltiga slutsatser och generaliseringar.
Det finns olika urvalsmetoder, var och en med sina fördelar och nackdelar, allt från sannolikhetsurvalstekniker - som enkelt slumpmässigt urval, stratifierat urval och systematiskt urval - till icke-sannolikhetsmetoder som bekvämlighetsurval, kvoturval och snöbollsurval. Att förstå dessa tekniker och deras lämpliga tillämpningar är avgörande för forskare som vill utforma effektiva studier som ger tillförlitliga och användbara resultat. I den här artikeln går vi igenom de olika urvalsteknikerna och ger en översikt över deras processer, fördelar, utmaningar och idealiska användningsområden.
Att behärska urvalstekniker för framgångsrik forskning
Urvalstekniker är metoder som används för att välja ut delmängder av individer eller objekt från en större population, vilket säkerställer att forskningsresultaten är både tillförlitliga och tillämpliga. Dessa tekniker säkerställer att urvalet på ett korrekt sätt representerar populationen, vilket gör det möjligt för forskare att dra giltiga slutsatser och generalisera sina resultat. Valet av urvalsteknik kan ha en betydande inverkan på kvaliteten och tillförlitligheten hos de uppgifter som samlas in, liksom på det övergripande resultatet av forskningsstudien.
Provtagningstekniker kan delas in i två huvudkategorier: sannolikhetsurval och Icke-sannolikhetsurval. Det är viktigt för forskare att förstå dessa tekniker, eftersom de hjälper till att utforma studier som ger tillförlitliga och giltiga resultat. Forskare måste också ta hänsyn till faktorer som populationens storlek och mångfald, målen för deras forskning och de resurser som de har tillgängliga. Denna kunskap gör det möjligt för dem att välja den lämpligaste urvalsmetoden för sin specifika studie.
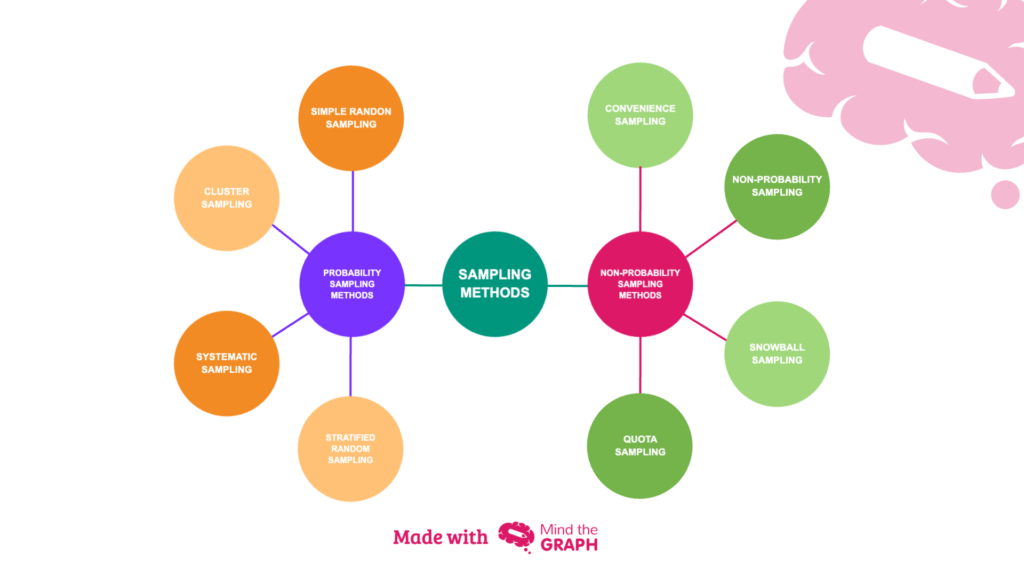
Utforska olika typer av provtagningstekniker: Sannolikhet och icke-sannolikhet
Sannolikhetsurval: Säkerställa representativitet i forskning
Sannolikhetsurval garanterar att varje individ i en population har lika stor chans att väljas ut, vilket skapar representativa och opartiska urval för tillförlitlig forskning. Denna teknik kan minska snedvridningen i urvalet och ge tillförlitliga och giltiga resultat som kan generaliseras till en bredare population. Genom att ge alla i populationen samma möjlighet att ingå ökar noggrannheten i de statistiska slutsatserna, vilket gör den idealisk för storskaliga forskningsprojekt som enkäter, kliniska prövningar eller politiska undersökningar där generaliserbarhet är ett viktigt mål. Sannolikhetsurval delas in i följande kategorier:
Enkelt slumpmässigt urval
Enkelt slumpmässigt urval (SRS) är en grundläggande sannolikhetsurvalsteknik där varje individ i populationen har en lika stor och oberoende chans att bli utvald för studien. Denna metod säkerställer rättvisa och opartiskhet, vilket gör den idealisk för forskning som syftar till att producera opartiska och representativa resultat. SRS används ofta när populationen är väldefinierad och lättillgänglig, vilket säkerställer att varje deltagare har lika stor sannolikhet att ingå i urvalet.
Steg att utföra:
Definiera populationen: Identifiera den grupp eller population från vilken urvalet ska göras och se till att den överensstämmer med forskningsmålen.
Skapa en provtagningsram: Ta fram en omfattande lista över alla medlemmar i populationen. Denna lista måste omfatta varje individ för att säkerställa att urvalet på ett korrekt sätt kan återspegla hela gruppen.
Slumpmässigt utvalda individer: Använd opartiska metoder, t.ex. en slumptalsgenerator eller ett lotterisystem, för att slumpmässigt välja ut deltagare. Detta steg säkerställer att urvalsprocessen är helt opartisk och att varje individ har lika stor sannolikhet att bli utvald.
Fördelar:
Minskar partiskhet: Eftersom varje medlem har lika stor chans att bli utvald minimerar SRS risken för snedvridning av urvalet, vilket leder till mer giltiga och tillförlitliga resultat.
Lätt att implementera: Med en väldefinierad population och en tillgänglig urvalsram är SRS enkelt och okomplicerat att genomföra och kräver minimal komplex planering eller justeringar.
Nackdelar:
Kräver en fullständig förteckning över befolkningen: En av de största utmaningarna med SRS är att den är beroende av en fullständig och korrekt förteckning över befolkningen, vilket kan vara svårt eller omöjligt att få fram i vissa studier.
Ineffektivt för stora, utspridda populationer: För stora eller geografiskt spridda populationer kan SRS vara tids- och resurskrävande, eftersom det kan krävas betydande insatser för att samla in nödvändiga uppgifter. I sådana fall kan andra urvalsmetoder, t.ex. klusterurval, vara mer praktiska.
Enkelt slumpmässigt urval (SRS) är en effektiv metod för forskare som vill få representativa urval. Dess praktiska tillämpning är dock beroende av faktorer som befolkningsstorlek, tillgänglighet och tillgången till en omfattande urvalsram. För ytterligare insikter om enkel slumpmässig provtagning kan du besöka: Mind the Graph: Enkel slumpmässig provtagning.
Klusterprovtagning
Klusterurval är en sannolikhetsurvalsteknik där hela populationen delas in i grupper eller kluster och ett slumpmässigt urval av dessa kluster väljs ut för studie. I stället för att välja ut individer från hela populationen fokuserar forskarna på ett urval av grupper (kluster), vilket ofta gör processen mer praktisk och kostnadseffektiv när det handlar om stora, geografiskt spridda populationer.

Varje kluster är avsett att fungera som en småskalig representation av den större populationen och omfattar ett varierat antal individer. Efter att ha valt ut klustren kan forskarna antingen inkludera alla individer inom de valda klustren (enstegs klusterurval) eller slumpmässigt välja ut individer inom varje kluster (tvåstegs klusterurval). Denna metod är särskilt användbar inom områden där det är svårt att studera hela befolkningen, t.ex:
Forskning om folkhälsa: Används ofta i undersökningar som kräver insamling av fältdata från olika regioner, till exempel för att studera sjukdomsprevalens eller tillgång till sjukvård i flera samhällen.
Pedagogisk forskning: Skolor eller klassrum kan behandlas som kluster när man bedömer utbildningsresultat i olika regioner.
Marknadsundersökningar: Företag använder klusterurval för att undersöka kundpreferenser på olika geografiska platser.
Forskning om myndigheter och samhälle: Används i storskaliga undersökningar som folkräkningar eller nationella undersökningar för att uppskatta demografiska eller ekonomiska förhållanden.
Proffs:
Kostnadseffektivt: Minskar kostnaderna för resor, administration och drift genom att begränsa antalet platser att studera på.
Praktiskt för stora populationer: Användbart när populationen är geografiskt utspridd eller svårtillgänglig, vilket möjliggör enklare provtagningslogistik.
Förenklar fältarbetet: Minskar den arbetsinsats som krävs för att nå ut till individer eftersom forskarna fokuserar på specifika kluster i stället för individer som är utspridda över ett stort område.
Kan rymma storskaliga studier: Idealisk för storskaliga nationella eller internationella studier där det skulle vara opraktiskt att undersöka individer i hela befolkningen.
Cons:
Högre fel i urvalet: Kluster kanske inte representerar befolkningen lika bra som ett enkelt slumpmässigt urval, vilket leder till snedvridna resultat om klustren inte är tillräckligt olika.
Risk för homogenitet: När klustren är för enhetliga minskar urvalets förmåga att representera hela populationen på ett korrekt sätt.
Komplexitet i design: Kräver noggrann planering för att säkerställa att kluster definieras och provtas på lämpligt sätt.
Lägre precision: Resultaten kan ha lägre statistisk precision jämfört med andra urvalsmetoder, t.ex. enkla slumpmässiga urval, vilket kräver större urvalsstorlekar för att uppnå korrekta skattningar.
För mer information om klusterprovtagning, besök: Scribbr: Klusterprovtagning.
Stratifierat urval
Stratifierat urval är en sannolikhetsurvalsmetod som ökar representativiteten genom att dela in populationen i olika undergrupper, eller strata, baserat på en specifik egenskap som ålder, inkomst, utbildningsnivå eller geografiskt läge. När populationen har delats in i dessa strata dras ett urval från varje grupp. Detta säkerställer att alla viktiga undergrupper är tillräckligt representerade i det slutliga urvalet, vilket gör det särskilt användbart när forskaren vill kontrollera för specifika variabler eller säkerställa att studiens resultat är tillämpliga på alla befolkningssegment.
Process:
Identifiera de relevanta stratumen: Bestäm vilka egenskaper eller variabler som är mest relevanta för forskningen. I en studie om konsumentbeteende kan strata till exempel baseras på inkomstnivåer eller åldersgrupper.
Dela upp befolkningen i strata: Kategorisera hela populationen i undergrupper som inte överlappar varandra med hjälp av de identifierade egenskaperna. Varje individ får bara passa in i ett stratum för att bibehålla tydlighet och precision.
Välj ett urval från varje stratum: Från varje stratum kan forskaren antingen göra ett proportionellt urval (i linje med befolkningsfördelningen) eller ett jämlikt urval (oavsett stratumets storlek). Proportionellt urval är vanligt när forskaren vill återspegla den faktiska befolkningssammansättningen, medan lika urval används när man vill ha en balanserad representation av olika grupper.
Fördelar:
Säkerställer att alla viktiga undergrupper är representerade: Genom att göra urval från varje stratum i ett stratifierat urval minskar sannolikheten för att mindre grupper eller minoritetsgrupper underrepresenteras. Detta tillvägagångssätt är särskilt effektivt när specifika undergrupper är avgörande för forskningsmålen, vilket leder till mer exakta och inkluderande resultat.
Minskar variabiliteten: Stratifierat urval gör det möjligt för forskare att kontrollera vissa variabler, t.ex. ålder eller inkomst, vilket minskar variationen inom urvalet och förbättrar precisionen i resultaten. Detta gör det särskilt användbart när det finns en känd heterogenitet i populationen baserad på specifika faktorer.
Scenarier för användning:
Stratifierad provtagning är särskilt värdefull när forskare behöver säkerställa att specifika undergrupper är lika eller proportionellt representerade. Det används ofta i marknadsundersökningar, där företag kan behöva förstå beteenden i olika demografiska grupper, till exempel ålder, kön eller inkomst. På samma sätt kräver utbildningstester ofta stratifierade urval för att jämföra prestationer mellan olika skoltyper, årskurser eller socioekonomiska bakgrunder. Inom folkhälsoforskning är denna metod avgörande när man studerar sjukdomar eller hälsoutfall i olika demografiska segment, för att säkerställa att det slutliga urvalet exakt speglar den totala befolkningens mångfald.
Systematiskt urval
Systematiskt urval är en sannolikhetsurvalsmetod där individer väljs ut från en population med regelbundna, förutbestämda intervall. Det är ett effektivt alternativ till enkla slumpmässiga urval, särskilt när det handlar om stora populationer eller när det finns en fullständig befolkningslista. Att välja ut deltagare med fasta intervall förenklar datainsamlingen och minskar tidsåtgången och arbetsinsatsen samtidigt som slumpmässigheten bibehålls. Det krävs dock noggrann uppmärksamhet för att undvika potentiella snedvridningar om det finns dolda mönster i befolkningslistan som stämmer överens med urvalsintervallen.
Hur man implementerar:
Bestäm population och urvalsstorlek: Börja med att identifiera det totala antalet individer i populationen och bestäm den önskade urvalsstorleken. Detta är avgörande för att bestämma provtagningsintervallet.
Beräkna samplingsintervallet: Dividera populationens storlek med urvalets storlek för att fastställa intervallet (n). Om populationen t.ex. är 1 000 personer och du behöver ett urval på 100 personer blir ditt urvalsintervall 10, vilket innebär att du väljer var tionde individ.
Välj slumpmässigt en startpunkt: Använd en slumpmetod (t.ex. en slumptalsgenerator) för att välja en startpunkt inom det första intervallet. Från denna startpunkt kommer var n:te individ att väljas ut enligt det tidigare beräknade intervallet.
Potentiella utmaningar:
Risk för periodicitet: En stor risk med systematiskt urval är risken för snedvridning på grund av periodicitet i befolkningsförteckningen. Om listan har ett återkommande mönster som sammanfaller med urvalsintervallet kan vissa typer av individer vara över- eller underrepresenterade i urvalet. Om till exempel var tionde person på listan delar en viss egenskap (som att tillhöra samma avdelning eller klass) kan det snedvrida resultaten.
Att ta itu med utmaningar: För att minska risken för periodicitet är det viktigt att randomisera startpunkten för att införa ett element av slumpmässighet i urvalsprocessen. Dessutom kan en noggrann utvärdering av befolkningslistan för att upptäcka eventuella underliggande mönster innan urvalet genomförs bidra till att förhindra partiskhet. I de fall där populationslistan har potentiella mönster kan stratifierade eller slumpmässiga urval vara bättre alternativ.
Systematiskt urval är fördelaktigt på grund av sin enkelhet och snabbhet, särskilt när man arbetar med ordnade listor, men det kräver uppmärksamhet på detaljer för att undvika partiskhet, vilket gör det idealiskt för studier där populationen är ganska enhetlig eller periodicitet kan kontrolleras.
Icke-sannolikhetsurval: Praktiska metoder för snabba insikter
Icke-sannolikhetsurval innebär att individer väljs ut baserat på tillgänglighet eller bedömning, vilket erbjuder praktiska lösningar för explorativ forskning trots begränsad generaliserbarhet. Detta tillvägagångssätt används ofta i explorativ forskning, där syftet är att samla in inledande insikter snarare än att generalisera resultaten till hela populationen. Det är särskilt praktiskt i situationer med begränsad tid, resurser eller tillgång till hela populationen, till exempel i pilotstudier eller kvalitativ forskning, där representativt urval kanske inte är nödvändigt.
Bekvämlighetsurval
Bekvämlighetsurval är en icke-sannolikhetsurvalsmetod där individer väljs ut baserat på deras lättillgänglighet och närhet till forskaren. Den används ofta när målet är att samla in data snabbt och billigt, särskilt i situationer där andra urvalsmetoder kan vara alltför tidskrävande eller opraktiska.
Deltagare i bekvämlighetsurval väljs vanligtvis för att de är lättillgängliga, till exempel studenter vid ett universitet, kunder i en butik eller personer som passerar förbi på en allmän plats. Denna teknik är särskilt användbar för preliminär forskning eller pilotstudier, där fokus ligger på att samla in inledande insikter snarare än att producera statistiskt representativa resultat.
Vanliga tillämpningar:
Bekvämlighetsurval används ofta i explorativ forskning, där forskarna vill samla in allmänna intryck eller identifiera trender utan att behöva ett mycket representativt urval. Det är också populärt i marknadsundersökningar, där företag kan vilja ha snabb feedback från tillgängliga kunder, och i pilotstudier, där syftet är att testa forskningsverktyg eller metoder innan man genomför en större, mer rigorös studie. I dessa fall gör bekvämlighetsurvalet det möjligt för forskarna att snabbt samla in data, vilket ger en grund för framtida, mer omfattande forskning.
Proffs:
Snabbt och billigt: En av de främsta fördelarna med bekvämlighetsurval är att det går snabbt och är kostnadseffektivt. Eftersom forskarna inte behöver utveckla en komplex urvalsram eller få tillgång till en stor population kan data samlas in snabbt och med minimala resurser.
Lätt att implementera: Bekvämlighetsurval är enkla att genomföra, särskilt när populationen är svårtillgänglig eller okänd. Det gör det möjligt för forskare att samla in data även när en fullständig lista över populationen inte finns tillgänglig, vilket gör det mycket praktiskt för inledande studier eller situationer där tiden är avgörande.
Cons:
Benägen att vara partisk: En av de stora nackdelarna med bekvämlighetsurval är att det är känsligt för partiskhet. Eftersom deltagarna väljs utifrån hur lättillgängliga de är, kanske urvalet inte exakt representerar den bredare populationen, vilket leder till snedvridna resultat som endast återspeglar egenskaperna hos den tillgängliga gruppen.
Begränsad generaliserbarhet: På grund av bristen på slumpmässighet och representativitet är resultaten från bekvämlighetsurval i allmänhet begränsade i sin förmåga att generaliseras till hela befolkningen. Denna metod kan förbise viktiga demografiska segment, vilket leder till ofullständiga eller felaktiga slutsatser om den används för studier som kräver bredare tillämpbarhet.
Även om bekvämlighetsurval inte är idealiskt för studier som syftar till statistisk generalisering, är det fortfarande ett användbart verktyg för utforskande forskning, hypotesgenerering och situationer där praktiska begränsningar gör andra urvalsmetoder svåra att genomföra.
Kvotsampling
Kvotering är en icke-sannolikhetsurvalsteknik där deltagarna väljs ut för att uppfylla fördefinierade kvoter som återspeglar specifika egenskaper hos populationen, till exempel kön, ålder, etnicitet eller yrke. Denna metod säkerställer att det slutliga urvalet har samma fördelning av viktiga egenskaper som den population som studeras, vilket gör det mer representativt jämfört med metoder som bekvämlighetsurval. Kvotering används ofta när forskare behöver kontrollera representationen av vissa undergrupper i sin studie men inte kan förlita sig på slumpmässiga urvalsmetoder på grund av resurs- eller tidsbegränsningar.
Steg för att fastställa kvoter:
Identifiera viktiga egenskaper: Det första steget i ett kvoturval är att fastställa de väsentliga egenskaper som ska återspeglas i urvalet. Dessa egenskaper omfattar vanligtvis demografiska uppgifter som ålder, kön, etnicitet, utbildningsnivå eller inkomstgrupp, beroende på studiens fokus.
Fastställ kvoter baserade på befolkningsandelar: När de viktigaste egenskaperna har identifierats fastställs kvoter baserat på deras andelar i populationen. Om till exempel 60% av befolkningen är kvinnor och 40% är män, skulle forskaren fastställa kvoter för att säkerställa att dessa proportioner bibehålls i urvalet. Detta steg säkerställer att urvalet speglar populationen när det gäller de valda variablerna.
Välj deltagare för att fylla varje kvot: Efter att ha fastställt kvoter väljs deltagare ut för att uppfylla dessa kvoter, ofta genom bekvämlighet eller bedömande urval. Forskarna kan välja personer som är lättillgängliga eller som de tror bäst representerar varje kvot. Även om dessa urvalsmetoder inte är slumpmässiga säkerställer de att urvalet uppfyller den önskade fördelningen av egenskaper.
Överväganden för tillförlitlighet:
Säkerställa att kvoterna återspeglar korrekta befolkningsdata: Tillförlitligheten i kvoturval beror på hur väl de fastställda kvoterna återspeglar den verkliga fördelningen av egenskaper i populationen. Forskare måste använda korrekta och uppdaterade uppgifter om befolkningens demografi för att fastställa de korrekta proportionerna för varje egenskap. Felaktiga uppgifter kan leda till snedvridna eller icke-representativa resultat.
Använd objektiva kriterier för urval av deltagare: För att minimera snedvridningen i urvalet måste objektiva kriterier användas vid valet av deltagare inom varje kvot. Om bekvämlighetsurval eller bedömningsurval används bör man se till att undvika alltför subjektiva val som kan snedvrida urvalet. Att använda sig av tydliga och konsekventa riktlinjer för att välja ut deltagare inom varje undergrupp kan bidra till att öka resultatens validitet och tillförlitlighet.
Kvotering är särskilt användbart inom marknadsundersökningar, opinionsundersökningar och social forskning, där det är viktigt att kontrollera för specifika demografiska förhållanden. Även om det inte använder slumpmässigt urval, vilket gör det mer benäget för urvalsbias, är det ett praktiskt sätt att säkerställa representationen av viktiga undergrupper när tid, resurser eller tillgång till befolkningen är begränsad.
Snöbollsurval
Snöbollsurval är en icke-sannolikhetsteknik som ofta används i kvalitativ forskning, där nuvarande deltagare rekryterar framtida försökspersoner från sina sociala nätverk. Denna metod är särskilt användbar för att nå dolda eller svåråtkomliga grupper, till exempel narkotikamissbrukare eller marginaliserade grupper, som kan vara svåra att involvera genom traditionella urvalsmetoder. Genom att utnyttja de första deltagarnas sociala kontakter kan forskare samla in insikter från individer med liknande egenskaper eller erfarenheter.
Scenarier för användning:
Denna teknik är användbar i olika sammanhang, särskilt när man utforskar komplexa sociala fenomen eller samlar in djupgående kvalitativa data. Snöbollsurval gör det möjligt för forskare att utnyttja relationer i samhället, vilket underlättar en rikare förståelse av gruppdynamiken. Det kan påskynda rekryteringen och uppmuntra deltagarna att diskutera känsliga ämnen mer öppet, vilket gör det värdefullt för utforskande forskning eller pilotstudier.
Potentiella fördomar och strategier för att minska dem
Även om snöbollsurvalet ger värdefulla insikter kan det också medföra felaktigheter, särskilt när det gäller urvalets homogenitet. Att förlita sig på deltagarnas nätverk kan leda till ett urval som inte på ett korrekt sätt representerar den bredare populationen. För att hantera denna risk kan forskare diversifiera den ursprungliga deltagarpoolen och fastställa tydliga inklusionskriterier, vilket förbättrar urvalets representativitet samtidigt som de drar nytta av metodens styrkor.
Om du vill veta mer om snöbollsprovtagning, besök Mind the Graph: Snöbollsurval.
Att välja rätt provtagningsteknik
Att välja rätt urvalsteknik är avgörande för att få fram tillförlitliga och giltiga forskningsresultat. En viktig faktor att ta hänsyn till är populationens storlek och mångfald. Större och mer heterogena populationer kräver ofta sannolikhetsurvalsmetoder som enkel slumpmässig eller stratifierad provtagning för att säkerställa att alla undergrupper är tillräckligt representerade. I mindre eller mer homogena populationer kan icke-sannolikhetsurvalsmetoder vara effektiva och mer resurseffektiva, eftersom de ändå kan fånga den nödvändiga variationen utan omfattande insatser.
Forskningens mål och syften spelar också en avgörande roll när det gäller att bestämma urvalsmetoden. Om målet är att generalisera resultaten till en bredare population är sannolikhetsurval vanligtvis att föredra eftersom det möjliggör statistiska slutsatser. För explorativ eller kvalitativ forskning, där syftet är att samla in specifika insikter snarare än breda generaliseringar, kan dock icke-sannolikhetsurval, såsom bekvämlighetsurval eller målinriktat urval, vara lämpligare. Genom att anpassa urvalstekniken till forskningens övergripande mål säkerställs att de uppgifter som samlas in uppfyller studiens behov.
Resurs- och tidsbegränsningar bör tas med i beräkningen när man väljer urvalsteknik. Sannolikhetsurvalsmetoder är visserligen mer grundliga, men kräver ofta mer tid, ansträngning och budget på grund av att de kräver en omfattande urvalsram och randomiseringsprocesser. Icke-sannolikhetsmetoder är å andra sidan snabbare och mer kostnadseffektiva, vilket gör dem idealiska för studier med begränsade resurser. Att balansera dessa praktiska begränsningar med forskningens mål och populationens egenskaper hjälper till att välja den lämpligaste och mest effektiva urvalsmetoden.
Mer information om hur du väljer den lämpligaste urvalsmetoden för forskning finns på Mind the Graph: Olika typer av provtagning.
Hybrida urvalsmetoder
Hybridurvalsmetoder kombinerar element från både sannolikhetsurval och icke-sannolikhetsurval för att uppnå mer effektiva och skräddarsydda resultat. Genom att blanda olika metoder kan forskarna ta itu med specifika utmaningar i sin studie, till exempel att säkerställa representativitet samtidigt som de tar hänsyn till praktiska begränsningar som begränsad tid eller begränsade resurser. Dessa tillvägagångssätt ger flexibilitet, vilket gör att forskarna kan utnyttja styrkorna i varje urvalsteknik och skapa en effektivare process som uppfyller de unika kraven i deras studie.
Ett vanligt exempel på en hybridmetod är stratifierat slumpmässigt urval kombinerat med bekvämlighetsurval. I den här metoden delas befolkningen först in i olika strata baserat på relevanta egenskaper (t.ex. ålder, inkomst eller region) med hjälp av stratifierat slumpmässigt urval. Därefter används bekvämlighetsurval inom varje stratum för att snabbt välja ut deltagare, vilket effektiviserar datainsamlingsprocessen samtidigt som det säkerställs att viktiga undergrupper är representerade. Denna metod är särskilt användbar när populationen är diversifierad men forskningen måste genomföras inom en begränsad tidsram.
Letar du efter siffror för att kommunicera vetenskap?
Mind the Graph är en innovativ plattform som är utformad för att hjälpa forskare att effektivt kommunicera sin forskning med hjälp av visuellt tilltalande figurer och grafik. Om du letar efter figurer för att förbättra dina vetenskapliga presentationer, publikationer eller utbildningsmaterial erbjuder Mind the Graph en rad verktyg som förenklar skapandet av högkvalitativa bilder.
Med det intuitiva gränssnittet kan forskare enkelt anpassa mallar för att illustrera komplexa koncept, vilket gör vetenskaplig information mer tillgänglig för en bredare publik. Genom att utnyttja kraften i det visuella kan forskare öka tydligheten i sina resultat, förbättra publikens engagemang och främja en djupare förståelse för sitt arbete. Sammantaget gör Mind the Graph det möjligt för forskare att kommunicera sin vetenskap mer effektivt, vilket gör det till ett viktigt verktyg för vetenskaplig kommunikation.

Prenumerera på vårt nyhetsbrev
Exklusivt innehåll av hög kvalitet om effektiv visuell
kommunikation inom vetenskap.